
Úvod do učení o posílení
Zesílení učení je druh strojového učení, a proto je také součástí umělé inteligence, když se aplikuje na systémy, systémy provádějí kroky a učí se na základě výsledků kroků k získání komplexního cíle, který je nastaven pro systém, který má dosáhnout.
Porozumět Posílení učení
Zkusme v rámci posilování učení pomocí dvou jednoduchých případů použití:
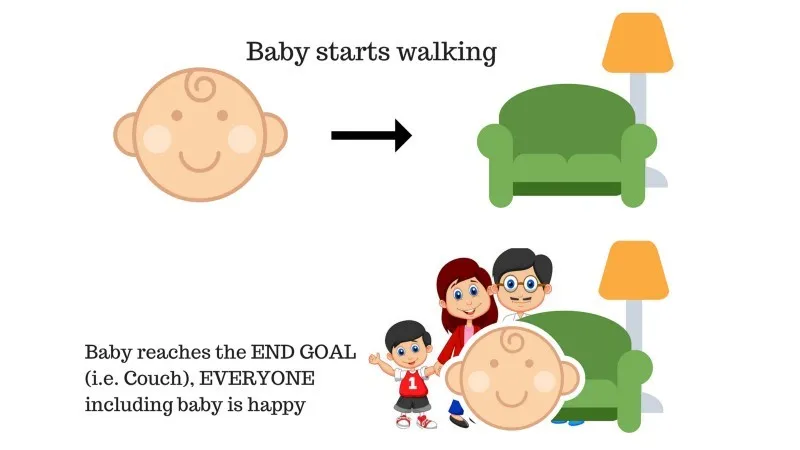
Případ č. 1
V rodině je dítě, právě začala chodit a všichni jsou z toho docela šťastní. Jednoho dne se rodiče pokusí stanovit cíl, dejte nám dítě na gauč a uvidíme, jestli to dítě dokáže.
Výsledek případu 1: Dítě úspěšně dorazí na pohovku, a proto je každý z rodiny velmi rád, že to vidí. Zvolená cesta nyní přichází s pozitivní odměnou.
Body: Odměna + (+ n) → Pozitivní odměna.
Zdroj: https://images.app.goo.gl/pGCXJ1N1bzLAer126
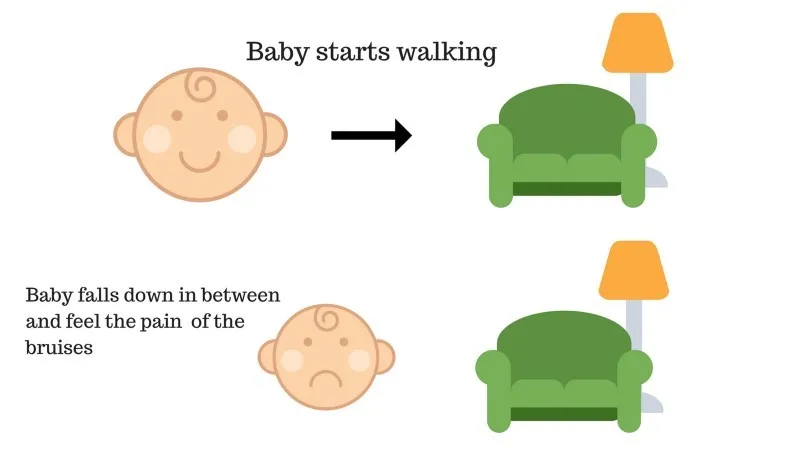
Případ č. 2
Dítě se nedostalo na gauč a dítě kleslo. To bolí! Co by mohlo být příčinou? Na cestě k gauči mohou být nějaké překážky a dítě se dostalo k překážkám.
Výsledek případu 2: Dítě padá na nějaké překážky a ona pláče! Ach, to bylo špatné, dozvěděla se, že příště se nespadne do pasti překážky. Zvolená cesta nyní přichází se zápornou odměnou.
Body: Odměny + (-n) → Záporná odměna.
Zdroj: https://images.app.goo.gl/FRfd8cUqrQRLe6sZ7
Teď jsme viděli případy 1 a 2, posilovací učení, v konceptu, dělá to samé, kromě toho, že to není člověk, ale místo toho se provádí výpočtově.
