
Upravený R čtvercový vzorec (obsah)
- Upravený R čtvercový vzorec
- Příklady upravené vzorce R na druhou (se šablonou Excel)
Upravený R čtvercový vzorec
Než přejdeme na upravený vzorec na druhou mocninu, musíme pochopit, co je R2. Ve statistice, R2 také známý jako koeficient stanovení je nástroj, k němuž se stanoví a vyhodnocuje změna závislé proměnné, která je vysvětlena nezávislou proměnnou ve statistickém modelu. Takže pokud je R2 řečeno 0, 6, znamená to, že 60% variace v závislé proměnné je vysvětleno nezávislou proměnnou. Problém s R2 je však v tom, že se jeho hodnota zvyšuje s přidáním více proměnných bez ohledu na význam této proměnné. Abychom toho překonali, byl zaveden koncept upraveného čtverce. Myšlenka za R2 a upravená R na druhou je stejná, ale rozdíl je v tom, že upravené r na druhou upravuje hodnotu r čtverce pro počet termínů v modelu.
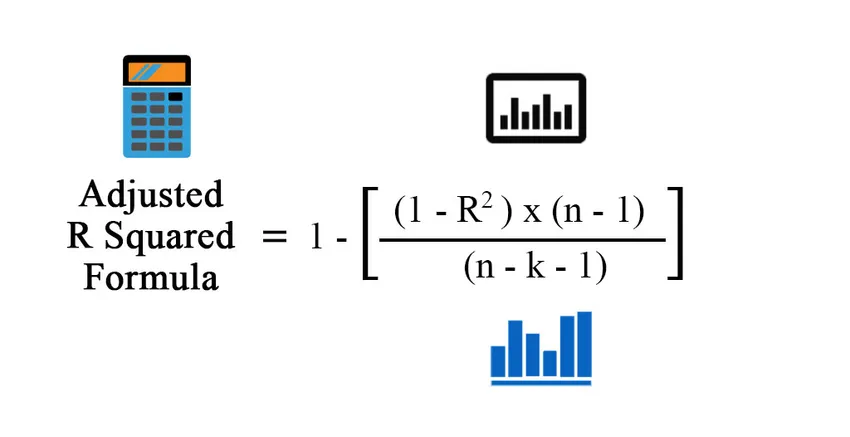
Vzorec pro upravený R na druhou:
Než vypočítáme upravenou r druhou mocninu, potřebujeme nejprve r čtverec. Existují různé způsoby výpočtu r čtverce:
- Použití korelačního koeficientu:
Korelační koeficient = Σ ((X - X m ) * (Y - Y m )) / √ (Σ (X - X m ) 2 * Σ (Y - Y m ) 2 )
Kde:
- X - Datové body v datové sadě X
- Y - Datové body v datové sadě Y
- X m - průměr sady dat X
- Y m - průměr sady dat Y
Tak
R2 = (korelační koeficient) 2
Adjusted R Squared = 1 – (((1 – R 2 ) * (n – 1)) / (n – k – 1))
Kde:
- n - Počet bodů v sadě dat.
- k - Počet nezávislých proměnných v modelu, s výjimkou konstanty
- Použití výstupů regrese
R 2 = Vysvětlená variace / celková variace
R2 = MSS / TSS
R2 = (TSS - RSS) / TSS
Kde:
- TSS - celkový součet čtverců = Σ (Yi - Ym) 2
- MSS - modelový součet čtverců = Σ (Y - Ym) 2
- RSS - Zbytkový součet čtverců = Σ (Yi - Y ^) 2
Y je předpovězená hodnota modelu, Yi je ith hodnota a Ym je střední hodnota
Adjusted R Squared = 1 – (((1 – R 2 ) * (n – 1)) / (n – k – 1))
Příklady upravené vzorce R na druhou (se šablonou Excel)
Vezměme si příklad, abychom lépe porozuměli výpočtu upraveného R na druhou.
Tuto upravenou šablonu R na druhou rovnici Excel si můžete stáhnout zde - Upravenou šablonu R na druhou rovnici ExcelUpravený vzorec R na druhou - příklad # 1
Řekněme, že máme dvě datové sady X a Y a každá obsahuje 20 náhodných datových bodů. Vypočítejte Upravený R na druhou pro datovou sadu X a Y.
