

Co je Big Data a Hadoop?
Data rostou exponenciálně každý den as těmito rostoucími daty přichází potřeba tyto údaje využívat. Stejně jako ve starších dnech jsme měli k ukládání dat disketové mechaniky a přenos dat byl také pomalý, ale dnes je to nedostatečné a cloudové úložiště se používá, protože máme terabajty dat. V dnešním světě máme sociální média, která nejvíce přispívají k růstu dat. Skládá se z chování lidí, myšlení a několika dalších aspektů. Říká se, že za každou minutu se na YouTube nahraje 300 hodin videa, na Facebook a mnoho dalších se nahraje přes 20 milionů fotografií. Navíc neexistuje řádná struktura vkládaných dat, což je největší výzva pro zpracování těchto dat.
Vzhledem k tomu, že se při vysoké rychlosti generují obrovské údaje, tradiční systémy RDBMS nebyly schopny zvládnout tak rychlý růst. Kromě toho také nejsou schopni zpracovávat nestrukturovaná data. Bylo velmi obtížné zvládnout tak obrovské množství heterogenních dat rychle rostoucích a zpracovávat je s vysokou rychlostí zpracování. Proto vznikla potřeba takového systému, který je schopen efektivně zpracovávat velké soubory dat. Proto Hadoop vyřešil scénář. HDFS je komponentou Hadoop, která řešila problém velkého datového souboru s úložištěm pomocí distribuovaného úložiště, zatímco YARN je komponenta, která řešila problém se zpracováním, čímž výrazně zkrátila dobu zpracování.
Hadoop je softwarový rámec s otevřeným zdrojovým kódem pro ukládání a zpracování velkých datových souborů pomocí distribuované velké skupiny komoditního hardwaru. Byl vyvinut Doug Cuttingem a Michaelem J. Cafarellou a je licencován pod Apache. Je psán pomocí Java a byl vyvinut na základě příspěvku napsaného společností Google v systému MapReduce a aplikuje koncepty funkčního programování. Je spolehlivý, ekonomický flexibilní a škálovatelný.
Klíčové komponenty Hadoopu
Hlavní komponenty Hadoop jsou následující
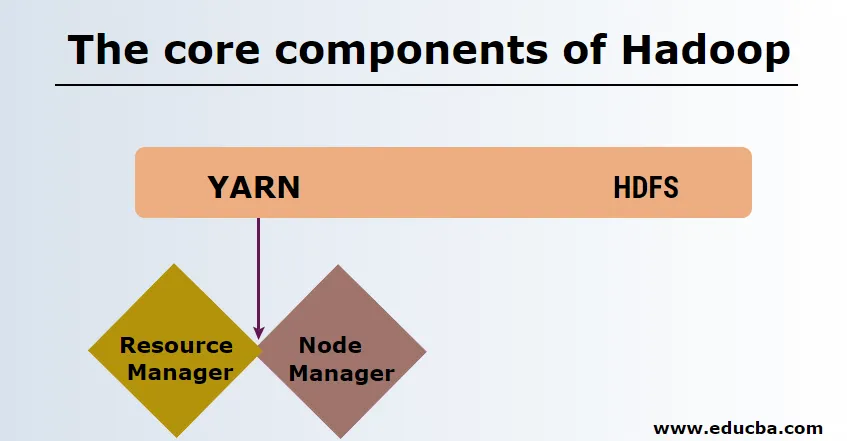
-
HDFS
Distribuovaný systém souborů HDFS nebo Hadoop má Namenode a datový uzel. Namenode je hlavní uzel, který spouští hlavní démona a spravuje datové uzly a sleduje všechny operace. Datanodes jsou slave, kde jsou data skutečně uložena.
-
PŘÍZE
YARN se skládá ze dvou hlavních komponent:
1. ResourceManager: Běží na hlavním uzlu a spravuje všechny zdroje a naplánuje všechny aplikace. Má Plánovač a ApplicationManager.
2. NodeManager: Běží na každém slave uzlu a je zodpovědný za správu kontejnerů a monitorování využití prostředků.
Několik komponent Hadoop
Existuje několik složek Hadoopu, jako je prase, úl, kořist, flume, mahout, oozie, zookeeper, HBase atd.
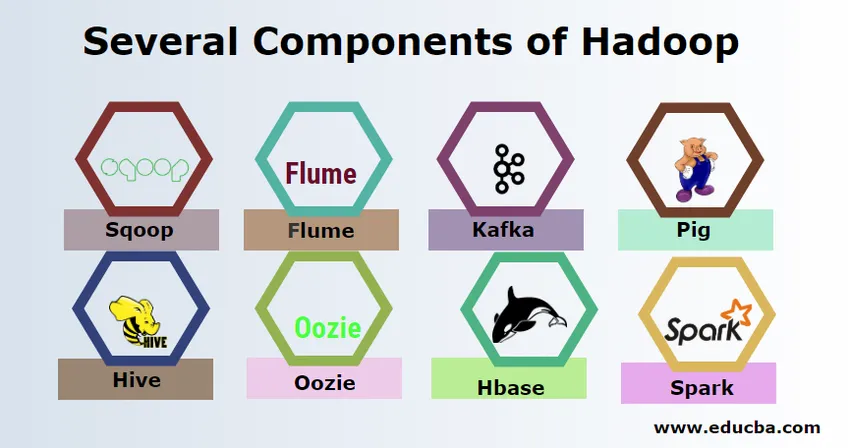
- Sqoop - Používá se k importu a exportu dat z RDBMS do Hadoopu a naopak.
