
Rozdíly mezi vědci dat a strojovým učením
Data Scientist je odborník odpovědný za sběr, zkoumání a interpretaci velkých objemů dat, aby rozpoznal způsoby, jak podnikům pomoci zlepšit operace a získat životaschopnou výhodu nad soupeři. Vychází z interdisciplinárního přístupu. Spočívá mezi propojením matematiky, statistiky, softwarového inženýrství, umělé inteligence a designového myšlení. Zabývá se sběrem dat, čištěním, analýzou, vizualizací, validačním modelem, predikcí experimentů, navrhováním, testováním a hypotézami. Strojové učení je rozdělení umělé inteligence, které využívá věda o údajích k dosažení svých cílů. Strojové učení se zaměřuje především na algoritmy, polynomiální struktury a přidávání slov. Skládá se ze skupiny algoritmů, strojů a umožňuje jim učit se, aniž by na to byly jasně naprogramovány.
Data Scientist
Tato role Data Scientist je odvětvím role statistik, které zahrnuje použití pokročilých verzí analytických technologií, včetně strojového učení a prediktivního modelování, k poskytování vizí nad rámec statistické analýzy. Petice za dovednosti v oblasti vědy o datu v posledních letech výrazně vzrostla, protože společnosti se snaží shromažďovat užitečné informace z obrovského množství strukturovaných, polostrukturovaných a nestrukturovaných dat, které velký podnik vytváří a souhrnně označované jako velká data. Cílem všech kroků je pouze odvodit poznatky z dat.
Standardní úkoly:
- Přiřadit, agregovat a syntetizovat data z různých strukturovaných a nestrukturovaných zdrojů
- Prozkoumejte, rozvíjejte a aplikujte inteligentní učení na reálná data, poskytujte na nich důležitá zjištění a úspěšné akce
- Analyzujte a poskytujte údaje shromážděné v organizaci
- Navrhujte a vytvářejte nové procesy pro modelování, těžbu a implementaci dat
- Vývoj prototypů, algoritmů, prediktivních modelů, prototypů
- Provádějte žádosti o analýzu dat a sdělujte svá zjištění a rozhodnutí
Kromě toho existují specifičtější úkoly v závislosti na doméně, v níž zaměstnavatel pracuje nebo je projekt prováděn.
Nezpracovaná data -> Věda o údajích ->> Insightable Insights
Strojové učení
Pozice Technika strojového učení je více „technická“. ML Engineer má více společného s klasickým softwarovým inženýrstvím než Data Scientist. Pomáhá vám naučit se objektivní funkci, která vykresluje vstupy do cílové proměnné a / nebo nezávislé proměnné do závislých proměnných.
Standardní úkoly ML Engineer jsou obecně jako Data Scientist. Musíte také být schopni pracovat s daty, experimentovat s různými algoritmy Machine Learning, které vyřeší úkol, vytvoří prototypy a hotová řešení.
Požadované znalosti a dovednosti pro tuto pozici se také překrývají s Data Scientistem. Z klíčových rozdílů bych vybral:
- Silné programovací dovednosti v jednom nebo více populárních jazycích (obvykle Python a Java), jakož i v databázích;
- Menší důraz na schopnost pracovat v prostředích pro analýzu dat, ale větší důraz na algoritmy strojového učení;
- R a Python pro modelování jsou výhodnější než Matlab, SPSS a SAS;
- Schopnost používat hotové knihovny pro různé zásobníky v aplikaci, například Mahout, Lucene pro Javu, NumPy / SciPy pro Python;
- Schopnost vytvářet distribuované aplikace pomocí Hadoop a dalších řešení.
Jak vidíte, pozice ML Engineer (nebo užší) vyžaduje více znalostí v softwarovém inženýrství, a proto je dobře vhodná pro zkušené vývojáře. Poměrně často případ funguje, když obvyklý vývojář musí vyřešit úkol ML pro svou povinnost a začne chápat nezbytné algoritmy a knihovny.
