

Úvod do lineární regresní analýzy
Je často matoucí učit se nějaké koncepci, která je dokonce součástí našeho každodenního života. Ale to není problém, můžeme si pomoci a rozvíjet se, abychom se poučili z našich každodenních činností pouhým analyzováním věcí a nebojíme se kladení otázek. Proč cena ovlivňuje poptávku po zboží, proč změna úrokové sazby ovlivňuje nabídku peněz. Na všechny tyto lze odpovědět jednoduchým přístupem známým jako lineární regrese. Jediná složitost, kterou člověk cítí při řešení lineární regresní analýzy, je identifikace závislých a nezávislých proměnných.
Musíme zjistit, co ovlivňuje co, a polovina problému je vyřešena. Musíme zjistit, zda se jedná o cenu nebo poptávku, která se navzájem ovlivňuje. Jakmile jsme se dozvěděli, která z nich je nezávislá proměnná a závislá proměnná, je dobré jít do naší analýzy. K dispozici je několik typů regresní analýzy. Tato analýza závisí na proměnných, které máme k dispozici.
3 typy regresní analýzy
Tyto tři regresní analýzy mají maximální využití v reálném světě, jinak existuje více než 15 typů regresní analýzy. Druhy regresní analýzy, o nichž budeme diskutovat, jsou:
- Lineární regresní analýza
- Analýza více lineární regrese
- Logistická regrese
V tomto článku se zaměříme na jednoduchou lineární regresní analýzu. Tato analýza nám pomáhá identifikovat vztah mezi nezávislým faktorem a závislým faktorem. Zjednodušeně řečeno, regresní model nám pomáhá zjistit, jak změny v nezávislém faktoru ovlivňují závislý faktor. Tento model nám pomáhá několika způsoby, například:
- Je to jednoduchý a výkonný statistický model
- Pomůže nám to při vytváření předpovědi a předpovědi
- Pomůže nám to učinit lepší obchodní rozhodnutí
- Pomůže nám to analyzovat výsledky a opravit chyby
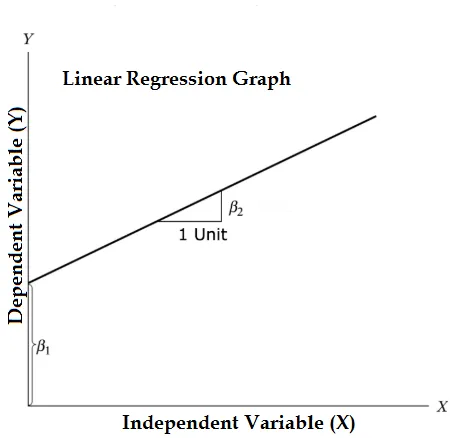
Rovnice lineární regrese a její rozdělení na relevantní části
Y = β1 + β2X + ϵ
- Kde β1 v matematické terminologii známé jako intercept a β2 v matematické terminologii známé jako sklon. Oni jsou také známí jako regresní koeficienty. ϵ je chybový termín, je částí Y, kterou regresní model nedokáže vysvětlit.
- Y je závislá proměnná (jiné termíny, které jsou zaměnitelně používány pro závislé proměnné, jsou proměnná odezvy, regresa, měřená proměnná, pozorovaná proměnná, reagující proměnná, vysvětlená proměnná, výsledná proměnná, experimentální proměnná a / nebo výstupní proměnná).
- X je nezávislá proměnná (regresory, řízená proměnná, manipulovala s proměnnou, vysvětlující proměnnou, expoziční proměnnou a / nebo vstupní proměnnou).
Problém: Pro pochopení, co je lineární regresní analýza, bereme dataset „Cars“, který je standardně dodáván v adresářích R. V tomto datovém souboru je 50 pozorování (v zásadě řádky) a 2 proměnné (sloupce). Názvy sloupců jsou „Dist“ a „Speed“. Zde musíme vidět dopad na proměnné vzdálenosti kvůli změnám proměnných rychlosti. Pro zobrazení struktury dat můžeme spustit kód Str (dataset). Tento kód nám pomáhá pochopit strukturu datového souboru. Tyto funkce nám pomáhají dělat lepší rozhodnutí, protože máme lepší představu o struktuře datových sad. Tento kód nám pomáhá určit typ datových sad.
Kód:

Podobně pro kontrolu statistických kontrolních bodů datového souboru můžeme použít kód Shrnutí (auta). Tento kód poskytuje střední, střední rozsah datového souboru za sebou, který může vědec použít při řešení problému.
Výstup:
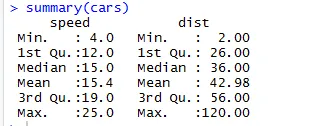
Zde vidíme statistický výstup každé proměnné, kterou máme v našem datovém souboru.
Grafické znázornění datových sad
Typy grafického znázornění, které zde budou zahrnovat, jsou a proč:
- Scatter Plot: Pomocí grafu můžeme vidět, kterým směrem se náš model lineární regrese ubírá, zda existuje nějaký silný důkaz, který by náš model dokázal, nebo ne.
- Box Plot: Pomáhá nám najít odlehlé hodnoty.
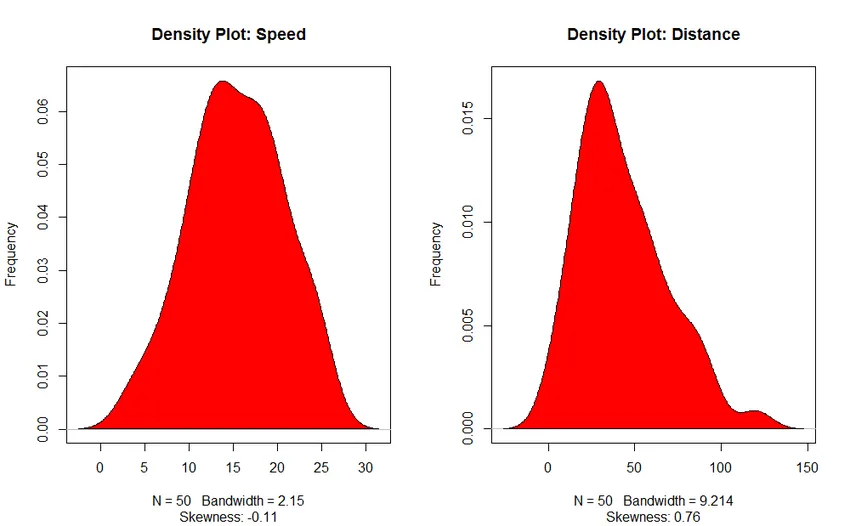
- Density Plot: Pomozte nám pochopit distribuci nezávislé proměnné, v našem případě je nezávislá proměnná „Speed“.
Výhody grafického znázornění
Zde jsou následující výhody:
- Snadno pochopitelné
- Pomáhá nám rychle se rozhodovat
- Srovnávací analýza
- Méně úsilí a času
1. Bodový graf: Pomůže vám vizualizovat jakékoli vztahy mezi nezávislou proměnnou a závislou proměnnou.
Kód:

Výstup:
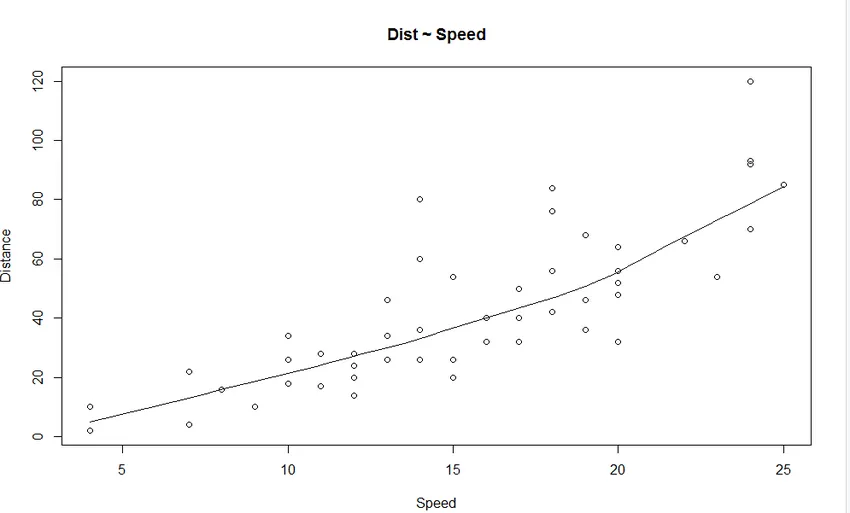
Z grafu vidíme lineárně rostoucí vztah mezi závislou proměnnou (vzdálenost) a nezávislou proměnnou (rychlost).
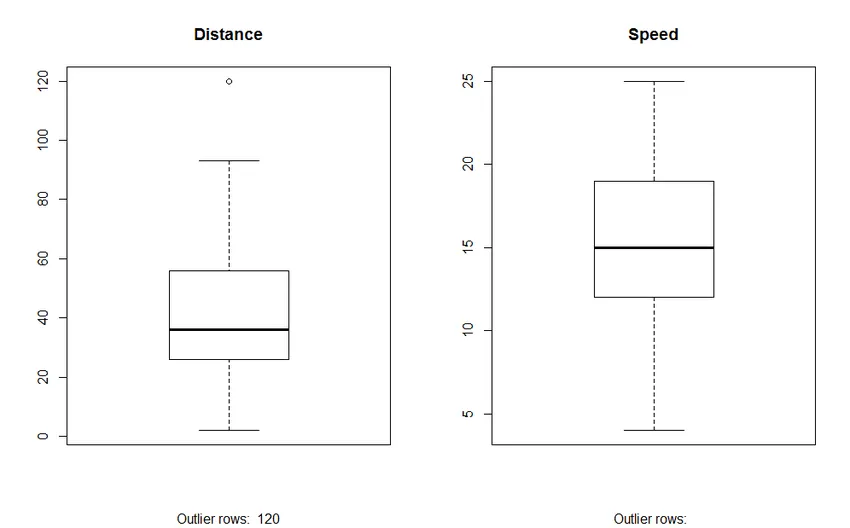
2. Box Plot: Box plot nám pomáhá identifikovat odlehlé hodnoty v datových sadách. Výhody použití boxového grafu jsou:
- Grafické zobrazení umístění a šíření proměnných.
- Pomáhá nám to pochopit skewness a symetrii dat.
Kód:

