
Úvod do pytlování a posilování
Bagging a Boosting jsou dvě populární metody Ensemble. Takže dříve, než pochopíme, Bagging a Boosting, pojďme si udělat představu o tom, co je soubor Learning. Je to technika, která používá několik algoritmů učení k trénování modelů se stejným datovým souborem, aby se získala predikce ve strojovém učení. Po získání predikce z každého modelu použijeme techniky průměrování modelu, jako je vážený průměr, rozptyl nebo maximální hlasování, abychom získali konečnou předpověď. Cílem této metody je získat lepší předpovědi než individuální model. To má za následek vyšší přesnost vyhýbání se nadměrnému přizpůsobení a snižuje zkreslení a vzájemnou odchylku. Dvě populární metody souboru jsou:
- Bagging (Bootstrap Agregating)
- Posílení
Pytlování:
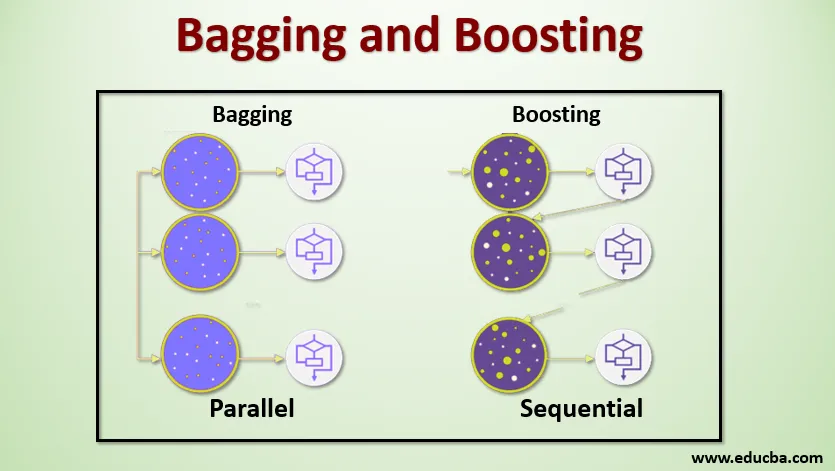
Bagging, také známý jako Bootstrap Aggregating, se používá ke zlepšení přesnosti a činí model obecnějším zredukováním rozptylu, tj. Tím, že se vyhnete přeplnění. V tomto bereme několik podskupin datového souboru školení. Pro každou podmnožinu bereme model se stejnými algoritmy učení, jako je rozhodovací strom, logistická regrese atd., Abychom předpovídali výstup pro stejnou sadu testovacích dat. Jakmile máme predikci z každého modelu, pak použijeme techniku průměrování modelu pro získání konečného výstupu predikce. Jednou ze slavných technik používaných v Baggingu je Random Forest . V doménové struktuře Random používáme více rozhodovacích stromů.
Podpora :
Zesílení se primárně používá ke snížení zaujatosti a rozptylu v dohlížecí technikě učení. Jedná se o rodinu algoritmu, který převádí slabé studenty (základní studenty) na silné studenty. Slabým studentem jsou klasifikátory, které jsou správné pouze do malé míry se skutečnou klasifikací, zatímco silní studenti jsou klasifikátory, které dobře korelují se skutečnou klasifikací. Jen málo slavných technik Boostingu je AdaBoost, GRADIENT BOOSTING, XgBOOST (Extreme Gradient Boosting). Takže nyní víme, jaké jsou pytlování a posilování a jaké jsou jejich role ve strojovém učení.
Zpracování pytlování a zvyšování
Nyní pojďme pochopit, jak funguje pytlování a podpora:
Pytlování
Abychom pochopili fungování Baggingu, předpokládejme, že máme N počet modelů a Dataset D. Kde m je počet dat an je počet funkcí v každém datu. A máme dělat binární klasifikaci. Nejprve rozdělíme dataset. Prozatím rozdělíme tento dataset pouze do tréninkové a testovací sady. Nazvěme soubor údajů o školení, kde je celkový počet příkladů školení.
