
Úvod do modelů strojového učení
Přehled různých modelů strojového učení používaných v praxi. Podle definice je model strojového učení matematickou konfigurací získanou po použití specifických metod strojového učení. S využitím široké škály rozhraní API je vytváření modelu strojového učení v dnešní době do značné míry přímočaré s menším počtem řádků kódů. Skutečná dovednost odborníka na aplikovanou vědu spočívá ve výběru správného modelu založeného na prohlášení problému a křížové validaci namísto náhodného házení dat do ozdobných algoritmů. V tomto článku budeme diskutovat různé modely strojového učení a jak je efektivně využívat na základě typu problémů, které řeší.
Typy modelů strojového učení
Na základě typu úkolů můžeme klasifikovat modely strojového učení do následujících typů:
- Klasifikační modely
- Regresní modely
- Shlukování
- Snížení rozměrů
- Hluboké učení atd.
1) Klasifikace
Pokud jde o strojové učení, klasifikace je úkolem předpovídat typ nebo třídu objektu v omezeném počtu možností. Výstupní proměnná pro klasifikaci je vždy kategorická proměnná. Například předpovídání e-mailu je spam nebo ne, je standardní úkol binární klasifikace. Nyní si poznamenejte některé důležité modely problémů s klasifikací.
- Algoritmus K-Nearest Neighbors - jednoduchý, ale výpočetně vyčerpávající.
- Naivní Bayes - založený na Bayesově větě.
- Logistická regrese - lineární model pro binární klasifikaci.
- SVM - lze použít pro binární / více třídové klasifikace.
- Rozhodovací strom - Klasifikátor založený na „ If Else “, robustnější pro odlehlé hodnoty.
- Soubory - Kombinace více modelů strojového učení se sdružuje, aby se dosáhlo lepších výsledků.
2) Regrese
Ve stroji je regrese učení souborem problémů, kde výstupní proměnná může mít nepřetržité hodnoty. Například předpovídání ceny letecké společnosti lze považovat za standardní regresní úkol. Poznamenejte si některé důležité regresní modely používané v praxi.
- Lineární regrese - nejjednodušší základní model pro regresní úlohu, funguje dobře pouze tehdy, jsou-li data lineárně oddělitelná a je-li přítomna velmi malá nebo žádná multicollinearita.
- Lasova regrese - lineární regrese s regularizací L2.
- Ridge Regression - Lineární regrese s regularizací L1.
- SVM regrese
- Regrese rozhodovacích stromů atd.
3) Shlukování
Jednoduše řečeno, seskupování je úkolem seskupování podobných objektů dohromady. Modely strojového učení pomáhají automaticky identifikovat podobné objekty bez ručního zásahu. Bez homogenních dat nemůžeme vytvořit efektivní modely strojového učení pod dohledem (modely, které je třeba proškolit pomocí ručně kurovaných nebo označených dat). Clustering nám pomáhá dosáhnout toho chytřejším způsobem. Následuje několik široce používaných klastrových modelů:
- K znamená - jednoduché, ale trpí velkým rozptylem.
- K znamená ++ - Upravená verze K znamená.
- K medoidy.
- Aglomerační klastrování - hierarchický klastrovací model.
- DBSCAN - algoritmus shlukování založený na hustotě atd.
4) Zmenšení rozměrů
Dimenzionalita je počet prediktorových proměnných používaných k predikci nezávislé proměnné nebo cíle. V reálných datových sadách je počet proměnných příliš vysoký. Příliš mnoho proměnných také přinese modelům prokletí. V praxi mezi těmito velkými počty proměnných ne všechny proměnné přispívají stejným dílem k cíli a ve velkém počtu případů můžeme skutečně zachovat odchylky s menším počtem proměnných. Pojďme vyjmenovat některé běžně používané modely pro zmenšení rozměrů.
- PCA - Vytváří menší počet nových proměnných z velkého počtu prediktorů. Nové proměnné jsou na sobě nezávislé, ale méně interpretovatelné.
- TSNE - Poskytuje nižší dimenzionální vkládání dat vyšších bodů.
- SVD - Rozklad singulární hodnoty se používá k rozkladu matice na menší části, aby byl zajištěn efektivní výpočet.
5) Hluboké učení
Hluboké učení je podmnožinou strojového učení, které se zabývá neuronovými sítěmi. Na základě architektury neuronových sítí vyjmenujme důležité hluboké modely učení:
- Vícevrstvý perceptron
- Konvoluční neuronové sítě
- Opakující se neuronové sítě
- Boltzmann stroj
- Autoenkodéry atd.
Který model je nejlepší?
Výše jsme vzali nápady na spoustu modelů strojového učení. Nyní přichází na naši mysl zřejmá otázka „Který z nich je nejlepší model?“ Záleží na aktuálním problému a dalších souvisejících atributech, jako jsou odlehlé hodnoty, objem dostupných dat, kvalita dat, inženýrství prvků atd. V praxi je vždy lepší začít s nejjednodušším modelem použitelným na problém a zvýšit složitost postupně správným vyladěním parametrů a křížovou validací. Ve světě datových věd je přísloví - „Křížová validace je důvěryhodnější než znalost domény“.
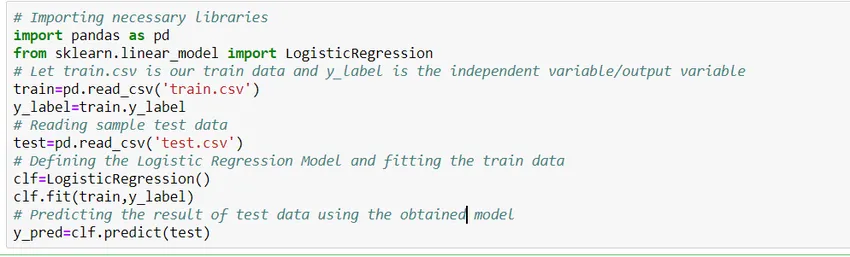
Jak postavit model?
Podívejme se, jak vytvořit jednoduchý logistický regresní model pomocí knihovny Scikit Learn python. Pro zjednodušení předpokládáme, že problém je standardní klasifikační model a „train.csv“ je vlak a „test.csv“ jsou údaje o vlaku a zkoušce.
Závěr
V tomto článku jsme diskutovali důležité modely strojového učení používané pro praktické účely a jak vytvořit jednoduchý model strojového učení v pythonu. Výběr správného modelu pro konkrétní případ použití je velmi důležitý pro získání správného výsledku úlohy strojového učení. Pro porovnání výkonu mezi různými modely jsou definovány metriky hodnocení nebo KPI pro konkrétní obchodní problémy a nejlepší model je vybrán pro výrobu po použití statistické kontroly výkonu.
Doporučené články
Toto je průvodce modely strojového učení. Zde diskutujeme 5 hlavních typů modelů strojového učení s jejich definicí. Další informace naleznete také v dalších navrhovaných článcích -
- Metody strojového učení
- Druhy strojového učení
- Algoritmy strojového učení
- Co je strojové učení?
- Hyperparametrické strojové učení
- KPI v Power BI
- Hierarchický klastrovací algoritmus
- Hierarchické klastry Aglomerativní a dělící se shlukování