

Rozdíl mezi těžbou dat a těžbou webu
Dolování dat : Jedná se o koncept identifikace významného vzorce z dat, který dává lepší výsledek. Identifikace vzorů odkud? Z dat generovaných ze systémů.
Web mining : Proces provádění dolování dat na webu se nazývá Web mining. Extrakce webových dokumentů a objevování vzorů z nich.
Příklad: Techniky použité pro prediktivní analýzu. (Předpověď počasí na základě identifikace vzorů z historických dat)
Umožňuje nám pochopit hlavní rozdíl mezi dolováním dat a dolováním webu podrobně v tomto příspěvku.
Analogie
Zlato se vyrábí procesem zvaným těžba zlata. Je extrahován a rafinován z rudy. Konečným výsledkem těžby zlata je drahý kov. Rovněž,
Pro získání klíčových informací (dat, která stojí za to) ze surového zdroje se používá technika dolování dat. Zde je vzorec objevený ze zdroje surových dat považován za cenný pro analytika / vědce dat, aby bylo možné pokračovat v rozhodování, které ovlivňuje obchodní hodnotu.
Dolování dat
Zjednodušeně řečeno, těžba dat je koncept znalostí o těžbě z různých sad dat. Získané znalosti se dále používají k poskytování předpovědí nebo doporučení. Data, která mají být těžena, jsou k dispozici buď v datovém skladu nebo v jiných externích systémech. Data mohou být k dispozici v různých tabulkách s různými chování nebo atributy. Aby bylo možné určit vzorec, musí být identifikována korelace mezi více sadami dat.
Kroky v těžbě dat
Vzhledem k tomu, že dolování dat je abstraktní, je zde uveden seznam kroků,
- Příprava dat
- Hledání vzorů
- Sestavte modely, které chcete předpovědět / doporučit (abychom zmínili několik případů)
- Shrnutí hodnoty modelu
Web mining
Web mining je abstrakt, protože existují tři různé typy technik těžby.
- Těžba webového obsahu
- Těžba struktury webu
- Těžba využití webu
Webové třídy těžby informací shromažďování 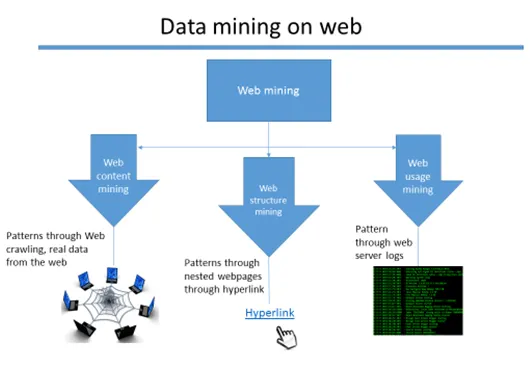
Těžba webového obsahu
Data z webových stránek jsou extrahována za účelem objevení různých vzorců, které poskytují významné informace. Existuje mnoho technik extrakce dat, jako je webový škrabání (například - scrapy a Octoparse jsou známé nástroje, které provádějí proces těžby webového obsahu.
Jeden z nejlepších příkladů - Za účelem provedení akce nebo jakéhokoli programu, nejprve analyzujte organizaci o místech (které místo je pro provádění programu nejvhodnější, aby byla zajištěna plná účast). Aby bylo možné provést tyto analýzy, je třeba shromáždit informace o konkrétním místě o městě, státě a o tom, jak daleko se událost od pozvaného nachází. Z webu lze extrahovat jakákoli data pro konkrétní lokalitu. Tam přichází dolování těžba webového obsahu.
Těžba webových struktur
Data z hypertextových odkazů, které vedou na různé stránky, se shromažďují a připravují za účelem nalezení vzoru. Aby bylo možné zobrazit veřejný profil osoby z blogu nebo jiné webové stránky, existuje šance, že vloží své odkazy na sociální média. Data tedy nejsou extrahována pouze z jediného zdroje, ale také z vnořených stránek pomocí hypertextových odkazů přiřazených ke každé stránce. K provedení tohoto úkolu existují různé algoritmy. (Příklad: Algoritmus PageRank)
Těžba využití webu:
Když je webová aplikace hostována, existuje spousta protokolů webového serveru, které jsou generovány o webové aktivitě uživatele aplikace. Tyto protokoly jsou považovány za nezpracovaná data, na oplátku jsou extrahovány smysluplné údaje a identifikovány vzory.
