
Úvod do těžby textu
Těžba textu - V dnešním kontextu je text nejčastějším prostředkem výměny informací. Ale pochopení významu textu není vůbec snadná práce. Potřebujeme dobrý nástroj obchodní inteligence, který pomůže pochopit informace snadným způsobem.
Co je textová těžba
Těžba textu se také nazývá Text Analytics. Je to proces porozumění informacím ze sady textů. Text Mining je navržen tak, aby pomohl podnikům nalézt cenné znalosti z textového obsahu. Tento obsah může mít podobu textového dokumentu, e-mailu nebo příspěvků na sociálních médiích.
Těžba textu je použití automatizovaných metod pro pochopení znalostí dostupných v textových dokumentech.
Text Mining lze také použít k tomu, aby počítač pochopil strukturovaná nebo nestrukturovaná data. Kvalitativní data nebo nestrukturovaná data jsou data, která nelze měřit pomocí čísel. Tato data obvykle obsahují informace, jako je barva, textura a text. Kvantitativní data nebo strukturovaná data jsou data, která lze snadno měřit.
Těžba textu je interdisciplinární pole, které zahrnuje získávání informací, dolování dat, strojové učení, statistiky a další. Těžba textu je mírně odlišné pole od těžby dat.
Výhody těžby textu
Použití dolování textu má mnoho výhod. Jsou uvedeny níže
- Šetří čas a zdroje a pracuje efektivněji než lidské mozky.
- Pomáhá sledovat názory v průběhu času
- Text Mining pomáhá shrnout dokumenty
- Textová analýza pomáhá extrahovat koncepty z textu a prezentovat jej jednodušším způsobem
- Text indexovaný pomocí dolování textu lze použít v prediktivní analýze
- Chcete-li použít terminologii ve své oblasti zájmu, můžete připojit libovolné slovníky
Použití těžby textu
- Názvy různých entit a vztahy mezi textem lze snadno najít pomocí různých technik.
- Pomáhá extrahovat vzory z velkého množství nestrukturovaných dat
- Systematické prohlížení literatury - Může jít o hloubkový výzkum textu, najít klíčová témata a zdůraznit opakované termíny nebo text a oblíbená témata v průběhu času.
- Testování hypotéz - Těžbou textu lze testovat konkrétní hypotézu, aby se zjistilo, zda dokument hypotézu potvrdí nebo zamítne. Nejprve se v dokumentu nejprve testuje prokázaná víra.
Efektivně vyvinout řešení obchodních problémů. Naučte se definovat, analyzovat a dokumentovat obchodní požadavky. Zkoumejte obchodní činnosti, aby byly efektivnější.
Význam těžby textu
- Text Mining umožňuje lepší a inteligentní rozhodování
- Pomáhá řešit problémy objevování znalostí v různých oblastech podnikání
- Prostřednictvím dolování textu můžete snadno vizualizovat data mnoha způsoby, jako jsou html tabulky, grafy, grafy a další
- Je to skvělý nástroj produktivity. Poskytuje lepší výsledky rychleji než jakýkoli jiný nástroj.
- Nástroj pro dolování textu používají velké i malé organizace, které jsou znalostními organizacemi.
Aplikace těžby textu
-
Analýza odpovědí na otevřené průzkumy
Průzkumné otázky s otevřeným koncem pomohou respondentům vyjádřit svůj názor nebo názor bez jakýchkoli omezení. To pomůže dozvědět se více o názorech zákazníků než se spoléhat na strukturované dotazníky. Těžba textu může být použita k analýze takových informací ve formě textu.
-
Automatické zpracování zpráv, e-mailů
Těžba textu se používá hlavně k klasifikaci textu. Textová těžba může být použita k filtrování zbytečné pošty pomocí určitých slov nebo frází. Takové e-maily automaticky zahodí takové e-maily jako spam. Takový automatický systém klasifikace a filtrování vybraných e-mailů a jejich odeslání příslušnému oddělení se provádí pomocí systému textové těžby. Text Mining také pošle upozornění uživateli e-mailu, aby odstranil e-maily s takovými urážlivými slovy nebo obsahem.
-
Analýza nároků na záruky nebo pojištění
Ve většině obchodních organizací se informace shromažďují hlavně ve formě textu. Například v nemocnici lze rozhovory s pacienty krátce vyprávět v textové podobě a zprávy jsou také ve formě textu. Tyto poznámky se nyní shromažďují elektronicky, takže je lze snadno převést do algoritmů těžby textu. Tyto záznamy pak mohou být použity k diagnostice skutečné situace.
