
Úvod do zpětné eliminace
Vzhledem k tomu, že člověk a stroj klepe na digitální evoluci, účtují se různé techniky, aby se nejen vyškolili, ale také inteligentně vyškolili, aby vyšli s lepším rozpoznávání skutečných objektů. Taková technika zavedená dříve nazývaná „zpětná eliminace“, která měla v úmyslu upřednostnit nepostradatelné funkce, zatímco vymýcení nepotřebných funkcí umožnilo lepší optimalizaci stroje. Celá odbornost rozpoznávání objektů strojem je úměrná tomu, jaké vlastnosti zvažuje.
Prvky, které nemají žádný odkaz na předpokládaný výkon, musí být ze stroje vybity a jsou ukončeny zpětným vyloučením. Dobrá přesnost a časová složitost rozpoznávání jakéhokoli skutečného slovního objektu strojem závisí na jeho učení. Takže zpětné odstranění hraje svou rigidní roli při výběru prvků. Počítá míru závislosti funkcí na závislé proměnné a zjistí význam její příslušnosti k modelu. Aby to bylo akreditováno, zkontroluje vypočítanou sazbu se standardní hladinou významnosti (řekněme 0, 06) a rozhodne o výběru funkce.
Proč získáváme zpětné odstranění ?
Nezbytné a nadbytečné rysy pohánějí složitost logiky stroje. Zbytečně ztrácí čas a prostředky modelu. Uvedená technika tedy hraje kompetentní roli k vytvoření jednoduchého modelu. Algoritmus kultivuje nejlepší verzi modelu optimalizací jeho výkonu a zkrácením jeho spotřebovatelných určených zdrojů.
Zkrátí nejmenší pozoruhodné vlastnosti modelu, které způsobují hluk při rozhodování o regresní linii. Nerelevantní vlastnosti objektu mohou vést k nesprávné klasifikaci a predikci. Nerelevantní rysy účetní jednotky mohou představovat nerovnováhu v modelu s ohledem na další významné rysy jiných objektů. Zpětná eliminace podporuje přizpůsobení modelu nejlepšímu případu. Proto se v modelu doporučuje použití zpětné eliminace.
Jak použít zpětné odstranění?
Zpětná eliminace začíná u všech proměnných funkcí a testuje ji závislou proměnnou podle vybraného kritéria kritéria modelu. Začíná eradikovat ty proměnné, které zhoršují montážní linii regrese. Opakování tohoto odstranění, dokud model nedosáhne dobré kondice. Níže jsou uvedeny kroky k praktikování zpětného odstranění:
Krok 1: Vyberte vhodnou úroveň významnosti, která se nachází v modelu stroje. (Vezměte S = 0, 06)
Krok 2: Vložte všechny dostupné nezávislé proměnné do modelu s ohledem na závislou proměnnou a vytvořte na počítači sklon a zastavte tak, aby nakreslil regresní nebo montážní linii.
Krok 3: Projděte se všemi nezávislými proměnnými, které mají nejvyšší hodnotu (Take I) jeden po druhém a pokračujte následujícím přípitkem: -
a) Pokud I> S, proveďte 4. krok.
b) Jinak přerušíme a model je perfektní.
Krok 4: Odstraňte vybranou proměnnou a zvyšte průchod.
Krok 5: Znovu kujte model a vypočítejte sklon a protnutí montážní linie znovu se zbytkovými proměnnými.
Výše uvedené kroky jsou shrnuty v odmítnutí těch znaků, jejichž míra významnosti je vyšší než vybraná hodnota významnosti (0, 06), aby se zabránilo nadtriedení a nadužití zdrojů, které byly pozorovány jako vysoká složitost.
