

Přehled architektury dolování dat
Dolování dat je způsob, jak najít a prozkoumat vzorce základní nebo pokročilé úrovně ve složité sadě velkých datových souborů, která zahrnuje metody umístěné na průniku statistik, strojového učení a také databázových systémů. Lze říci, že jde o interdisciplinární oblast statistiky a počítačových věd, kde cílem je extrahovat informace pomocí inteligentních metod a technik z konkrétní sady dat pomocí extrakce a tím transformovat data. Zohledněny jsou také činnosti správy dat a činnosti předzpracování dat spolu s úvahami o odvození. V tomto článku se ponoříme hluboko do architektury dolování dat.
Architektura dolování dat
Těžba dat je technika získávání zajímavých znalostí ze sady obrovského množství dat, která jsou poté uložena v mnoha zdrojích dat, jako jsou systémy souborů, datové sklady, databáze. Primární komponenty architektury dolování dat zahrnují -
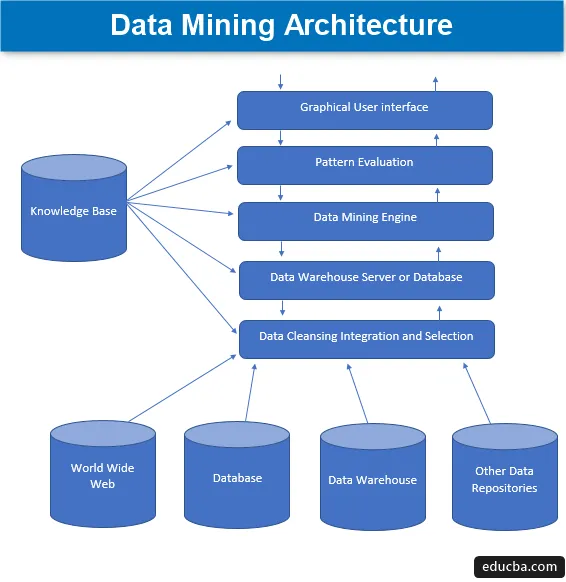
1. Zdroje dat
Obrovské množství současných dokumentů, jako je datový sklad, databáze, www nebo populárně nazývaný web, který se stává skutečným zdrojem dat. Většinou se také může stát, že data nejsou přítomna v žádném z těchto zlatých zdrojů, ale pouze ve formě textových souborů, obyčejných souborů nebo sekvenčních souborů nebo tabulek, a pak je třeba data zpracovat ve velmi podobným způsobem, jako by bylo zpracování provedeno na datech získaných ze zlatých zdrojů. Většina dnešních hlavních částí dat je přijímána z internetu nebo z celosvětového webu, protože vše, co je dnes na internetu přítomno, jsou data v nějaké formě nebo jiná, která tvoří nějakou formu jednotek úložiště informací.
Před zpracováním dat dopředu různé procesy, kterými prochází, zahrnují čištění, integraci a výběr dat, než jsou data konečně předána do databáze nebo na libovolný server EDW (podnikový datový sklad). Hlavní výzvou, která občas leží u této sady dat, jsou různé úrovně zdrojů a široké spektrum formátů dat, které tvoří datové komponenty. Data tedy nemohou být přímo použita pro zpracování ve svém naivním stavu, ale zpracována, transformována a vytvořena mnohem použitelnějším způsobem. Tímto způsobem je také zajištěna spolehlivost a úplnost dat. Primární krok tedy zahrnuje sběr dat, čištění a integraci a post, že pouze příslušná data jsou předávána vpřed. Všechny tyto činnosti tvoří součást samostatné sady nástrojů a technik.
2. Datový skladový server nebo databáze
Databázový server je skutečný prostor, ve kterém jsou data obsažena, jakmile jsou přijata z různých zdrojů dat. Server obsahuje skutečnou sadu dat, která jsou připravena ke zpracování, a proto server řídí načítání dat. Veškerá tato činnost je založena na žádosti o dolování dat o osobě.
3. Engine dolování dat
V případě dolování dat tvoří motor hlavní součást a je nejdůležitější součástí, neboli říkají hnací silou, která vyřizuje všechny požadavky a řídí je a používá se pro obsazení několika modulů. Počet přítomných modulů zahrnuje těžební úkoly jako klasifikační techniku, asociační techniku, regresní techniku, charakterizaci, predikci a shlukování, analýzu časových řad, naivní Bayes, podpůrné vektorové stroje, metody komplikací, posilovací a pytlovací techniky, náhodné lesy, rozhodovací stromy, atd.
4. Moduly pro vyhodnocení vzoru
Tato vyhodnocovací technika modulů je hlavně zodpovědná za měření zajímavosti všech těch vzorců, které se používají pro výpočet základní úrovně prahové hodnoty, a také se používá k interakci s modulem dolování dat pro koordinaci při hodnocení ostatních modulů. Celkově vzato, hlavním účelem této komponenty je hledat a hledat všechny zajímavé a použitelné vzory, které by mohly dát údaje ve srovnatelně lepší kvalitě.
5. Grafické uživatelské rozhraní
Když jsou data komunikována s motory a mezi různými hodnotami vzorů modulů, stává se nutností interakce s různými přítomnými komponentami a je uživatelsky přívětivější, aby bylo možné účinně a efektivně využívat všechny přítomné komponenty, a proto vyvstává potřeba grafického uživatelského rozhraní známého jako GUI.
To se používá k navázání pocitu kontaktu mezi uživatelem a systémem dolování dat, a pomáhá tak uživatelům přistupovat k systému a používat jej efektivně a snadno, aby se zabránilo jakémukoli složitosti, který v procesu vznikl. Jedná se o formu abstrakce, kde se uživatelům zobrazují pouze relevantní komponenty a pro zjednodušení jsou skryty všechny složitosti a funkcionality odpovědné za sestavení systému. Kdykoli uživatel odešle dotaz, modul pak interaguje s celkovou sadou systému dolování dat, aby vytvořil relevantní výstup, který by mohl být uživateli snadno pochopitelný mnohem srozumitelnějším způsobem.
6. Znalostní báze
Toto je součást, která tvoří základ celého procesu těžby dat, protože pomáhá při vedení vyhledávání nebo při hodnocení zajímavosti vytvořených vzorů. Tato znalostní databáze sestává z přesvědčení uživatelů a také z dat získaných ze zkušeností uživatelů, které jsou zase užitečné v procesu dolování dat. Motor by mohl získat svou sadu vstupů z vytvořené znalostní základny, a tím poskytovat účinnější, přesnější a spolehlivější výsledky.
Dolování dat je jednou z nejdůležitějších technik, která se dnes zabývá správou a zpracováním dat, které tvoří páteř jakékoli organizace. Analýza dat v jakékoli organizaci přinese plodné výsledky. Každá složka techniky a architektury dolování dat má svůj vlastní způsob plnění povinností a také efektivní dokončení dolování dat. Různé moduly jsou potřebné pro správnou interakci, aby se dosáhlo hodnotného výsledku a aby se úspěšně dokončil složitý postup získávání dat poskytováním správné sady informací podniku.
Doporučené články
Toto byl průvodce architekturou dolování dat. Zde diskutujeme primární komponenty architektury dolování dat. Další informace naleznete také v dalších navrhovaných článcích -
- Nástroj pro dolování dat
- Výhody dolování dat
- Co je klastrování v těžbě dat?
- HTML5 Interview Otázky a odpovědi
- Nejpoužívanější techniky učení souboru
- Algoritmy modelů při těžbě dat