Srovnání hlava-hlava mezi vědcem dat a strojovým učením
Níže je pět nejvýznamnějších rozdílů mezi inženýry datových vědců a strojového učení 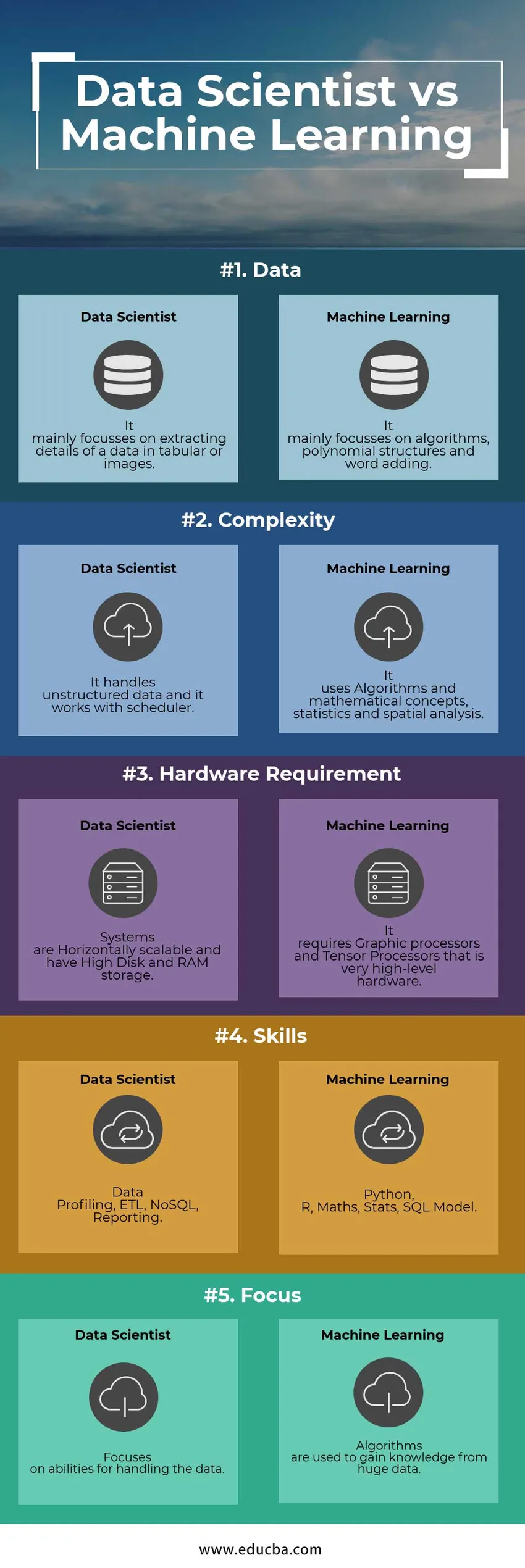
Klíčový rozdíl mezi datovým vědcem a strojovým učením
Níže jsou uvedeny seznamy bodů, popište klíčové rozdíly mezi technikem Data Scientist vs. Machine Learning
- Strojové učení a statistika jsou součástí datové vědy. Slovo učení ve strojovém učení znamená, že algoritmy závisí na některých datech, používaných jako tréninková sada, pro jemné doladění některých parametrů modelu nebo algoritmu. To zahrnuje mnoho technik, jako je regrese, naivní Bayes nebo kontrolované shlukování. Ale ne všechny techniky se hodí do této kategorie. Například klastrování bez dozoru - statistická a datová věda - se zaměřuje na detekci shluků a klastrových struktur bez předchozí znalosti nebo školení, které by pomohly klasifikačnímu algoritmu. K označení nalezených shluků je zapotřebí lidská bytost. Některé techniky jsou hybridní, například klasifikace s polovičním dozorem. Do této kategorie spadají některé techniky detekce vzorů nebo odhadu hustoty.