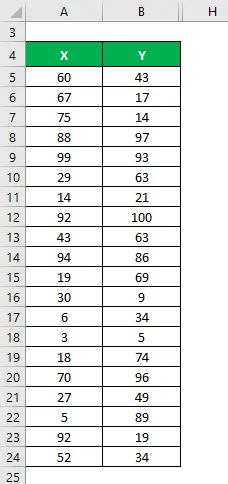
Průměr se počítá jako:
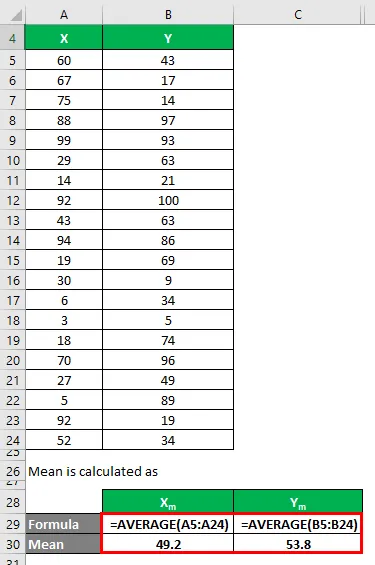
- Průměrná sada dat X = 49, 2
- Průměrná sada dat Y = 53, 8
Nyní musíme vypočítat rozdíl mezi datovými body a střední hodnotou.
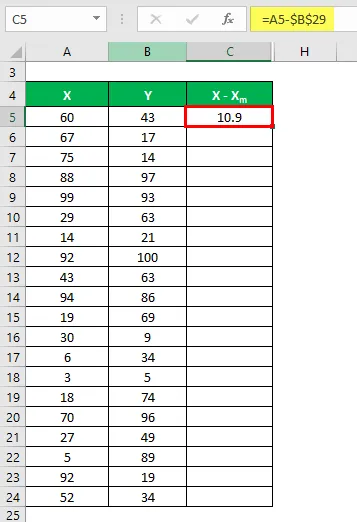
Podobně vypočítat pro všechny datové sady X.
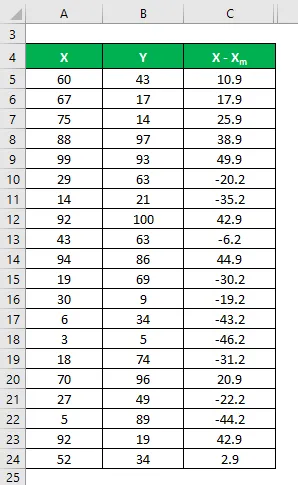
Podobně ji vypočítejte také pro datovou sadu Y.
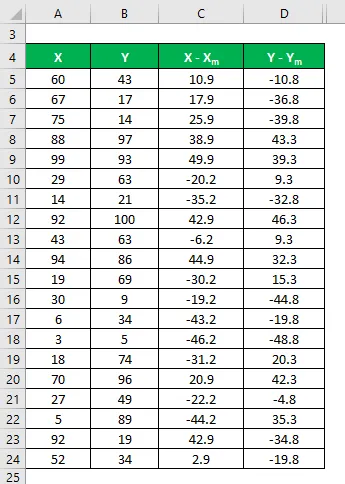
Vypočítejte druhou mocninu rozdílu pro datové sady X a Y.
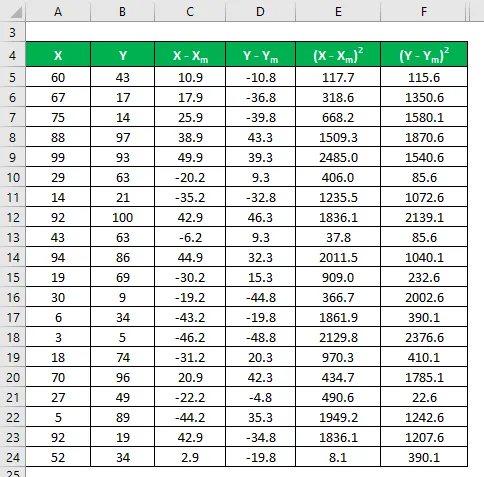
Vynásobte rozdíl v X pomocí Y.
