

Úvod do funkce Hashing v C
Tento článek obsahuje krátkou poznámku o hašování (hashovací tabulka a hashovací funkce). Nejdůležitějším konceptem je „vyhledávání“, které určuje časovou složitost. Aby se snížila časová složitost než jakýkoli jiný koncept datové struktury, zavádí se hashovací koncept, který má v průměrném případě O (1) čas a v nejhorším případě bude trvat O (n) čas.
Hashing je technika s rychlejším přístupem k prvkům, které mapují daná data s menším klíčem pro srovnání. Obecně v této technice jsou klíče sledovány pomocí hashovací funkce do tabulky známé jako hashovací tabulka.
Co je Hash funkce?
Hašovací funkce je funkce, která používá operaci konstantního času k uložení a načtení hodnoty z hašovací tabulky, která se aplikuje na klíče jako celá čísla, a to se používá jako adresa pro hodnoty v hašovací tabulce.
Typy hashovací funkce
Níže jsou vysvětleny typy hashovacích funkcí:
1. Metoda dělení
V této metodě je hašovací funkce závislá na zbytku dělení.
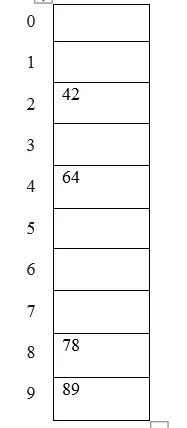
Příklad: prvky, které mají být vloženy do hashovací tabulky, jsou 42, 78, 89, 64 a vezměme velikost tabulky jako 10.
Hash (key) = Elements% size table;
2 = 42% 10;
8 = 78% 10;
9 = 89% 10;
4 = 64% 10;
Znázornění tabulky lze vidět takto:
2. Metoda Mid Square
V této metodě je střední část čtvercového prvku brána jako index.
Prvky, které mají být umístěny do hashovací tabulky, jsou 210, 350, 99, 890 a velikost tabulky je 100.
210 * 210 = 44100, index = 1 jako střední část výsledku (44100) je 1.
350 * 350 = 122500, index = 25 jako střední část výsledku (122500) je 25.
99 * 99 = 9801, index = 80, protože střední část výsledku (9801) je 80.
890 * 890 = 792100, index = 21 jako střední část výsledku (792100) je 21.
3. Metoda skládání číslic
V této metodě je prvkem, který má být umístěn do tabulky, zpívat hashovací klíč, který je získán rozdělením prvků do různých částí a poté je spojen provedením jednoduchých matematických operací.
Prvky, které mají být umístěny, jsou 23576623, 34687734.
- hash (klíč) = 235 + 766 + 23 = 1024
- hash klíč) = 34 + 68 + 77 + 34 = 213
U těchto typů hašování předpokládáme, že máme čísla od 1 do 100 a velikost hashovací tabulky = 10. Prvky = 23, 12, 32
Hash (klíč) = 23% 10 = 3;
Hash (klíč) = 12% 10 = 2;
Hash (klíč) = 32% 10 = 2;
Z výše uvedeného příkladu si všimněte, že oba prvky 12 a 32 ukazují na druhé místo v tabulce, kde není možné psát oba na stejném místě, je takový problém známý jako kolize. Chcete-li se vyhnout tomuto druhu problémů, existují některé techniky hašovacích funkcí, které lze použít.
Typy technik řešení kolizí
Pojďme diskutovat o typech technik řešení kolizí:
1. Řetězení
V této metodě, jak název napovídá, poskytuje řetězec polí pro záznam v tabulce, který má dvě položky prvků. Takže kdykoli dojde k takovým srážkám, budou pole fungovat jako propojený seznam.
Příklad: 23, 12, 32 s velikostí stolu 10.
Hash (klíč) = 23% 10 = 3;
Hash (klíč) = 12% 10 = 2;
Hash (klíč) = 32% 10 = 2;
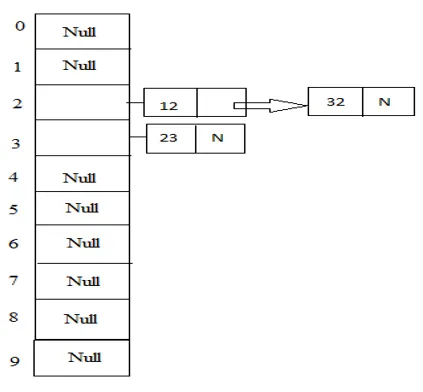
2. Otevřete Addressing
- Lineární sonda
Toto je další metoda řešení problémů s kolizí. Jak název říká, kdykoli dojde ke kolizi, měly by být dva prvky umístěny na stejný záznam v tabulce, ale touto metodou můžeme hledat další prázdné místo nebo záznam v tabulce a umístit druhý prvek. To může opět vést k dalšímu problému; pokud v tabulce nenájdeme žádný prázdný záznam, povede to k shlukování. Toto je známo jako problém shlukování, který lze vyřešit následující metodou.
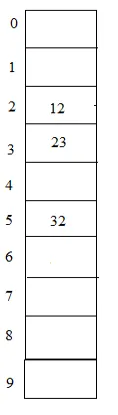
Příklad: 23, 12, 32 s velikostí stolu 10
Hash (klíč) = 23% 10 = 3;
Hash (klíč) = 12% 10 = 2;
Hash (klíč) = 32% 10 = 2;