- Datová věda je však mnohem víc než strojové učení. Data ve vědě o údajích mohou nebo nemusí pocházet ze stroje nebo mechanického procesu (údaje z průzkumu by mohly být shromažďovány ručně, klinická hodnocení zahrnují specifický typ malých dat) a nemusí mít nic společného s učením, jak jsem právě diskutoval. Hlavním rozdílem je však skutečnost, že věda o údajích pokrývá celé spektrum zpracování dat, nejen algoritmické nebo statistické aspekty. Věda o datech také zahrnuje integraci dat, distribuovanou architekturu, automatizované strojové učení, vizualizaci dat, dashboardy a techniku velkých dat.
Tabulka pro porovnání datových vědců a strojů
Následuje seznam bodů, popište srovnání mezi technikem Data Scientist vs Machine Learning:
| Vlastnosti | Data Scientist | Strojové učení |
| Data | Zaměřuje se především na extrahování podrobností dat v tabulkách nebo obrázcích | Zaměřuje se především na algoritmy, polynomiální struktury a přidávání slov |
| Složitost | Zpracovává nestrukturovaná data a pracuje s plánovačem | Využívá algoritmy a matematické pojmy, statistiky a prostorovou analýzu |
| Hardwarový požadavek | Systémy jsou horizontálně škálovatelné a mají vysoký diskový a RAM úložný prostor | Vyžaduje grafické procesory a tenzorové procesory, což je hardware na vysoké úrovni |
| Dovednosti | Profilování dat, ETL, NoSQL, Reporting | Python, R, matematika, statistika, SQL model |
| Soustředit se | Zaměřuje se na schopnosti zpracování dat | Algoritmy se používají k získání znalostí z obrovských dat |
Závěr - Data Scientist vs Machine Learning
Strojové učení vám pomůže naučit se objektivní funkci, která vykresluje vstupy do cílové proměnné a / nebo nezávislé proměnné do závislých proměnných
Vědec údajů provádí mnoho průzkumů dat a dospěje k široké strategii, jak je řešit. Je zodpovědný za kladení otázek uvnitř dat a za nalezení odpovědí, které lze z údajů přiměřeně vyvodit. Funkce inženýrství patří do oblasti Data Scientist. Role zde hraje také kreativita a technik strojového učení zná více nástrojů a může sestavovat modely podle sady funkcí a dat - podle pokynů od Data Scientist. Oblast předzpracování dat a extrakce funkcí patří inženýrovi ML.
Věda o údajích a vyšetření využívají strojové učení pro tento druh archetypální validace a tvorby. Je důležité si uvědomit, že všechny algoritmy v tomto modelu tvorby nemusí pocházet ze strojového učení. Mohou přijít z mnoha jiných oborů. Model si přeje být vždy relevantní. Pokud se situace změní, pak se model, který jsme vytvořili dříve, může stát nepodstatným. Požadavky modelu musí být zkontrolovány z důvodu své jistoty v různých časech a je třeba je upravit, pokud se jeho jistota sníží.
Data science je celá velká doména. Pokusíme-li se to dát do potrubí, mělo by to sběr dat, ukládání dat, předzpracování dat nebo čištění dat, vzorce učení v datech (pomocí strojového učení), pomocí učení pro předpovědi. Toto je jeden způsob, jak pochopit, jak strojové učení zapadá do vědy o datech.
Doporučený článek
Byl to průvodce rozdíly mezi technikem Data Scientist vs Machine Learning, jejich významem, porovnáváním hlava-hlava, klíčovými rozdíly, srovnávací tabulkou a závěrem. Další informace naleznete také v následujících článcích -
- Dolování dat vs Strojové učení - 10 nejlepších věcí, které potřebujete vědět
- Strojové učení vs prediktivní analýza - 7 užitečných rozdílů
- Data Scientist vs Business Analyst - Zjistěte 5 úžasných rozdílů
- Data Scientist vs Data Engineer - 7 úžasných srovnání
- Dotazy na softwarové inženýrství | Nejlepší a nejžádanější