Vezměte vzorek záznamů z tréninkové sady a použijte jej k tréninku prvního modelu, který říká m1. U dalšího modelu m2 převzoruje tréninkovou sadu a odebere další vzorek z tréninkové sady. Uděláme to samé pro počet modelů N. Vzhledem k tomu, že převracíme datový soubor školení a odebíráme z něj vzorky, aniž bychom z něj něco odstranili, je možné, že máme dva nebo více záznamů výcvikových dat, které jsou společné pro více vzorků. Tato technika převzorkování souboru údajů o školení a poskytnutí vzorku modelu se nazývá vzorkování řádků s nahrazením. Předpokládejme, že jsme vyškolili každý model a nyní chceme vidět předpověď na testovacích datech. Protože pracujeme na binárním klasifikačním výstupu, může být buď 0 nebo 1. Zkušební datový soubor je předán každému modelu a dostáváme predikci od každého modelu. Řekněme, že z N modelů více než N / 2 modely předpovídaly, že bude 1, proto pomocí techniky průměrování modelu, jako je maximální hlas, můžeme říci, že předpokládaný výstup pro testovací data je 1.
Posílení
Při posilování bereme záznamy z datového souboru a předáváme jej postupně studentům základní, zde mohou být základními studenty jakýkoli model. Předpokládejme, že máme v datovém souboru m počet záznamů. Pak předáme několik záznamů základním studentům BL1 a zaškolíme je. Jakmile se BL1 vyškolí, předáme všechny záznamy z datového souboru a uvidíme, jak žák základní školy pracuje. U všech záznamů, které jsou základním studentem klasifikovány nesprávně, bereme je pouze a předáváme je jinému základnímu studentovi říkat BL2 a současně předáváme nesprávné záznamy klasifikované BL2 pro trénink BL3. To bude pokračovat, dokud a dokud nezadáme určitý počet základních modelů žáků, které potřebujeme. Nakonec zkombinujeme výstup těchto základních studentů a vytvoříme silného studenta, v důsledku toho se predikční síla modelu zlepší. OK. Takže nyní víme, jak funguje Bagging a Boosting.
Výhody a nevýhody pytlování a zvyšování
Níže jsou uvedeny hlavní výhody a nevýhody.
Výhody pytlování
- Největší výhodou pytlování je, že více slabých studentů může pracovat lépe než jeden silný student.
- Poskytuje stabilitu a zvyšuje přesnost algoritmu strojového učení, který se používá ve statistické klasifikaci a regresi.
- Pomáhá při snižování rozptylu, tj. Zabraňuje přeplnění.
Nevýhody pytlování
- Pokud není správně modelováno, může to vést k vysokému zkreslení, což může vést k nedostatečnému přizpůsobení.
- Protože musíme použít více modelů, stává se to výpočetně nákladným a nemusí být vhodné v různých případech použití.
Výhody zvýšení
- Je to jedna z nejúspěšnějších technik při řešení dvou třídních klasifikačních problémů.
- Je dobré zpracovat chybějící data.
Nevýhody Boostingu
- Zvýšení složitosti algoritmu je obtížné implementovat v reálném čase.
- Vysoká flexibilita těchto technik má za následek větší počet parametrů, než má přímý vliv na chování modelu.
Závěr
Hlavním důvodem je to, že Bagging a Boosting jsou paradigma strojového učení, ve kterém používáme několik modelů k vyřešení stejného problému a lepšímu výkonu. Pokud správně kombinujeme slabé studenty, můžeme získat stabilní, přesný a robustní model. V tomto článku jsem uvedl základní přehled o pytlování a posilování. V následujících článcích se seznámíte s různými technikami používanými v obou. Nakonec vám na závěr připomenu, že Bagging a Boosting patří mezi nejpoužívanější techniky kompletního učení. Skutečné umění zlepšování výkonu spočívá ve vašem porozumění, kdy použít který model a jak vyladit hyperparametry.
Doporučené články
Toto je průvodce Bagging a Boosting. Zde diskutujeme Úvod do pytlování a zvyšování a pracuje to společně s výhodami a nevýhodami. Další informace naleznete také v dalších navrhovaných článcích -
- Úvod do souboru technik
- Kategorie algoritmů strojového učení
- Algoritmus přechodu s přechodem pomocí vzorového kódu
- Co je to Boosting Algorithm?
- Jak vytvořit rozhodovací strom?