

Úvod do příkazů jisker
Apache Spark je framework postavený na Hadoopu pro rychlé výpočty. Rozšiřuje koncept MapReduce ve scénáři založeném na klastrech tak, aby efektivně fungoval úkol. Příkaz Spark je napsán v Scale.
Hadoop může být využíván Spark následujícími způsoby (viz níže):
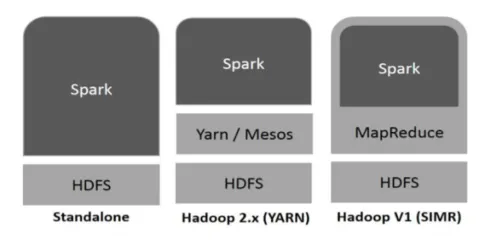
Obr. 1
https://www.tutorialspoint.com/
- Samostatný: Spark přímo nasazen na Hadoop. Sparkové úlohy běží paralelně na Hadoop a Spark.
- Hadoop YARN: Jiskra běží na příze bez potřeby jakékoli předinstalace.
- Spark v MapReduce (SIMR): Spark v MapReduce se používá ke spuštění iskry kromě samostatného nasazení. S SIMR, jeden může spustit Spark a moci používat jeho shell bez nějakého administrativního přístupu.
Složky jiskry:
- Apache Spark Core
- Spark SQL
- Spark Streaming
- MLib
- GraphX
Resilient Distributed Datasets (RDD) je považován za základní datovou strukturu příkazů Spark. RDD je neměnná a má pouze čitelnou povahu. Všechny druhy výpočtů v jiskrových příkazech se provádějí prostřednictvím transformací a akcí na RDD.
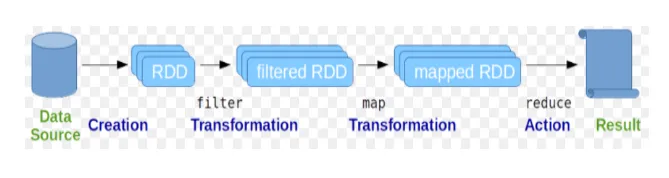
Obr
Obrázek Google
Spark shell poskytuje uživatelům prostředí pro interakci s jeho funkcemi. Příkazy Spark mají mnoho různých příkazů, které lze použít ke zpracování dat v interaktivní schránce.
Základní jiskrové příkazy
Pojďme se podívat na některé základní příkazy Spark, které jsou uvedeny níže: -
-
Spuštění shellu Spark:

Obr
-
Číst soubor z lokálního systému:

Tady „sc“ je jiskřící kontext. Vzhledem k tomu, že „data.txt“ je v domovském adresáři, je to takto čteno, jinak je třeba zadat úplnou cestu.
-
Vytvořte RDD prostřednictvím paralelizace

NewData je nyní RDD.
-
Počet položek v RDD

-
Sbírat
Tato funkce vrátí veškerý obsah RDD do programu ovladače. To je užitečné při ladění v různých krocích programu psaní.
-
Přečtěte si první 3 položky z RDD

-
Uložte výstupní / zpracovaná data do textového souboru

Zde je „výstupní“ složka aktuální cestou.
Příkazy pro přechodné jiskry
1. Filtrování na RDD
Vytvořme nový RDD pro položky, které obsahují „ano“.

Filtr transformace je třeba zavolat na stávající RDD, aby se filtrovalo na slovo „ano“, které vytvoří nový RDD s novým seznamem položek.
2. Řetězový provoz

Zde transformace filtru a akce počítání fungovaly společně. Tomu se říká řetězová operace.
3. Přečtěte si první položku z RDD

4. Počet oddílů RDD
Jak víme, RDD se skládá z více oddílů, je třeba počítat ne. oddílů. Pomáhá při ladění a odstraňování problémů při práci s příkazy Spark.

Ve výchozím nastavení je minimální. oddíl je 2.
5. připojit se
Tato funkce spojí dvě tabulky (element tabulky je párovým způsobem) na základě společného klíče. V RDD v páru je prvním prvkem klíč a druhým prvkem je hodnota.
6. Vyrovnávací paměť souboru
Ukládání do mezipaměti je optimalizační technika. Ukládání do mezipaměti RDD znamená, že RDD zůstane v paměti a veškeré budoucí výpočty budou provedeny na těch RDD v paměti. Šetří čas načtení disku a zlepšuje výkon. Stručně řečeno, zkracuje se doba přístupu k datům.

