
Rozdíl mezi strojovým učením a prediktivní analýzou
Strojové učení je oblastí v oblasti informatiky, která v současnosti roste a je vázána. Nedávný pokrok v hardwarových technologiích, který vyústil v masivní nárůst výpočetní síly, jako je GPU (grafické procesorové jednotky) a pokrok v neuronových sítích, se strojové učení stalo bzučivým slovem. V zásadě můžeme pomocí technik strojového učení sestavit algoritmy pro extrahování dat a vidět z nich důležité skryté informace. Prediktivní analytika je také součástí domény strojového učení, která je omezena na předpovídání budoucího výsledku z dat založených na předchozích vzorcích. Přestože se prediktivní analytika používá již více než dvě desetiletí hlavně v bankovnictví a finančním sektoru, aplikace strojového učení v poslední době zaujímá význam v algoritmech, jako je detekce objektů z obrázků, klasifikace textu a systémy doporučení.
Strojové učení
Strojové učení interně využívá statistik, matematiky a základů informatiky k vytváření logiky pro algoritmy, které dokážou provádět klasifikaci, predikci a optimalizaci v reálném čase i v dávkovém režimu. Klasifikace a regrese jsou dvě hlavní třídy problému v rámci strojového učení. Pojďme podrobně porozumět jak strojovému učení, tak prediktivní analýze.
Klasifikace
V těchto skupinách problému máme sklon klasifikovat objekt na základě jeho různých vlastností do jedné nebo více tříd. Například klasifikace bankovního klienta tak, aby byl způsobilý pro úvěr na bydlení nebo nebyl založen na jeho úvěrové historii. Obvykle bychom měli k dispozici transakční data pro zákazníka, jako je jeho věk, příjem, vzdělání, jeho pracovní zkušenosti, odvětví, ve kterém pracuje, počet závislých osob, měsíční výdaje, předchozí půjčky, pokud existují, jeho způsob utrácení, úvěrová historie atd. … a na základě těchto informací bychom měli tendenci počítat, zda by mu měl být poskytnut úvěr nebo ne.
Existuje mnoho standardních algoritmů strojového učení, které se používají k vyřešení klasifikačního problému. Logistická regrese je jednou z takových metod, pravděpodobně nejrozšířenější a nejznámější, také nejstarší. Kromě toho máme také nejpokročilejší a nejkomplikovanější modely od rozhodovacího stromu po náhodný les, AdaBoost, XP boost, podporu vektorových strojů, naivní baize a neuronové sítě. Od posledních několika let probíhá hluboké učení v popředí. Pro klasifikaci obrázků se obvykle používá neuronová síť a hluboké učení. Pokud existuje sto tisíc obrázků koček a psů a chcete napsat kód, který dokáže automaticky oddělit obrazy koček a psů, možná budete chtít jít za metodami hlubokého učení, jako je konvoluční neuronová síť. Pochodeň, kavárna, tok senzorů atd. Jsou některé z populárních knihoven v Pythonu, které umožňují hluboké učení.
K měření přesnosti regresních modelů se používají metriky jako falešně pozitivní frekvence, falešně negativní frekvence, citlivost atd.
Regrese
Regrese je další třídou problémů ve strojovém učení, kde se na rozdíl od klasifikačních problémů snažíme předpovídat kontinuální hodnotu proměnné místo třídy. Regresní techniky se obvykle používají k předpovídání ceny akcií akcie, prodejní ceny domu nebo automobilu, poptávky po určité položce atd. Když se do hry dostanou také vlastnosti časových řad, je regresní problémy velmi zajímavé vyřešit. Lineární regrese s obyčejným nejméně čtvercem je jedním z klasických algoritmů strojového učení v této doméně. Pro vzor založený na časové řadě se používá ARIMA, exponenciální klouzavý průměr, vážený klouzavý průměr a jednoduchý klouzavý průměr.
K měření přesnosti regresních modelů se používají metriky jako střední chyba chyby, absolutní střední chyba chyby, chyba odmocniny a podobně.
Prediktivní analýza
Existuje několik oblastí překrývání mezi strojovým učením a prediktivní analýzou. Zatímco běžné techniky, jako je logistická a lineární regrese, spadají pod strojové učení i prediktivní analýzu, pokročilé algoritmy jako strom rozhodování, náhodný les atd. Jsou v podstatě strojovým učením. Podle prediktivní analytiky zůstává cíl problémů velmi úzký, pokud je záměrem spočítat hodnotu konkrétní proměnné v budoucnu. Prediktivní analytika je zatížena statistikami, zatímco strojové učení je spíš směsí statistik, programování a matematiky. Typický prediktivní analytik tráví svůj čas výpočtem t čtverečních, f statistik, Innova, chi-square nebo obyčejných nejméně čtverců. Otázky jako je to, zda jsou data normálně distribuována nebo zkosená, pokud by se mělo použít rozložení studenta nebo by se měla použít křivka zvonu, měla by se alfa pokládat vždy po 5% nebo 10%. V detailech hledají ďábla. Strojový inženýr se neobtěžuje s mnoha z těchto problémů. Jejich bolest hlavy je úplně jiná, ocitají se přilepeni na zlepšení přesnosti, falešně pozitivní minimalizaci rychlosti, odlehlé manipulaci, normalizaci rozsahu nebo k násobném ověření.