-
Vyšetřování konkurentů procházením jejich webových stránek
Další důležitou oblastí aplikace Text Mining je zpracování obsahu webových stránek v konkrétní doméně. Tímto způsobem systém těžby textu automaticky najde seznam termínů, které se na webu používají. Tímto způsobem lze zjistit nejdůležitější pojmy používané na webových stránkách. Tímto způsobem můžete znát schopnosti konkurentů, které vám mohou pomoci efektivně zajistit podnikání.
Další aplikace Text Mining zahrnují následující
- Business Intelligence
- E Discovery
- Bioinformatika
- Správa záznamů
- Práce na národní bezpečnosti nebo zpravodajských službách
- Sledování sociálních médií
Techniky používané při těžbě textu
V systému těžby textu se používá pět základních technologií. Jsou podrobně diskutovány níže
-
Extrakce informací
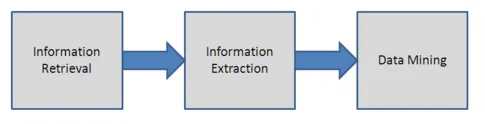
To se používá k analýze nestrukturovaného textu pomocí nalezení důležitých slov a nalezení vztahů mezi nimi. V této technice se používá proces párování vzorů k nalezení pořadí v textu. Pomáhá při transformaci nestrukturovaného textu do strukturované podoby. Technika extrakce informací zahrnuje moduly zpracování jazyka. Většinou se používá tam, kde je velké množství dat. Proces extrakce informací je vysvětlen na obrázku níže.
-
Kategorizace
Technika kategorizace klasifikuje textový dokument do jedné nebo více kategorií. Klasifikace je založena na příkladech vstupních výstupů. Proces kategorizace zahrnuje předběžné zpracování, indexování, zmenšení rozměrů a klasifikaci. Text lze roztřídit pomocí technik, jako je Naive Bayesovský klasifikátor, Rozhodovací strom, Klasifikátor nejbližších sousedů a Stroje prodejců podpory.
-
Shlukování
Metoda klastrování se používá k seskupení textových dokumentů, které mají podobný obsah. Má oddíly zvané klastry a každý oddíl bude mít několik dokumentů s podobným obsahem. Clustering zajišťuje, že z vyhledávání nebude vynechán žádný dokument, a odvozuje všechny dokumenty, které mají podobný obsah. K-znamená je často používanou technikou shlukování. Tato technika také porovná každý klastr a zjistí, jak dobře jsou dokumenty vzájemně propojeny. Společnosti používají tuto techniku k vytvoření databáze s tisíci podobných dokumentů.
-
Vizualizace
Vizualizační technika se používá ke zjednodušení procesu vyhledávání relevantních informací. Tato technika používá textové příznaky k reprezentaci dokumentů nebo skupiny dokumentů a používá barvy k označení kompaktnosti. Vizualizační technika pomáhá zobrazovat textové informace atraktivnějším způsobem. Níže uvedený obrázek bude představovat vizualizační techniku
-
Shrnutí
Sumarizační technika pomůže zkrátit délku dokumentu a stručně shrnout podrobnosti o dokumentech. Díky tomu je pro uživatele dokument čitelný a na první pohled pochopí jeho obsah. Sumarizace nahrazuje celou sadu dokumentů. Snadno a rychle shrnuje velké textové dokumenty. Lidé potřebují více času na přečtení a shrnutí dokumentu, ale tato technika je velmi rychlá. Pomáhá zvýraznit hlavní body v dokumentu. Sumarizační proces je znázorněn na obrázku níže.
Metody a modely používané při těžbě textu
Na základě vyhledávání informací má Těžba textu čtyři hlavní metody
-
Metoda založená na termínu (TBM)
Termín v dokumentu znamená slovo, které má sémantický význam. V této metodě je celá skupina dokumentů analyzována na základě termínu. Jednou z hlavních nevýhod této metody je problém synonymie a polysémie. Synonymie je místo, kde více slov má stejný význam. Polysemy je místo, kde jediné slovo má více významů.
