
Úvod do Poissonovy regrese v R
Poissonova regrese je typ regrese, která je podobná vícenásobné lineární regresi s tou výjimkou, že odezva nebo závislá proměnná (Y) jsou počítací proměnnou. Závislá proměnná sleduje Poissonovo rozdělení. Prediktor nebo nezávislé proměnné mohou být nepřetržité nebo kategorické povahy. Svým způsobem je podobná logistické regresi, která má také diskrétní proměnnou odezvy. Předchozí pochopení Poissonovy distribuce a její matematické formy je velmi důležité, aby bylo možné ji využít k predikci. V R lze Poissonovu regresi implementovat velmi efektivním způsobem. R nabízí ucelenou sadu funkcí pro jeho implementaci.
Provádění Poissonovy regrese
Nyní začneme chápat, jak je tento model aplikován. Následující část uvádí postup stejné procedury. Pro tuto demonstraci uvažujeme o „gala“ datovém souboru z „vzdáleného“ balíčku. Týká se druhové rozmanitosti na Galapágských ostrovech. V datovém souboru je celkem 7 proměnných. Poissonovu regresi použijeme k definování vztahu mezi počtem rostlinných druhů (Druh) s jinými proměnnými v datovém souboru.
1. Nejprve vložte balíček „daleko“. V případě, že balíček není k dispozici, stáhněte jej pomocí funkce install.packages ().
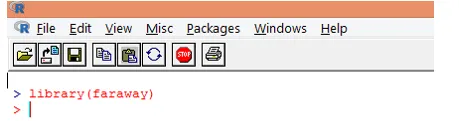
2. Po načtení balíčku načtěte „gala“ datový soubor do R pomocí funkce data (), jak je ukázáno níže.
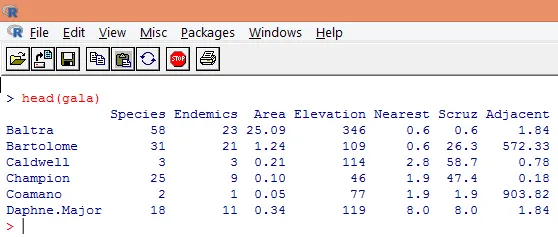
3. Načtená data by měla být vizualizována pro studium proměnné a ověření, zda existují nějaké nesrovnalosti. Pomocí funkce head (), jak je ukázáno na níže uvedeném snímku, můžeme vizualizovat buď celá data, nebo jen několik prvních řádků.
4. Chcete-li získat lepší přehled o datovém souboru, můžeme použít funkci nápovědy v R, jak je uvedeno níže. Generuje dokumentaci R, jak je ukázáno na snímku obrazovky po níže uvedeném snímku obrazovky.


5. Pokud studujeme datový soubor, jak je uvedeno v předchozích krocích, pak můžeme zjistit, že druh je proměnná odezvy. Nyní si prostudujeme základní shrnutí prediktorových proměnných.
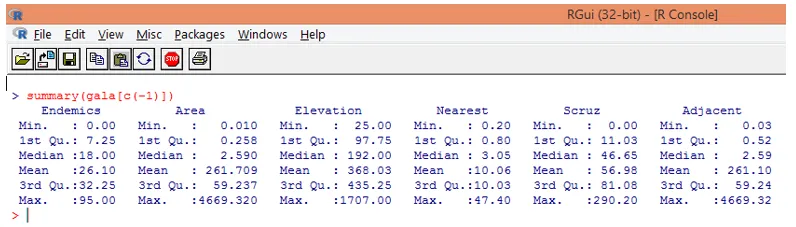
Jak je vidět výše, vyloučili jsme proměnnou Druh. Funkce shrnutí nám poskytuje základní informace. Prostě sledujte střední hodnoty pro každou z těchto proměnných a zjistíme, že mezi první polovinou a druhou polovinou existuje obrovský rozdíl, pokud jde o rozsah hodnot, např. Pro střední hodnotu proměnné Area je 2, 59, ale maximální hodnota je 4669, 320.