- Flume - Používá se pro stahování dat v reálném čase do Hadoopu.
- Kafka - Jedná se o systém zasílání zpráv používaný k směrování dat v reálném čase do Hadoopu.
- Prase - Používá se jako skriptovací jazyk pro zpracování dat.
- Úl - Jedná se o rámec datového skladu, který je postaven na HDFS, takže uživatelé, kteří jsou dobře obeznámeni s SQL, mohou provádět dotazy, aby získali data. Tyto dotazy se nazývají HiveQL.
- Oozie - Používá se k naplánování pracovního postupu úloh, které se mají spouštět při zadaných událostech nebo čase.
- Hbase - Jedná se o žádnou databázi SQL poskytovanou jako součást Apache Hadoop.
- Spark - Používá se k provádění zpracování v paměti, které je mnohem rychlejší než snížení mapy Hadoop.
Poskytovatelé Hadoopu
Existuje spousta společností nabízejících distribuci Hadoop. Níže je několik nejlepších poskytovatelů Hadoop:
- Cloudera
- Hortonworks
- MapR
Existuje několik předpokladů pro učení se Hadoopu. Předchozí zkušenosti s jazykem Java a skriptovacím jazykem jsou nezbytné. Přestože Hadoop již má své vlastní programovací jazyky na vysoké úrovni, jako je prase a úl, které generují backendový kód pro další zpracování, stále je možné vytvořit vlastní program pro redukci map, jakýkoli programovací jazyk, jako je Ruby, Python, Perl a dokonce i programování v C.
Bigdata a Hadoop jsou na dnešním trhu velmi žádané. V nadcházejících dnech se to ještě zvýší. Spousta organizací se již přestěhovala do Hadoopu a ti, kteří se brzy přestěhují. Současná zpráva uvádí, že velké společnosti začaly investovat do analýzy velkých dat. Prognóza velkého datového marketingu má vždy vzestupný trend a vůbec to není krátkodobý stav. Kromě všech těchto úkolů v Hadoopu a velkých datech se vždy nabízejí vysoké odměny ve srovnání s jinými technologiemi.
Nejlepší společnosti s velkými daty a společností Hadoop
Níže je uvedeno několik nejlepších společností, které zaměstnávají nejvíce zdrojů Hadoop.
- Yahoo
- Amazonka
- Royal Bank of Scotland
- British Airways
- Expedia
- Walmart
Existuje mnoho společností, které používají velké datové aplikace. Tyto jsou:
-
Nokia
Pro aplikaci používá komponenty Cloudera a Hadoop jako HDFS, HBase, Sqoop, Scribe. Efektivně využila uživatelská data k porozumění a zlepšení uživatelského dojmu. Využívá zpracování dat a komplexní analýzy pro tvorbu mapy s prediktivním provozem a vrstvenými výškovými modely.
-
SAS
Spolupracovala s Hadoopem, aby pomohla vědcům s údaji získat lepší přehled poskytnutím prostředí, které poskytuje vizuální a interaktivní zážitek, a pomáhá tak objevovat nové trendy. Analytické programy extrahují smysluplné poznatky z dat a technologie v paměti pomáhá rychlejšímu přístupu k datům.
Existuje také mnoho dalších společností, které používají velké datové platformy pro různé analýzy. Jedná se o analýzu údajů o letu černé skříňky v leteckém průmyslu, různé analýzy na akciovém trhu atd.
Výhody Haddopu
Níže uvádíme několik výhod Hadoopu
- Škálovatelný - Na rozdíl od tradičního RDBMS je to vysoce škálovatelná platforma, protože může ukládat velké datové sady v distribuovaných klastrech před paralelně provozovaným hardwarem s komoditami.
- Nákladově efektivní - náklady byly příliš vysoké pro RDBMS pro ukládání dat, která byla v Hadoopu uvolněna.
- Rychlý a flexibilní - Nabízí rychlý přístup k datům prostřednictvím distribuovaného systému souborů. Nabízí také odvození obchodních poznatků z polostrukturovaných a nestrukturovaných dat.
- Odolnost proti chybám - Kdykoli jsou všechna data odeslána do uzlu, stejná data se replikují do jiných uzlů, ke kterým lze přistupovat v případě jakéhokoli selhání prvního uzlu.
Závěr - co je Big Data a Hadoop
Data neustále rostou, a proto bude vždy zapotřebí velkých dat a Hadoop bude z těchto dat dávat smysl. Z tohoto důvodu budou odborníci se znalostmi Hadoop vždy v nadcházejících dnech najít dostatek příležitostí a mohou být životně důležitým přínosem pro organizaci, která podporuje podnikání a jejich kariéru.
Doporučené články
Toto byl průvodce, co je Big Data a Hadoop. Zde jsme diskutovali základní pojmy a komponenty Big Data a Hadoop. Další informace naleznete také v následujícím článku -
- Příklady velkých datových analýz
- Použití Hadoopu
- Průvodce vizualizací dat
- Co je Big Data Analytics?