-
Metoda založená na frázi (PBM)
V této metodě je dokument analyzován na základě frází, které jsou méně zřejmé pro více významů a více diskriminační. Nevýhody této metody zahrnují
- Mají nižší statistické vlastnosti než termíny
- Mají nízkou frekvenci výskytu
- Mají velké množství hlučných frází
-
Metoda založená na konceptu (CBM)
V této metodě je dokument analyzován na základě věty a úrovně dokumentu. V této metodě existují tři hlavní složky. První složka zkoumá smysluplnou část vět. Druhá složka vytváří koncepční ontologický graf, který vysvětluje struktury. Třetí komponenta extrahuje nejlepší koncepty založené na prvních dvou komponentách. Tato metoda může rozlišovat mezi důležitými a nedůležitými slovy.
-
Metoda taxonomie vzoru (PTM)
V této metodě je dokument analyzován na základě vzorů. Vzory v dokumentu lze nalézt pomocí technik dolování dat, jako je dolování asociačních pravidel, sekvenční dolování vzorů, častá těžba sad položek a dolování uzavřených vzorů. Tato metoda používá dva procesy - nasazení a vývoj vzorů. Ukázalo se, že tato metoda funguje lépe než všechny ostatní modely nebo metody.
Jak funguje těžba textu
Nyní byste měli pochopit, že těžba textu umožňuje lépe porozumět textu než cokoli jiného. Systém dolování textu umožňuje výměnu slov z nestrukturovaných dat do číselných hodnot. Dolování textu pomáhá identifikovat vzory a vztahy, které existují ve velkém množství textu. Těžba textu často používá výpočetní algoritmy ke čtení a analýze textových informací. Bez těžby textu bude obtížné porozumět textu snadno a rychle. Text lze těžit systematičtějším a komplexnějším způsobem a informace o firmě lze zaznamenávat automaticky. Kroky v procesu těžby textu jsou uvedeny níže.
-
Krok 1: Získání informací
Toto je první krok v procesu těžby dat. Tento krok zahrnuje pomoc vyhledávače k nalezení kolekce textu známého také jako korpus textů, který může vyžadovat určitou konverzi. Tyto texty by také měly být spojeny do určitého formátu, který bude pro uživatele užitečný. Obvykle je XML standardem pro dolování textu
-
Krok 2: Zpracování přirozeného jazyka
Tento krok umožňuje systému provádět gramatickou analýzu věty pro čtení textu. Analyzuje také text ve strukturách.
-
Krok 3: Extrakce informací
Toto je druhá fáze, ve které se provádí identifikace významu určité textové přirážky. V této fázi jsou do databáze přidána metadata o textu. To také zahrnuje přidání názvů nebo umístění do textu. Tento krok umožňuje vyhledávači získat informace a zjistit vztahy mezi texty pomocí jejich metadat.
-
Krok 4: Dolování dat
Poslední fází je dolování dat pomocí různých nástrojů. Tento krok najde podobnosti mezi informacemi, které mají stejný význam, který bude jinak obtížné najít. Text Mining je nástroj, který podporuje výzkumný proces a pomáhá testovat dotazy.
Těžba textu obsahuje následující seznam prvků
- Kategorizace textu
- Shlukování textu
- Extrakce koncepce / entity
- Granulární taxonomie
- Analýza sentimentu
- Shrnutí dokumentů
- Modelování vztahů entit
Výzvy v těžbě textu
Hlavní výzvou, jíž čelí systém Text Mining, je přirozený jazyk. Přirozený jazyk čelí problému dvojznačnosti. Dvojznačnost znamená jeden termín, který má několik významů, jedna věta je interpretována různými způsoby a výsledkem jsou různé významy.
Dalším omezením je, že při používání systému extrakce informací zahrnuje sémantickou analýzu. Z tohoto důvodu není celý text prezentován uživatelům, pouze omezená část textu je prezentována uživatelům. Ale v dnešní době je potřeba více porozumět textu.
Text Mining má také omezení s právními předpisy o autorských právech. Při těžbě textu existuje mnoho omezení. Většinou zahrnuje práva držitelů autorských práv. Většina textů nebude nalezena jako otevřený zdroj a v takových případech jsou vyžadována povolení od příslušných autorů, vydavatelů a dalších souvisejících stran.
Dalším omezením je těžba textu, která negeneruje nová fakta a není ukončovacím procesem.
Závěr
Těžba textu nebo analýza textu je prosperující technologie, ale výsledky a hloubka analýzy se v jednotlivých firmách liší. Organizace může pomocí těžby textu získat znalosti o hodnotách specifických pro obsah.