6. Nyní, když jsme hotovi se základní analýzou, vygenerujeme histogram pro Druh, abychom zkontrolovali, zda proměnná následuje Poissonovo rozdělení. To je ilustrováno níže.

Výše uvedený kód generuje histogram proměnné Druh spolu s křivkou hustoty nad ním.
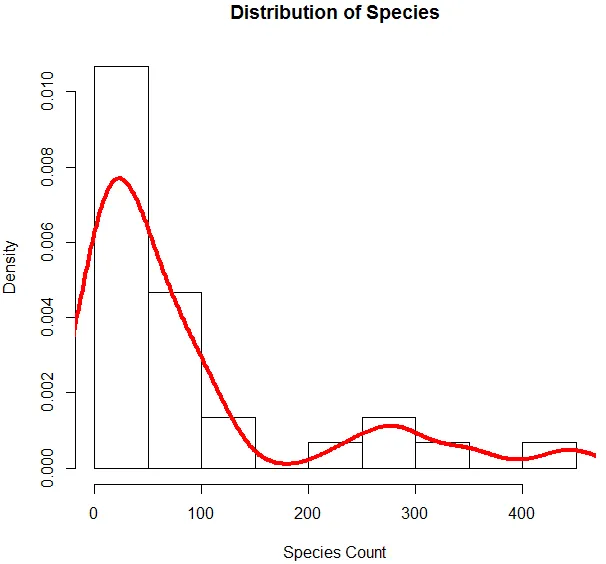
Výše uvedená vizualizace ukazuje, že Druh následuje Poissonovo rozdělení, protože data jsou zkosena doprava. Můžeme také vygenerovat krabici, abychom získali lepší přehled o distribučním vzorci, jak je ukázáno níže.
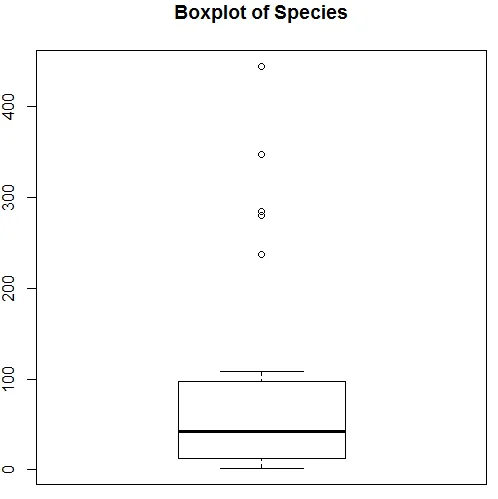
7. Po provedení předběžné analýzy nyní použijeme Poissonovu regresi, jak je ukázáno níže
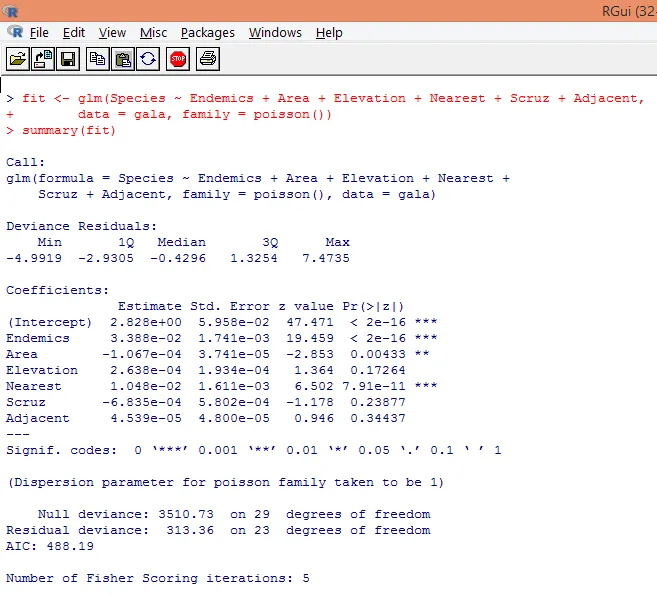
Na základě výše uvedené analýzy jsme zjistili, že proměnné Endemics, Area a Nearest jsou významné a pouze jejich zahrnutí je dostatečné k vytvoření správného Poissonova regresního modelu.
