
Přehled algoritmů neuronové sítě
- Pojďme nejprve vědět, co znamená neuronová síť? Neuronové sítě jsou inspirovány biologickými neuronovými sítěmi v mozku nebo můžeme říci nervový systém. To vyvolalo mnoho vzrušení a výzkum stále pokračuje v této podskupině strojového učení v průmyslu.
- Základní výpočetní jednotkou neuronové sítě je neuron nebo uzel. Přijímá hodnoty od ostatních neuronů a vypočítává výstup. Každý uzel / neuron je spojen s hmotností (w). Tato hmotnost se udává podle relativní důležitosti konkrétního neuronu nebo uzlu.
- Pokud tedy vezmeme f jako funkci uzlu, pak funkce uzlu f poskytne výstup, jak je uvedeno níže: -
Výstup neuronu (Y) = f (w1.X1 + w2.X2 + b)
- Kde w1 a w2 jsou hmotnost, X1 a X2 jsou číselné vstupy, zatímco b je předpětí.
- Výše uvedená funkce f je nelineární funkce nazývaná také aktivační funkce. Jeho základním účelem je zavedení nelinearity, protože téměř všechna data ze skutečného světa jsou nelineární a chceme, aby se tyto reprezentace učily neurony.
Různé algoritmy neuronové sítě
Podívejme se nyní na čtyři různé algoritmy neuronové sítě.
1. Sjezd
Je to jeden z nejpopulárnějších optimalizačních algoritmů v oblasti strojového učení. Používá se při tréninku modelu strojového učení. Zjednodušeně řečeno, v zásadě se používá k vyhledání hodnot koeficientů, které jednoduše snižují nákladovou funkci na maximum. Nejdříve ze všeho začneme definováním některých hodnot parametrů a poté pomocí kalkulu začneme iterativně upravovat hodnoty tak, aby ztracená funkce je snížena.
Nyní pojďme k té části, co je gradient ?. Tedy gradient znamená, že se výrazně změní výstup jakékoli funkce, pokud snížíme vstup o málo nebo jinými slovy, můžeme to nazvat na svah. Pokud je sklon strmý, model se bude učit rychleji podobně model se přestane učit, když je sklon nulový. Důvodem je to, že daný algoritmus minimalizuje algoritmus minimalizace.
Pod vzorcem pro nalezení další polohy se zobrazuje v případě klesání.
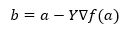
Kde b je další pozice
a je aktuální pozice, gama je funkce čekání.
Jak vidíte, klesání je velmi dobrá technika, ale v mnoha oblastech nefunguje správně. Níže jsou uvedeny některé z nich:
- Pokud algoritmus není správně proveden, můžeme se setkat s něčím, jako je problém mizejícího gradientu. K tomu dochází, když je gradient příliš malý nebo příliš velký.
- Problémy nastanou, když uspořádání dat představuje nekonvexní optimalizační problém. Přechod slušné funguje pouze s problémy, které jsou konvexně optimalizovaným problémem.
- Jedním z velmi důležitých faktorů, které je třeba při používání tohoto algoritmu hledat, jsou zdroje. Pokud máme pro aplikaci přiděleno méně paměti, měli bychom se vyhnout algoritmu sestupného gradientu.
2. Newtonova metoda
Jedná se o optimalizační algoritmus druhého řádu. Říká se tomu druhému řádu, protože využívá Hessianovu matici. Hessianova matice tedy není nic jiného než čtvercová matice parciálních derivátů funkce druhého řádu funkce skalárního významu. V Newtonově algoritmu pro optimalizaci metody se aplikuje na první derivaci dvojité diferencovatelné funkce f, takže může najít kořeny / stacionární body. Podívejme se nyní na kroky, které vyžaduje Newtonova metoda pro optimalizaci.
Nejprve vyhodnotí index ztrát. Poté zkontroluje, zda jsou kritéria zastavení pravdivá nebo nepravdivá. Pokud je nepravda, pak vypočítá Newtonův směr tréninku a rychlost tréninku a poté zlepší parametry nebo hmotnosti neuronu a znovu stejný cyklus pokračuje. Takže nyní můžete říci, že v porovnání s klesáním klesá méně kroků, abyste dosáhli minima hodnota funkce. Ačkoli to vyžaduje méně kroků ve srovnání s algoritmem sestupného klesání, stále se nepoužívá široce, protože přesný výpočet hessiana a jeho inverze je výpočetně velmi nákladný.
3. Konjugátový gradient
Je to metoda, kterou lze považovat za něco mezi gradientem sestupu a Newtonovou metodou. Hlavní rozdíl spočívá v tom, že urychluje pomalou konvergenci, kterou obvykle spojujeme s klesáním. Další důležitý fakt je, že může být použit pro lineární i nelineární systémy a je to iterační algoritmus.
Byl vyvinut Magnusem Hestenesem a Eduardem Stiefelem. Jak již bylo uvedeno výše, produkuje rychlejší konvergenci než gradient sestupu. Důvodem je to, že v algoritmu Conjugate Gradient je vyhledávání prováděno společně s konjugovanými směry, díky čemuž konverguje rychleji než algoritmy sestupového gradientu. Jedním důležitým bodem je, že γ se nazývá parametr konjugátu.
Směr tréninku je pravidelně nastaven na záporný bod gradientu. Tato metoda je při tréninku neuronové sítě účinnější než sestupový gradient, protože nevyžaduje Hessianovu matici, která zvyšuje výpočetní zatížení a také konverguje rychleji než sestupový gradient. Je vhodné použít ve velkých neuronových sítích.
4. Kvazi-Newtonova metoda
Je to alternativní přístup k Newtonově metodě, protože víme, že Newtonova metoda je výpočetně nákladná. Tato metoda řeší tyto nevýhody do té míry, že namísto výpočtu Hessianovy matice a následného výpočtu inverze přímo, tato metoda vytváří aproximaci pro inverzi Hessiana při každé iteraci tohoto algoritmu.
Nyní se tato aproximace počítá na základě informací z první derivace ztrátové funkce. Můžeme tedy říci, že je to pravděpodobně nejvhodnější metoda pro řešení velkých sítí, protože šetří čas na výpočet a také je mnohem rychlejší než metoda gradientu sestupu nebo konjugovaného gradientu.
Závěr
Předtím, než skončíme tento článek, pojďme porovnat výpočetní rychlost a paměť pro výše uvedené algoritmy. Podle požadavků na paměť vyžaduje sestupový gradient nejméně paměti a je také nejpomalejší. Na rozdíl od toho Newtonova metoda vyžaduje větší výpočetní sílu. Takže při zohlednění všech těchto je Quasi-Newtonova metoda nejvhodnější.
Doporučené články
Toto byl průvodce algoritmy neuronové sítě. Zde diskutujeme také přehled algoritmu neuronové sítě spolu se čtyřmi různými algoritmy. Další informace naleznete také v dalších navrhovaných článcích -
- Strojové učení vs neuronová síť
- Rámce strojového učení
- Neuronové sítě vs hluboké učení
- K- Znamená Clustering Algorithm
- Průvodce klasifikací neuronové sítě