Například v případě jakéhokoli podnikání v oblasti elektronického obchodování, kdy chtějí zvýšit rozsah podnikání nebo přidat vylepšení pro lepší zážitek se zákazníkem, je monitorována webová aktivita uživatele prostřednictvím protokolů aplikací a je na něj aplikována dolování dat.
Web mining a data mining jsou víceméně podobné techniky, ale web mining je jen o analýze na webu. Dolování dat se neomezuje pouze na web. Jedná se o tradiční proces, který probíhá pro jakoukoli analytiku dat.
Když už mluvíme o datech z webu, existují různé údaje, které lze pozorovat. Mohla by to být strukturovaná data (databázová data jsou stahována přes API, pokud jsou zveřejněna). Polostrukturovaná data - tahají se jakékoli webové aktivity nebo dokonce protokoly serverů. Nebo dokonce nestrukturovaná data, jako jsou obrázky atd. (Pokud se na obrázcích provádí nějaká analýza)
Srovnání mezi hlavami a hlavami mezi dolováním dat a dolováním na webu (infografika)
Níže je uvedeno Top 7 Porovnání mezi těžbou dat a těžbou webu

Klíčové rozdíly mezi těžbou dat a těžbou webu
Následuje rozdíl mezi dolováním dat a dolováním webu
Web mining a data mining jsou téměř podobné, pokud jde o identifikaci vzorů. Ale kde a jaký je rozdíl v těžbě webu od těžby dat. Z jakých dat a dat se čerpá odkud? To jsou dva konečné aspekty, které přinášejí rozdíl mezi dolováním dat a dolováním na webu.
Těžba webu spadá do těžby dat, ale to je omezeno na data související s webem a identifikace vzorců. Dolování dat je rozsáhlý koncept, který zahrnuje několik kroků od přípravy dat až po ověření konečných výsledků, které vedou k procesu rozhodování organizace.
Srovnávací tabulka těžby dat vs webové těžby
| Základ pro srovnání | Dolování dat | Web mining |
| Pojem | Identifikace vzoru z dat dostupných ve všech systémech. | Identifikace vzoru z webových dat. |
| Případy aplikace / použití | Předpověď počasí pomocí historických zpráv o počasí | Procházení dat Techniky HITS / PageRank |
| Kdo to dělá? | Vědci dat Datoví inženýři | Datoví vědci / Analytici dat Datoví inženýři |
| Proces | Extrakce dat -> Zjišťování vzorů -> Rozvinout / vyřešit objekt (Algoritmus) | Stejný postup, ale na webu pomocí webových dokumentů |
| Nástroje | Algoritmy strojového učení | Útržkovitý, PageRank, Protokoly Apache |
| Jak významné | Mnoho organizací se při rozhodování spoléhá na výsledky vědecké práce s údaji. | Načtení dat souvisejících s webem by ovlivnilo existující proces dolování dat. |
| Dovednosti | Techniky čištění dat, algoritmy strojového učení, statistika, pravděpodobnost | Znalosti na úrovni aplikace, Datové inženýrství, statistika, pravděpodobnost |
Závěr - dolování dat vs. dolování na webu
Jakékoli těžební techniky s údaji mají objevit znalosti a jak dobře by mohly být použity k dosažení lepších výsledků. Organizace, které mají zájem o posílení svých podniků a dosahují vysokého zisku, potřebují mnoho rozhodnutí, aby učinily rozhodnutí na základě údajů, které jsou z velké části k dispozici v jejich systémech generovaných ve velkém množství. Ne všechna data se považují za informace, které poskytují znalosti a poznatky. Které, proč a jaké jsou hlavní otázky, na které vědci / analytici údajů musí myslet, když se připravují na identifikaci vzorců. Ve velmi laikovém termínu je těžba dat jako proces víření mléka při výrobě másla.
Doporučený článek
Toto byl průvodce těžbou dat vs. těžbou webu, jejich významem, srovnáváním mezi hlavami, klíčovými rozdíly, srovnávací tabulkou a závěrem. Další informace naleznete také v následujících článcích -
- Statistiky těžby dat - která z nich je lepší
- 10 výkonných kroků k efektivnímu plánování webdesignu
- Dolování dat vs Strojové učení - 10 nejlepších věcí, které potřebujete vědět
- Nejlepší 3 věci, které byste se měli dozvědět o těžbě dat vs těžbě textu
- Nástroje a techniky používané v procesu dolování dat