8. Postavíme upravený Poissonův regresní model, který vezme v úvahu pouze tři proměnné viz. Endemics, Area a Nearest. Uvidíme, jaké výsledky získáme.
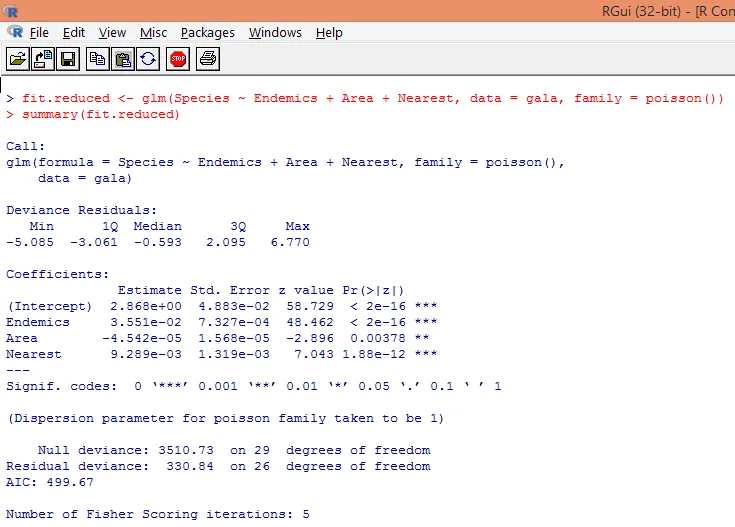
Výstup vytváří odchylky, regresní parametry a standardní chyby. Vidíme, že každý z parametrů je významný na úrovni p <0, 05.
9. Dalším krokem je interpretace parametrů modelu. Koeficienty modelu lze získat buď prozkoumáním koeficientů ve výše uvedeném výstupu nebo pomocí funkce coef ().
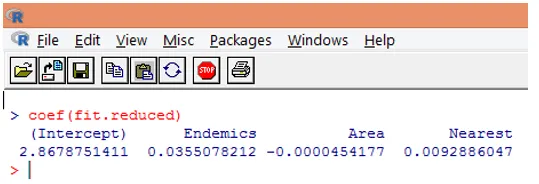
V Poissonově regresi je závislá proměnná modelována jako log podmíněného průměrného loge (l). Parametr regrese 0, 0355 pro Endemics naznačuje, že jednodílné zvýšení proměnné je spojeno se zvýšením o 0, 04 v log průměrném počtu druhů, přičemž ostatní proměnné zůstávají konstantní. Zachycení je průměrný počet druhů, když se každý z prediktorů rovná nule.
10. Je však mnohem snazší interpretovat regresní koeficienty v původní stupnici závislé proměnné (počet druhů, spíše než logové číslo druhů). Exponentiace koeficientů umožní snadnou interpretaci. To se provádí následovně.
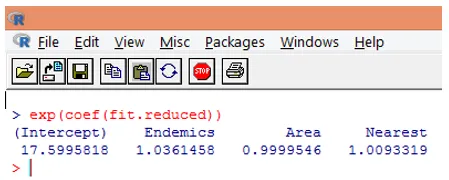
Z výše uvedených nálezů lze říci, že nárůst o jednu jednotku v ploše násobí očekávaný počet druhů o 0, 9999 a jednotkový nárůst počtu endemických druhů reprezentovaných endemiky násobí počet druhů o 1, 0361. Nejdůležitějším aspektem Poissonovy regrese je to, že exponentované parametry mají spíše multiplikační než aditivní účinek na proměnnou odezvy.
11. Pomocí výše uvedených kroků jsme získali Poissonův regresní model pro predikci počtu rostlinných druhů na Galapágských ostrovech. Je však velmi důležité zkontrolovat předávkování. V Poissonově regresi jsou rozptyl a prostředky stejné.