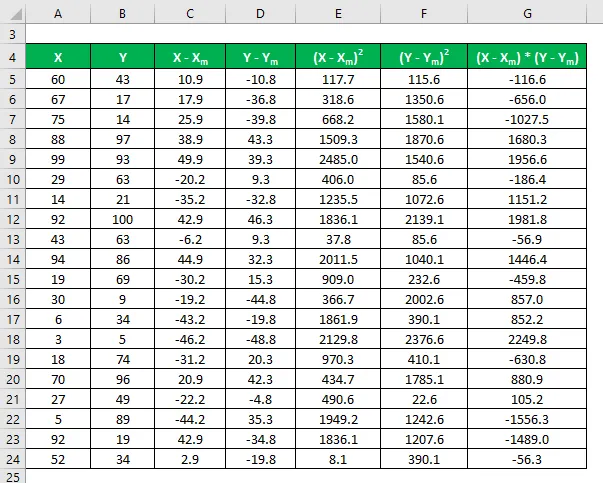
Koeficient korelace se vypočítá pomocí vzorce uvedeného níže
Korelační koeficient = Σ ((X - X m ) * (Y - Y m )) / √ (Σ (X - X m ) 2 * Σ (Y - Y m ) 2 )
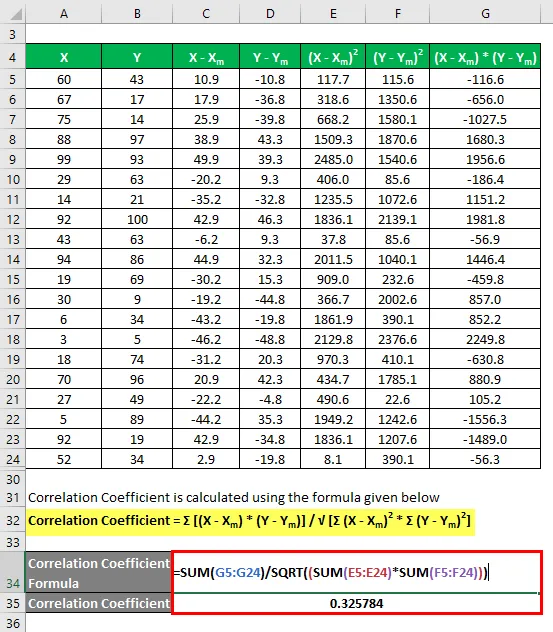
Korelační koeficient = 0, 325784
R2 se vypočítá pomocí vzorce uvedeného níže
R2 = (korelační koeficient) 2
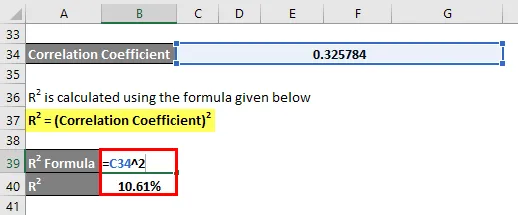
R2 = 10, 61%
Upravený R na druhou se vypočítá pomocí vzorce uvedeného níže
Upravený R na druhou = 1 - (((1 - R2) * (n - 1)) / (n - k - 1))
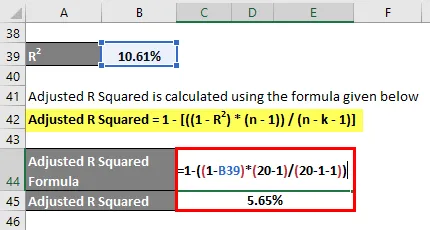
- Upravený R na druhou = 1 - ((1 - 10, 61%) * (20 - 1) / (20 - 1 - 1))
- Upraveno R na druhou = 5, 65%
Upravený vzorec R na druhou - příklad # 2
Použijeme jinou metodu pro výpočet čtverce r a poté upravíme r na druhou. Řekněme, že máte skutečné a předpovídané závislé proměnné hodnoty s sebou (Y a Y ^):
Průměr se počítá jako
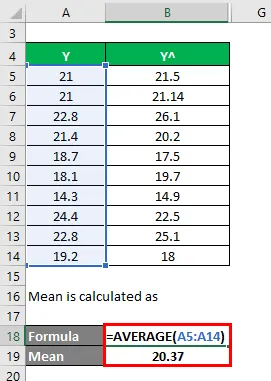
Nyní musíme vypočítat rozdíl mezi skutečnými a predikovanými závislými hodnotami proměnných.
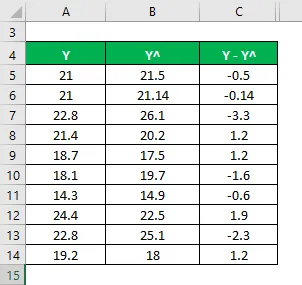
Vypočítejte rozdíl mezi datovými body a střední hodnotou.
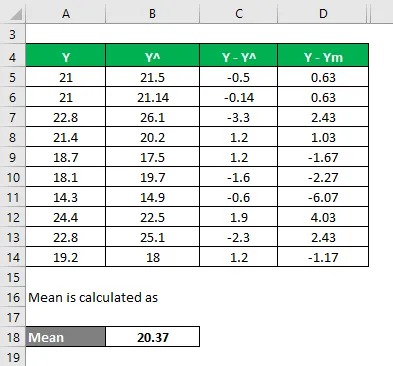
Vypočítejte druhou mocninu rozdílů.
