

Rozdíl mezi MapReduce a Spark
Map Reduce je open-source framework pro zápis dat do HDFS a zpracování strukturovaných a nestrukturovaných dat přítomných v HDFS. Mapa Reduce je omezena na dávkové zpracování a na jiné Spark je schopen provádět jakýkoli druh zpracování. SPARK je nezávislý procesor pro zpracování v reálném čase, který lze nainstalovat do jakéhokoli systému distribuovaných souborů, jako je Hadoop. SPARK poskytuje výkon, který je 10krát rychlejší než Map Reduce na disku a 100krát rychlejší než Map Reduce v síti v paměti.
Potřeba SPARK
- Iterativní analytika: Redukce mapy není tak efektivní jako SPARK při řešení problémů, které vyžadují iterativní analytiku, protože musí jít na disk pro každou iteraci.
- Interaktivní analytika: Redukce map se často používá ke spuštění ad-hoc dotazů, pro které je třeba se dostat do paměti na disku, což opět není tak efektivní jako SPARK, protože ten druhý odkazuje v paměti rychlejší.
- Nevhodné pro OLTP: Protože pracuje na dávkově orientovaném rámci, není vhodné pro velké množství krátkých transakcí.
- Nevhodné pro graf: Knihovna Apache Graph zpracovává graf, který zvyšuje složitost aplikace Map Reduce.
- Nevhodné pro triviální operace: U operací, jako je filtr a spojení, bude možná nutné přepsat úlohy, které se díky vzoru klíč-hodnota stanou složitější.
Srovnání hlava-hlava mezi MapReduce vs Spark (Infografika)
Níže je prvních 15 rozdílů mezi MapReduce a Spark

Klíčové rozdíly mezi MapReduce a Spark
Níže jsou uvedeny seznamy bodů, popište klíčové rozdíly mezi MapReduce a Spark:
- Spark je vhodný pro práci v reálném čase, protože zpracovává v paměti, zatímco MapReduce je omezen na dávkové zpracování.
- Spark má RDD (Resilient Distributed Dataset), což nám poskytuje operátory na vysoké úrovni, ale v Mapu snížit potřebujeme kódovat každou operaci, což je poměrně obtížné.
- Spark umí zpracovat grafy a podporuje nástroj Strojové učení.
- Níže je rozdíl mezi ekosystémem MapReduce a Spark.
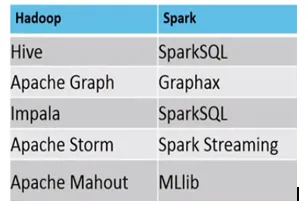
Příklady, kde jsou vhodné MapReduce vs Spark, jsou následující
Spark: Detekce podvodů s kreditními kartami
MapReduce: Vytváření pravidelných zpráv, které vyžadují rozhodování.
Tabulka porovnávání MapReduce vs Spark
| Základ srovnání | MapReduce | Jiskra |
| Rámec | Open-source framework pro zápis dat do HDFS a zpracování strukturovaných a nestrukturovaných dat přítomných v HDFS. | Open-source framework pro rychlejší a univerzální zpracování dat |
| Rychlost | Map-Reduce zpracovává data (čte a zapisuje) z disku, takže průnik je ve srovnání se Sparkem pomalý. | Spark je nejméně 10x rychlejší na disku a 100x rychlejší v paměti jako u Map Reduce. |
| Obtížnost | Každý proces musíme kódovat / zpracovat. | Díky dostupnosti RDD (Resilient Distributed Dataset) je snadné programovat. |
| Reálný čas | Nevhodné pro transakci OLTP pouze pro dávkový režim | Zvládá zpracování v reálném čase. Používání streamování SPARK. |
| Latence | High-level latence computing framework | Rámec pro výpočet latence s nízkou úrovní. |
| Odolnost proti chybám | Hlavní démoni zkontrolují srdeční rytmus démonů otroků a v případě selhání démonů otroků démoni hlavní démoni přeplánují všechny čekající a probíhající operace na jiného otroka. | RDD poskytují odolnost proti poruchám SPARKu. Vztahují se na datovou sadu přítomnou v externím úložišti jako (HDFS, HBase) a pracují paralelně. |
| Plánovač | V Map Reduce používáme externí plánovač jako je Oozie. | Protože SPARK pracuje s výpočtem v paměti, funguje jako jeho vlastní plánovač. |
| Náklady | Mapa Reduce je ve srovnání se SPARKem relativně levnější. | Jak to funguje v paměti, tak to vyžaduje hodně RAM, což je poměrně nákladnější. |
| Platforma byla vyvinuta na | Mapa Reduce byla vyvinuta pomocí Java. | SPARK byl vyvinut pomocí Scala. |
| Jazyk podporován | Map Reduce v podstatě podporuje C, C ++, Ruby, Groovy, Perl, Python. | Spark podporuje Scala, Java, Python, R, SQL. |
| Podpora SQL | Map Reduce spouští dotazy pomocí jazyka Hive Query Language. | Spark má svůj vlastní dotazovací jazyk známý jako Spark SQL. |
| Škálovatelnost | V Map Reduce můžeme přidat až n počet uzlů. Největší cluster Hadoop má 14000 uzlů. | Ve Spark také můžeme přidat n počet uzlů. Největší klastr Spark má 8000 uzlů. |
| Strojové učení | Map Reduce podporuje nástroj Apache Mahout pro strojové učení. | Spark podporuje nástroj MLlib pro strojové učení. |
| Ukládání do mezipaměti | Redukce mapy není schopna ukládat do mezipaměti data paměti, takže není tak rychlá ve srovnání se Sparkem. | Spark ukládá do paměti data pro další iterace, takže je velmi rychlý ve srovnání s Map Reduce. |
| Bezpečnostní | Map Reduce podporuje více bezpečnostních projektů a funkcí ve srovnání s aplikací Spark | Zabezpečení jisker dosud není vyzrálé jako zabezpečení Map Reduce |
Závěr - MapReduce vs Spark
Pokud jde o výše uvedený Rozdíl mezi MapReduce a Spark, je zcela jasné, že SPARK je mnohem vyspělejší výpočetní stroj ve srovnání s Map Reduce. Spark je kompatibilní s jakýmkoli formátem souboru a také mnohem rychlejší než Map Reduce. Jiskra má navíc také možnosti zpracování grafů a strojového učení.
Na jedné straně je Map Reduce omezen na dávkové zpracování a na druhé Spark je schopen provádět jakýkoli druh zpracování (dávkové, interaktivní, iterační, streamování, graf). Díky velké kompatibilitě je Spark oblíbeným datovým vědcem, a proto nahrazuje Map Reduce a rychle roste. Stále však musíme data ukládat v HDFS a někdy také potřebujeme HBase. Abychom dostali to nejlepší, musíme spustit Spark i Hadoop.
Doporučené články:
Toto byl průvodce MapReduce vs. Spark, jejich význam, srovnání hlava-hlava, hlavní rozdíly, srovnávací tabulka a závěr. Další informace naleznete také v následujících článcích -
- 7 důležitých věcí o Apache Spark (Průvodce)
- Hadoop vs Apache Spark - Zajímavé věci, které potřebujete vědět
- Apache Hadoop vs Apache Spark | Top 10 srovnání, které musíte znát!
- Jak MapReduce funguje?
- Soutok technologie a obchodní analýzy