Postupné vyztužení
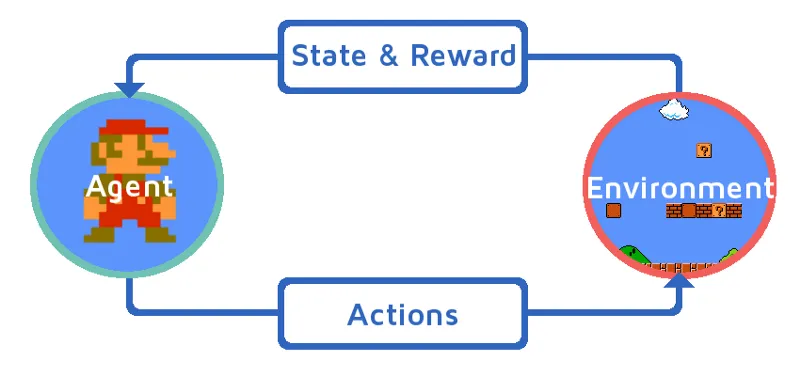
Pojďme porozumět učení posilování tím, že postupně posíláme agenta vyztužení. V tomto příkladu je naším agentem pro posilování učení Mario, který se naučí hrát samostatně:
Zdroj: https://images.app.goo.gl/Kj44uvBzWzMw1QzE9
- Aktuální stav herního prostředí Mario je S_0. Protože hra ještě nezačala a Mario je na svém místě.
- Poté se hra spustí a Mario se pohne, Mario tj. Agent RL podniká a jedná, řekněme A_0.
- Nyní je stav herního prostředí S_1.
- Také agentovi RL, tj. Mario, je nyní přidělen nějaký pozitivní odměnový bod, R_1, pravděpodobně proto, že Mario je stále naživu a nehrozilo mu žádné nebezpečí.
Nyní bude výše uvedená smyčka pokračovat, dokud Mario nebude konečně mrtvý nebo dokud Mario nedosáhne svého cíle. Tento model bude průběžně vydávat akci, odměnu a stav.
Maximalizace odměn
Cílem posilování učení je maximalizovat odměny zohledněním určitých dalších faktorů, jako je sleva na odměny; krátce vysvětlíme, co znamená sleva pomocí ilustrace.
Kumulativní vzorec pro diskontované odměny je následující:
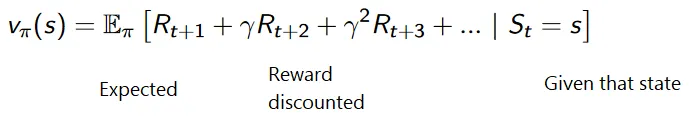
Slevové odměny
Rozumíme tomu na příkladu:
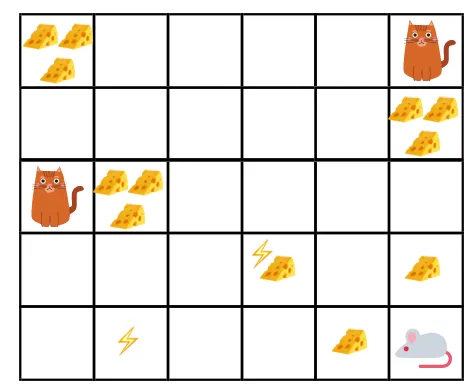
- V daném obrázku je cílem, aby myš ve hře musela jíst tolik sýra, než bude snědena kočkou nebo bez elektrošoku.
- Nyní můžeme předpokládat, že čím blíže jsme ke kočce nebo k elektrické pasti, tím větší je pravděpodobnost, že myš bude snědena nebo šokována.
- To znamená, že i když máme plný sýr v blízkosti bloku elektrického šoku nebo poblíž kočky, čím riskantnější je tam jít, je lepší jíst sýr, který je poblíž, aby se předešlo jakémukoli riziku.
- Takže i když máme jeden „blok1“ sýra, který je plný a je daleko od kočky a blok elektrického šoku a druhý „blok2“, který je také plný, ale je buď blízko kočky nebo bloku elektrického šoku, novější sýrový blok, tj. „blok2“, bude v odměnách více diskontován než ten předchozí.
Zdroj: https://images.app.goo.gl/8QrH78FjmRVs5Wxk8
Zdroj: https://cdn-images-1.medium.com/max/800/1*l8wl4hZvZAiLU56hT9vLlg.png.webp
Druhy posilování učení
Níže jsou uvedeny dva typy posilování učení s jejich výhodami a nevýhodami:
1. Pozitivní
Když je síla a frekvence chování zvýšena v důsledku výskytu určitého chování, je známá jako Pozitivní posilování učení.
Výhody: Výkon je maximalizován a změna zůstává delší dobu.
Nevýhody: Výsledky můžeme snížit, pokud máme příliš mnoho posílení.
2. Negativní
Jde o posílení chování, hlavně kvůli negativnímu pojmu.
Výhody: Zvýšené chování.
Nevýhody: Pouze minimálního chování modelu lze dosáhnout pomocí učení negativního posílení.
Kde by se mělo učení vyztužení používat?