K nadměrné disperzi dochází, když je pozorovaná variance proměnné odezvy větší, než by bylo předpovězeno Poissonovou distribucí. Analýza nadměrné disperze je důležitá, protože je běžná u údajů o počtu a může mít negativní dopad na konečné výsledky. V R lze overdisperzi analyzovat pomocí balíčku „qcc“. Analýza je ilustrována níže.
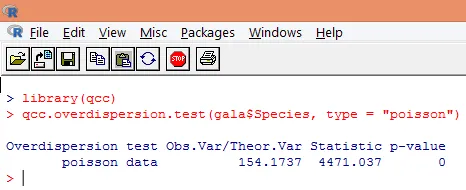
Výše uvedený významný test ukazuje, že hodnota p je menší než 0, 05, což silně naznačuje přítomnost nadměrné disperze. Pokusíme se přizpůsobit model pomocí funkce glm () nahrazením family = “Poisson” s family = “quasipoisson”. To je ilustrováno níže.
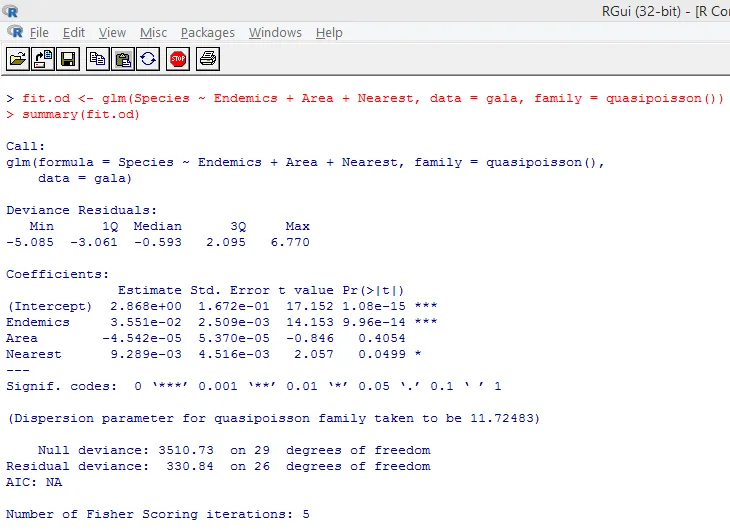
Při pečlivém studování výše uvedeného výstupu můžeme vidět, že odhady parametrů v kvazi-Poissonově přístupu jsou totožné s odhady vytvořenými Poissonovým přístupem, i když standardní chyby se u obou přístupů liší. Navíc v tomto případě je pro oblast p-hodnota větší než 0, 05, což je způsobeno větší standardní chybou.
Význam Poissonovy regrese
- Poissonova regrese v R je užitečná pro správné předpovědi diskrétní / počítací proměnné.
- Pomáhá nám identifikovat ty vysvětlující proměnné, které mají statisticky významný účinek na proměnnou odezvy.
- Poissonova regrese v R je nejvhodnější pro události „vzácné“ povahy, protože mají tendenci sledovat Poissonovo rozdělení oproti běžným událostem, které obvykle sledují normální distribuci.
- Je vhodný pro použití v případech, kdy je proměnná odezvy malé celé číslo.
- Má široké uplatnění, protože predikce diskrétních proměnných je v mnoha situacích rozhodující. V medicíně může být použit k předpovědi dopadu léku na zdraví. Používá se při analýze přežití, jako je smrt biologických organismů, selhání mechanických systémů atd.
Závěr
Poissonova regrese je založena na konceptu Poissonovy distribuce. Je to další kategorie patřící do skupiny regresních technik, která kombinuje vlastnosti lineární i logistické regrese. Na rozdíl od logistické regrese, která generuje pouze binární výstup, se však používá k predikci diskrétní proměnné.
Doporučené články
Toto je průvodce Poissonovou regresí v R. Zde diskutujeme úvodní implementaci Poissonovy regrese a význam Poissonovy regrese. Další informace naleznete také v dalších navrhovaných článcích -
- GLM v R
- Generátor náhodných čísel v R
- Regresní formule
- Logistická regrese v R
- Lineární regrese vs. logická regrese Nejlepší rozdíly