Prediktivní analytik většinou používá nástroje, jako je Excel. Scénář nebo cíl hledání jsou jejich oblíbené. Občas používají VBA nebo mikroskop a těžko zapisují zdlouhavý kód. Strojový inženýr tráví celý svůj čas psaní komplikovaného kódu nad rámec běžného porozumění, používá nástroje jako R, Python, Saas. Programování je jejich hlavní prací, opravou chyb a testováním různých krajin každý den.
Tyto rozdíly také přinášejí velký rozdíl v jejich poptávce a platu. Zatímco prediktivní analytici jsou tak včera, strojové učení je budoucnost. Typický strojový učící se technik nebo datový vědec (jak se v dnešní době většinou říká) je o 60 až 80% vyšší než běžný softwarový inženýr nebo prediktivní analytik a jsou klíčovým ovladačem v dnešním technologicky podporovaném světě. Uber, Amazon a nyní autosedačky jsou také možné pouze kvůli nim.
Porovnání hlava-hlava mezi strojovým učením a prediktivní analýzou (infografika)
Níže je prvních 7 srovnání mezi Machine Learning vs Predictive Analytics
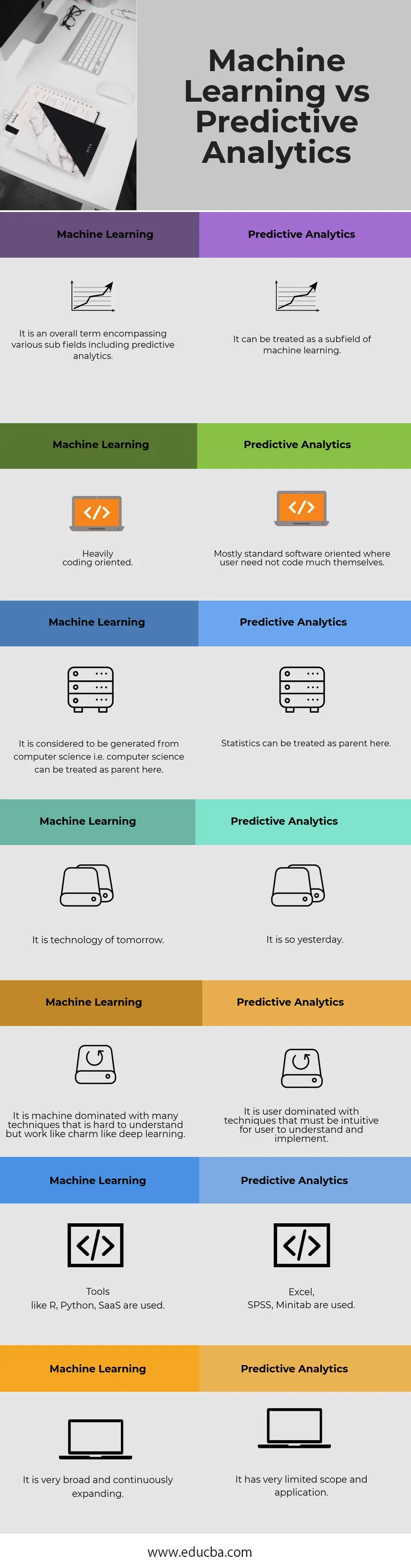
Strojové učení vs prediktivní srovnávací tabulka Analytics
Níže je uvedeno podrobné vysvětlení Machine Learning vs Predictive Analytics
| Strojové učení | Prediktivní analýza |
| Je to celkový termín zahrnující různá podpole včetně prediktivní analýzy. | Může být považováno za podpole strojového učení. |
| Silně orientované na kódování. | Většinou standardní softwarově orientovaný, kde uživatel nemusí kódovat příliš sám |
| To je považováno za vytvořené z informatiky, tj. S počítačovou vědou se dá zacházet jako s rodičem. | Statistiky lze zde považovat za rodiče. |
| Je to technologie zítřka. | Je to včera. |
| Je to stroj, kterému dominuje mnoho technik, které jsou těžko pochopitelné, ale fungují jako kouzlo jako hluboké učení. | Uživateli dominují techniky, které musí být intuitivní, aby je uživatel pochopil a implementoval. |
| Používají se nástroje jako R, Python, SaaS. | Používají se Excel, SPSS, Minitab. |
| Je velmi široký a neustále se rozšiřuje. | Má velmi omezený rozsah a použití. |
Závěr - Machine Learning vs Predictive Analytics
Z výše uvedené diskuse o strojovém učení a prediktivní analýze je zřejmé, že prediktivní analytika je v podstatě dílčím oborem strojového učení. Strojové učení je všestrannější a dokáže řešit celou řadu problémů.
Doporučený článek
Toto byl průvodce strojovým učením vs prediktivní analýzou, jejich významem, porovnáním hlava-hlava, klíčovými rozdíly, srovnávací tabulkou a závěrem. Další informace naleznete také v následujících článcích -
- Naučte se Big Data Vs Machine Learning
- Rozdíl mezi Data Science vs Machine Learning
- Porovnání prediktivní analýzy s datovou vědou
- Data Analytics Vs Predictive Analytics - Který z nich je užitečný