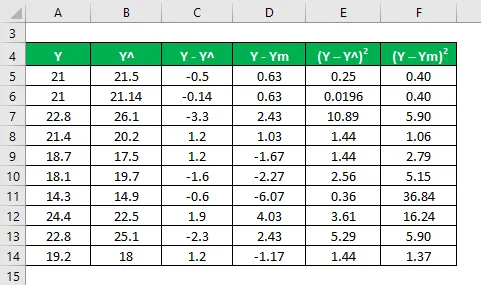
R2 se vypočítá pomocí vzorce uvedeného níže
R2 = (TSS - RSS) / TSS
- TSS = Σ (Y - Ym) 2
- RSS = Σ (Y - Y ^) 2
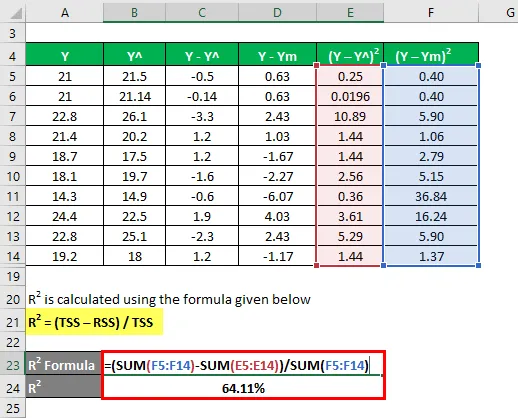
R2 = 64, 11%
Nyní řekněme, že máme 3 nezávislé proměnné: tj. K = 3.
Upravený R na druhou se vypočítá pomocí vzorce uvedeného níže
Upravený R na druhou = 1 - (((1 - R2) * (n - 1)) / (n - k - 1))
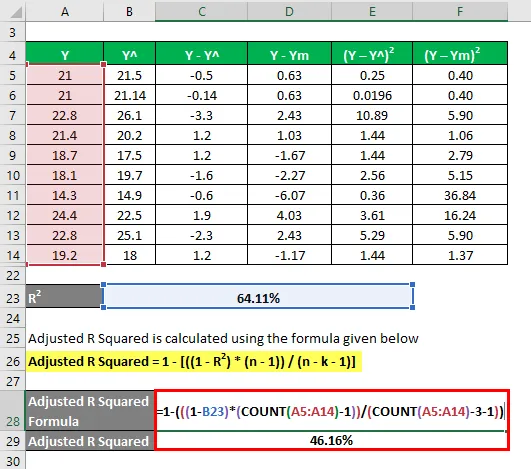
- Upravený R na druhou = 1 - (((1 - 64, 11%) * (10-1)) / (10 - 3 - 1))
- Upraveno R na druhou = 46, 16%
Vysvětlení
R2 nebo Koeficient určení, jak je vysvětleno výše, je čtvercem korelace mezi 2 datovými soubory. Pokud R2 je 0, znamená to, že neexistuje korelace a nezávislá proměnná nemůže předpovídat hodnotu závislé proměnné. Podobně, pokud je jeho hodnota 1, znamená to, že nezávislá proměnná bude vždy úspěšná při předpovídání závislé proměnné. Existují však i určitá omezení. Protože se počet nezávislých proměnných zvyšuje ve statistickém modelu, R2 také zvyšuje, zda tyto nové proměnné mají nebo nemají smysl. To je důvod, proč se vypočte upravené kv na druhou, protože upravuje hodnotu R2 pro toto zvýšení řady proměnných. Upravená hodnota r kvadrát klesá, pokud nezávislá proměnná není významná, a zvyšuje se, pokud má význam.
Relevance a použití upraveného vzorce R na druhou
Upravená r mocnina je užitečnější, když máme více než 1 nezávislé proměnné, protože upravuje r čtverec a bere v úvahu pouze příslušnou nezávislou proměnnou, která ve skutečnosti vysvětluje změnu závislé proměnné. Jeho hodnota je vždy menší než hodnota R2. Obecně existuje mnoho praktických aplikací tohoto nástroje, jako je srovnání výkonnosti portfolia s tržní a budoucí predikcí, modelování rizik v hedgeových fondech atd.
Doporučené články
Toto byl průvodce upraveným vzorcem R na druhou. Zde diskutujeme o tom, jak vypočítat upravený R na druhou spolu s praktickými příklady a šablonou Excel ke stažení. Další informace naleznete také v následujících článcích -
- Příklady vzorce pro kalkulaci absorpce
- Průvodce po vzorci míry finanční páky
- Vzorec pro výpočet ceny dluhopisů
- Binomický distribuční vzorec