Výstup:
3. Dlot Plot (pro kontrolu normality rozdělení)
Kód:
 Výstup:
Výstup:
Korelační analýza
Tato analýza nám pomáhá najít vztah mezi proměnnými. Existuje hlavně šest typů korelační analýzy.
- Pozitivní korelace (0, 01 až 0, 99)
- Negativní korelace (-0, 99 až -0, 01)
- Žádná korelace
- Dokonalá korelace
- Silná korelace (hodnota blíže ± 0, 99)
- Slabá korelace (hodnota blíže k 0)
Bodový graf nám pomáhá určit, jaké typy datových sad korelací mezi nimi mají a kód pro nalezení korelace je

Výstup:
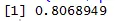
Zde máme silnou pozitivní korelaci mezi rychlostí a vzdáleností, což znamená, že mezi nimi mají přímý vztah.
Lineární regresní model
Toto je hlavní součást analýzy, dříve jsme se jen snažili a testovali věci, zda datový soubor, který máme, je dostatečně logický na to, abychom mohli takovou analýzu spustit nebo ne. Funkce, kterou plánujeme použít, je lm (). Tato funkce obsahuje dva prvky, které jsou vzorec a data. Před přiřazením toho, která proměnná je závislá nebo nezávislá, si musíme být jisti, protože na tom závisí celý náš vzorec.
Vzorec vypadá takto,
Lineární regrese <- lm (závislá proměnná ~ nezávislá proměnná, data = Date.Frame)
Kód:

Výstup:
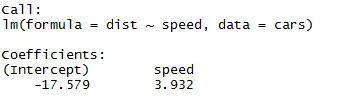
Jak si můžeme vzpomenout z výše uvedeného segmentu článku, rovnice lineární regrese je:
Y = β1 + β2X + ϵ
Nyní se do této rovnice vejdou informace, které jsme získali z výše uvedeného kódu.
dist = −17, 579 + 3, 932 ∗ rychlost
Pouze nalezení rovnice lineární regrese nestačí, musíme si také ověřit její statistickou významnost. Za tímto účelem musíme na našem modelu lineární regrese předat kód „Shrnutí“.
Kód:

Výstup:

Existuje několik způsobů, jak zkontrolovat statistickou významnost modelu, zde používáme metodu P-value. Model považujeme za statisticky vhodný, když je hodnota P menší než předem stanovená statisticky významná hladina, která je ideálně 0, 05. V naší souhrnné tabulce (lineární regrese) vidíme, že hodnota P je pod úrovní 0, 05, takže můžeme dojít k závěru, že náš model je statisticky významný. Jakmile jsme si jisti, o našem modelu, můžeme použít náš dataset k předpovídání věcí.
Doporučené články
Toto je průvodce analýzou lineární regrese. Zde diskutujeme tři typy lineární regresní analýzy, grafické znázornění datových sad s výhodami a modely lineární regrese. Další informace naleznete také v dalších souvisejících článcích.
- Regresní formule
- Regresní testování
- Lineární regrese v R
- Typy technik analýzy dat
- Co je to regresní analýza?
- Největší rozdíly regrese vs. klasifikace
- Top 6 rozdílů lineární regrese vs. logistické regrese