
Úvod do režimu spánku
Existují různé vztahy, které udržujeme, abychom vytvořili spojení mezi různými databázovými tabulkami v relačních databázových modelech. Tyto vztahy jsou jedna ku jedné, jedna k mnoha a mnoho k mnoha. Podobný koncept se instaluje v režimu spánku. Zde hibernace pracuje na propojení jazyka JAVA s databázovou tabulkou a tímto odkazem můžeme navázat vztahy / mapování. Tato mapování lze použít k navigaci v databázi. Toto mapování je definováno v listu XML. Toto je obecně psáno kodéry, ale různé nástroje mohou být také použity k jeho vytvoření. Některé z těchto nástrojů jsou XDoclet, AndroMDA a Middlegen.
Primární typy mapování režimu spánku
Existují především tři typy mapování. Tyto jsou:
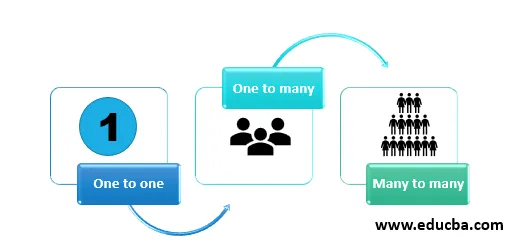
- Jeden na jednoho: V tomto druhu vztahu je jeden atribut mapován na jiný atribut takovým způsobem, že je zachováno pouze mapování jeden ku jednomu. To lze lépe pochopit pomocí příkladu. Například, pokud jedna osoba pracuje pouze pro jedno oddělení. Tentýž člověk nemůže být zaměstnán jiným oddělením, pak se mapování nazývá jeden k jednomu.
- Jeden k mnoha: V tomto druhu vztahu je jeden atribut mapován na jiný atribut tak, že jeden atribut je mapován na mnoho dalších atributů. To lze lépe pochopit pomocí příkladu. například: Je-li jeden student členem různých skupin. Jako kulturní skupina, sportovní klub, robotický klub současně. V takovém případě se vztah student a skupina nazývá mnoho vztahem jeden.
- Mnoho k mnoha: V tomto druhu vztahu je jeden atribut mapován na jiný atribut tak, že libovolný počet atributů může být spojen s jinými atributy bez omezení počtu. To lze lépe pochopit pomocí příkladu. například: V knihovně může jedna osoba vzít více knih a také jednu knihu lze vydat do více knih. Tento druh vztahu se nazývá mnoho k mnoha vztahům. Jedná se o složitý vztah a před implementací je třeba hodně porozumět případu obchodního využití.
Podrobné vysvětlení režimu spánku
Pokud projdeme kód, pochopíme, že v databázi je vytvořena tabulka EMP_ATTR, která ukládá atributy zaměstnanců, které mají sloupce jako jméno, příjmení a plat. Data z java aplikace jsou uložena v této tabulce, která je vyvinuta na front-endu.
Technická specifikace založená na kódu napsaném k vysvětlení:
je kořenový uzel, který v něm obsahuje prvky. Třída se používá k propojení javy s databází prostřednictvím dvou atributů. Název třídy „emp“ je název třídy převzatý z kódu java, zatímco tabulka „EMP_ATTR“ je název tabulky z databáze. element help při mapování primárního klíče na jedinečná ID.
Primární klíč je přítomen v databázi, zatímco jedinečná ID jsou odvozena od třídy java. název pochází z javy, zatímco sloupec je sloupec z tabulky v databázi. Atribut type má styl mapování hibernace, který převádí typ dat java na typ dat sql. třída se používá k automatickému generování primárního klíče. Prvek generátoru je „nativní“.
To dává indikaci pro hibernaci, že může vybrat jakýkoli navržený algoritmus, jako je Hilo, algoritmus identity nebo sekvence, pro vytvoření primárního klíče. Konečně třída. Toto je definující třída, která mapuje vlastnost třídy java na sloupec v tabulce databáze. Atribut name odkazuje na název vlastnosti třídy java, zatímco sloupec je sloupec z tabulky v databázi. Atribut type obsahuje typ hibernace, který pomůže systému určit datový typ, když jsou data třídy java převedena na datový typ RDBMS (systém správy relačních databází).
Poznámka: Toto je kód vysvětlující mapování hibernace. Není to skutečná implementace kódu.Kód:
Takto vypadá soubor XML. Pochází z hibernate.org, což je oficiální web Hibernate.
"-//Hibernate/Hibernate Mapping DTD//EN"
"http://www.hibernate.org/dtd/hibernate-mapping-3.0.dtd">
"-//Hibernate/Hibernate Mapping DTD//EN"
"http://www.hibernate.org/dtd/hibernate-mapping-3.0.dtd">
"-//Hibernate/Hibernate Mapping DTD//EN"
"http://www.hibernate.org/dtd/hibernate-mapping-3.0.dtd">
Tento soubor je uložen ve formátu .hbm.xml. V tomto případě by měl být soubor uložen na jméno EMP_ATR.hbm.xml.
Typ mapování v režimu spánku
Takže v předchozím příkladu kódu vidíme typy mapování hibernace v souboru XML. Tyto typy mapování mohou být mnoha typů:
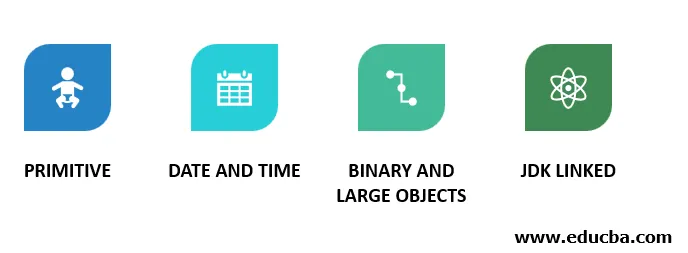
- Primitivní: Tyto typy mapování mají datové typy definované jako „integer“, „character“, „float“, „string“, „double“, „Boolean“, „short“, „long“ atd. Tyto jsou přítomny v režimu spánku mapovat datový typ Java na datový typ RDBMS.
- Datum a čas: Jedná se o „datum“, „čas“, „kalendář“, „časové razítko“ atd. Stejně jako primitivní máme i tato mapování datových a datových typů.
- Binární a velké objekty: Tyto typy jsou „clob“, „blob“, „binární“, „text“ atd. Jsou k dispozici datové typy Clob a blob, které zachovávají mapování typů dat velkých objektů, jako jsou obrázky a videa.
- Propojené JDK: Do této kategorie jsou zahrnuta některá mapování objektů, která leží mimo dosah předchozího mapování. Jsou to „třída“, „národní prostředí“, „měna“, „časové pásmo“.
Závěr
Hibernační mapování je tedy koncept, který lze realizovat vytvořením mapování pomocí souborů XML. Tato mapování se stávají základem databáze navržené podle požadavků obchodního modelu. To pomáhá při určování vztahů mezi přetrvávajícími objekty v databázi. Toto mapování je rozhodující pro návrh databáze, protože se stává základem pro front-end aplikaci z hlediska výkonu, přesnosti a rychlosti.
Doporučené články
Toto je průvodce Hibernate Mapping. Zde diskutujeme hibernační mapování s podrobným vysvětlením, typy a primární typy mapování hibernace spolu se ukázkovým kódem. Další informace naleznete také v následujícím článku -
- Co je Hibernace?
- Hibernace Framework
- Co je to Java Hibernate?
- Hibernate Interview Otázky