V tomto diagramu 12 a 32 mohou být umístěny ve stejné položce s indexem 2, ale touto metodou jsou umístěny lineárně.
- Kvadratická sonda
Tato metoda je řešením problému shlukování během lineárního snímání. V této metodě se hashovací funkce s hash klíčem počítá jako hash (key) = (hash (key) + x * x)% velikost tabulky (kde x = 0, 1, 2…).
Příklad: 23, 12, 32 s velikostí stolu 10
Hash (klíč) = 23% 10 = 3;
Hash (klíč) = 12% 10 = 2;
Hash (klíč) = 32% 10 = 2;

Z toho vidíme, že 23 a 12 lze snadno umístit, ale 32 nemůže znovu a znovu 12 a 32 sdílet stejný záznam se stejným indexem v tabulce, podle této metody hash (key) = (32 + 1 * 1) % 10 = 3. Ale v tomto případě je záznam tabulky s indexem 3 umístěn s 23, takže musíme zvýšit hodnotu x o 1. Hash (klíč) = (32 + 2 * 2)% 10 = 6. Takže nyní můžeme umístit 32 v položce s indexem 6 v tabulce.
- Dvojité hašování
Tuto metodu musíme spočítat 2 hašovací funkce, abychom vyřešili problém s kolizí. První se počítá pomocí jednoduché metody dělení. Druhý musí splňovat dvě pravidla; nesmí se rovnat nule a záznamy musí být testovány.
- 1 (klíč) = klíč% velikost tabulky.
- 2 (key) = p - (key mod p), kde p je prvočísla <velikost tabulky.
Příklad: 23, 12, 32 s velikostí stolu 10
Hash (klíč) = 23% 10 = 3;
Hash (klíč) = 12% 10 = 2;
Hash (klíč) = 32% 10 = 2;
V tomto může být prvek 32 znovu umístěn pomocí hash2 (klíč) = 5 - (32% 5) = 3. Takže 32 může být umístěno do indexu 5 v tabulce, která je prázdná, protože musíme přeskočit 3 záznamy, abychom jej umístili.
Závěrečná hasicí funkce v C
Hašování je jednou z důležitých technik, pokud jde o vyhledávání dat poskytovaná pomocí velmi účinných a rychlých metod využívajících hashovací funkce a hashovací tabulky. Každý prvek lze prohledávat a umisťovat pomocí různých metod hašování. Tato technika je z hlediska časového koeficientu velmi rychlejší než jakákoli jiná struktura dat.
Doporučené články
Toto je průvodce funkcí Hašování v C. Zde diskutujeme o zavedení funkce Hašování v C, Co je to Hašovací funkce, Typy hašovacích funkcí atd. Další informace naleznete také v našich dalších navrhovaných článcích -
- Hashing v DBMS
- Proces šifrování
- Jak nainstalovat CakePHP?
- Jak Blockchain funguje
- Hashing Function v Javě
- Hashing funkce v PHP | Jak pracovat?