Věci, které lze udělat pomocí učení / příkladů o posílení. Níže jsou uvedeny oblasti, ve kterých se v dnešní době používá výuka posilování:
- Zdravotní péče
- Vzdělávání
- Hry
- Počítačové vidění
- Řízení podniku
- Robotika
- Finance
- NLP (zpracování přirozeného jazyka)
- Přeprava
- Energie
Kariéra v posilování učení
Opravdu existuje zpráva ze stránky úlohy, protože RL je větev Strojového učení, podle zprávy je strojové učení nejlepší prací roku 2019. Níže je snímek zprávy. Podle současných trendů přichází Machine Learning Engineers s neuvěřitelným průměrným platem 146 085 USD as růstem 344 procent.
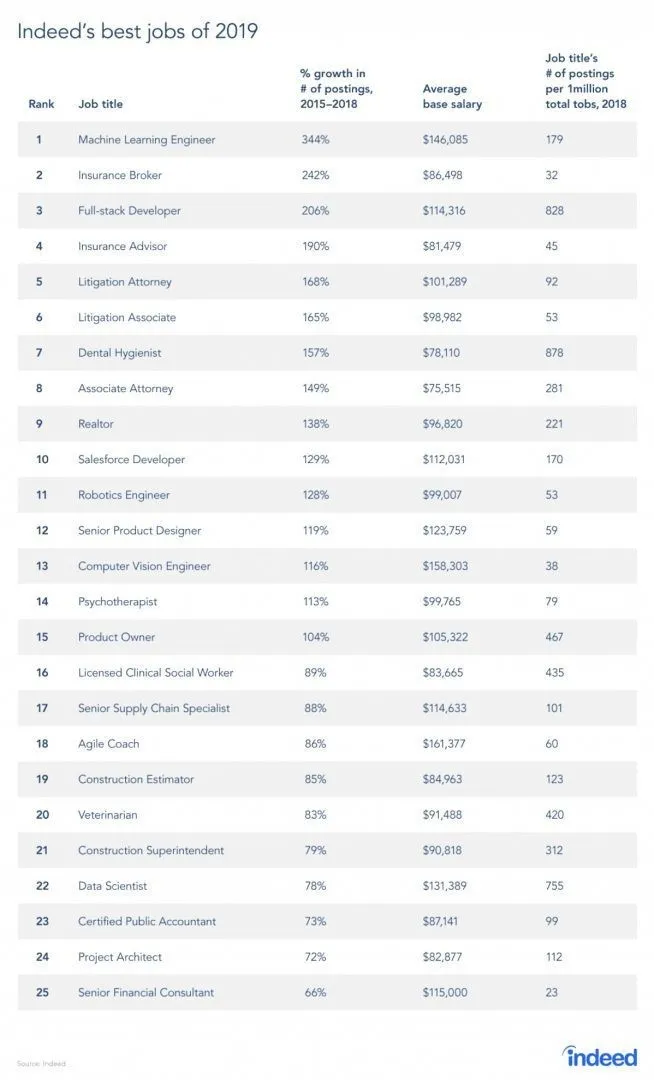
Zdroj: https://i0.wp.com/www.artificialintelligence-news.com/wp-content/uploads/2019/03/indeed-top-jobs-2019-best.jpg.webp?w=654&ssl=1
Dovednosti pro posilování učení
Níže jsou uvedeny dovednosti potřebné k posílení učení:
1. Základní dovednosti
- Pravděpodobnost
- Statistika
- Modelování dat
2. Programovací dovednosti
- Základy programování a informatiky
- Návrh softwaru
- Umí aplikovat knihovny strojového učení a algoritmy
3. Programovací jazyky pro strojové učení
- Krajta
- R
- I když existují i jiné jazyky, ve kterých lze navrhnout modely strojového učení, jako je Java, C / C ++, ale Python a R jsou nejvíce používanými jazyky.
Závěr
V tomto článku jsme začali stručným úvodem o posilovacím učení a poté jsme se hluboce ponořili do práce RL a různých faktorů, které se podílejí na práci RL modelů. Pak jsme uvedli příklady z reálného světa, abychom tomu tématu lépe porozuměli. Na konci tohoto článku by měl člověk dobře rozumět fungování posilovacího učení.
Doporučené články
Toto je průvodce „Co je to Výuka posílení“? Zde diskutujeme funkce a různé faktory, které se podílejí na vývoji modelů učení pro posílení, s příklady. Další informace naleznete také v dalších souvisejících článcích -
- Druhy algoritmů strojového učení
- Úvod do umělé inteligence
- Nástroje umělé inteligence
- Platforma IoT
- Top 6 jazykových programovacích jazyků