Data však nebudou ukládána do mezipaměti, pokud spustíte nad funkcí. To lze prokázat návštěvou webové stránky:
http: // localhost: 4040 / storage
Jakmile bude akce dokončena, RDD bude uložena do mezipaměti. Například:

Jedna funkce, která funguje podobně jako cache (), přetrvává (). Persist poskytuje uživatelům flexibilitu při zadávání argumentu, což může pomoci ukládat data do mezipaměti v paměti, na disku nebo v paměti mimo úložiště. Přetrvávat bez argumentů funguje stejně jako cache ().
Pokročilé příkazy k jiskření
Pojďme se podívat na některé pokročilé příkazy Spark, které jsou uvedeny níže: -
-
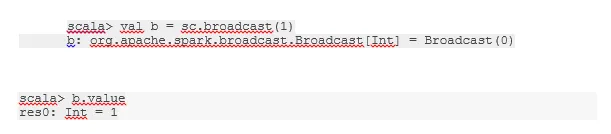
Vysílejte proměnnou
Proměnná Broadcast pomáhá programátorovi číst jedinou proměnnou uloženou v mezipaměti na každém počítači v klastru, a nikoli odesílat kopii této proměnné s úkoly. To pomáhá při snižování nákladů na komunikaci.
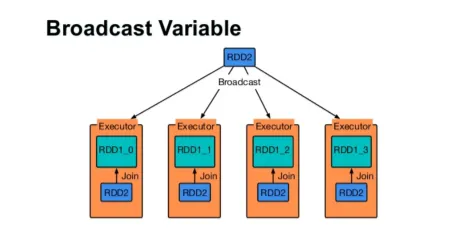
Obr
Obrázek Google
Stručně řečeno, existují tři hlavní rysy proměnné Broadcasted:
- Nemožné
- Zapadá do paměti
- Distribuováno přes cluster
-
Akumulátory
Akumulátory jsou proměnné, které se přidávají k přidruženým operacím. Existuje mnoho použití pro akumulátory, jako jsou pulty, částky atd.

Název akumulátoru v kódu lze také vidět v uživatelském rozhraní Spark.
-
Mapa
Funkce Map pomáhá při iteraci přes každou řádku v RDD. Funkce použitá v mapě je aplikována na každý prvek v RDD.
Například v RDD (1, 2, 3, 4, 6), pokud použijeme „rdd.map (x => x + 2)“, dostaneme výsledek jako (3, 4, 5, 6, 8).
-
Flatmap
Flatmap funguje podobně jako mapa, ale mapa vrací pouze jeden prvek, zatímco flatmap může vrátit seznam prvků. Rozdělení vět na slova bude tedy vyžadovat flatmap.
-
Coalesce
Tato funkce pomáhá zabránit zamíchání dat. To se použije ve stávajícím oddílu, takže se zamíchá méně dat. Tímto způsobem můžeme omezit použití uzlů v klastru.
Tipy a triky k použití jiskrových příkazů
Níže jsou uvedeny různé tipy a triky příkazů Spark: -
- Začátečníci Spark mohou používat Spark-shell. Protože příkazy Spark jsou postaveny na Scale, je určitě skvělé používat Scala jiskřici. K dispozici je však také pythonová skořápka, takže i to, co může člověk použít, je s pythonem dobře obeznámeno.
- Spark shell má mnoho možností pro správu zdrojů klastru. Níže vám může pomoci příkaz Command:

- Ve Spark je obvyklá práce s dlouhými datovými sadami. Když se však přijme špatný vstup, dojde k chybě. Vždy je dobré zahodit špatné řádky pomocí funkce filtru Spark. Dobrý soubor vstupů bude skvělý krok.
- Spark si pro vaše data vybere dobrý oddíl. Před začátkem práce je však vždy dobré sledovat oddíly. Vyzkoušení různých oddílů vám pomůže s paralelizací vaší práce.
Závěr - příkazy jisker:
Příkaz Spark je revoluční a všestranný velký datový stroj, který může pracovat pro dávkové zpracování, zpracování v reálném čase, ukládání dat do mezipaměti atd. Spark má bohatou sadu knihoven strojového učení, které umožňují vědcům dat a analytickým organizacím budovat silné, interaktivní a rychlé aplikace.
Doporučené články
Toto byl průvodce příkazy Spark. Zde jsme probrali základní i pokročilé příkazy Spark a některé okamžité příkazy Spark. Další informace naleznete také v následujícím článku -
- Příkazy Adobe Photoshop
- Důležité příkazy VBA
- Tableau Příkazy
- Cheat sheet SQL (příkazy, tipy zdarma a triky)
- Typy spojení ve Spark SQL (příklady)
- Komponenty jisker Přehled a 6 hlavních komponent