Přednosti a nedostatky zpětného vyloučení
Zde jsou některé zásluhy a nedostatky zpětného vyloučení, které jsou podrobně uvedeny níže:
1. Přednosti
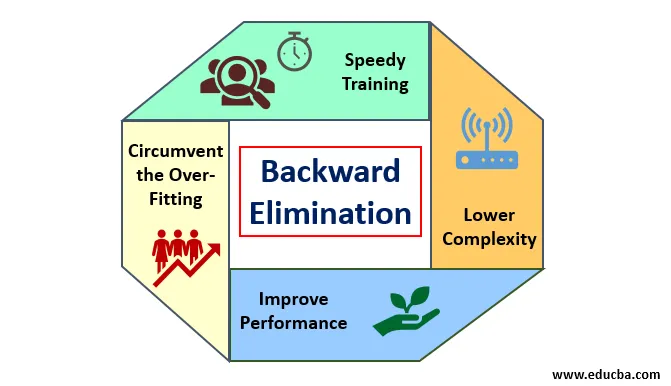
Přednosti zpětného vyloučení jsou následující:
- Rychlý trénink: Stroj je vyškolen se sadou dostupných funkcí vzoru, která se provádí ve velmi krátké době, pokud jsou z modelu odstraněny nepodstatné prvky. Rychlé školení sady dat přichází do obrazu pouze tehdy, když se model zabývá významnými vlastnostmi a vylučuje všechny proměnné šumu. Pro trénink to přináší jednoduchou složitost. Model by však neměl podléhat nedostatečné montáži, ke které dochází z důvodu chybějících znaků nebo nedostatečných vzorků. Vzorový prvek by měl být hojný v modelu pro nejlepší klasifikaci. Čas potřebný pro trénink modelu by měl být kratší při zachování přesnosti klasifikace a ponechán bez proměnné pod predikcí.
- Nižší složitost: Složitost modelu je vysoká, pokud model uvažuje o rozsahu funkcí včetně šumu a nesouvisejících prvků. Model potřebuje tolik prostoru a času na zpracování takového rozsahu funkcí. To může zvýšit rychlost přesnosti rozpoznávání vzorů, ale rychlost může také obsahovat šum. Aby se zbavil tak vysoké složitosti modelu, hraje algoritmus zpětné eliminace nezbytnou roli tím, že načte nežádoucí prvky z modelu. Zjednodušuje logiku zpracování modelu. Pouze několik základních rysů je dostačujících k tomu, aby dobře přiléhaly a uspokojovaly přiměřenou přesnost.
- Zlepšit výkon: Výkon modelu závisí na mnoha aspektech. Model prochází optimalizací pomocí zpětné eliminace. Optimalizace modelu je optimalizace datového souboru použitého pro trénink modelu. Výkon modelu je přímo úměrný jeho rychlosti optimalizace, která závisí na frekvenci významných dat. Záměrem procesu zpětné eliminace není zahájit změnu z jakéhokoli nízkofrekvenčního predikátoru. Začíná však pouze změna vysokofrekvenčních dat, protože složitost modelu závisí hlavně na této části.
- Obejít nadměrnou montáž: K nadměrné montáži dochází, když má model příliš mnoho datových sad a provádí se klasifikace nebo predikce, ve kterých někteří prediktoři dostali hluk jiných tříd. V této montáži měl model poskytovat nečekaně vysokou přesnost. V přesahu může model selhat při klasifikaci proměnné kvůli záměně vytvořené v logice kvůli příliš mnoha podmínkám. Technika zpětné eliminace omezuje vnější prvek, aby se zabránilo situaci nadměrného osazení.
2. Demerity
Nevýhody zpětného vyloučení jsou následující:
- V metodě zpětné eliminace nelze zjistit, který prediktor je odpovědný za odmítnutí jiného prediktoru kvůli jeho dosažení bezvýznamnosti. Například, má-li prediktor X nějaký význam, který byl dost dobrý, aby zůstal v modelu po přidání predikátoru Y. Ale význam X je zastaralý, když do modelu vstoupí další prediktor Z. Algoritmus zpětné eliminace tedy není zřejmý o žádné závislosti dvou prediktorů, k nimž dochází v „technice výběru vpřed“.
- Po vyřazení kteréhokoli prvku z modelu zpětným eliminačním algoritmem nemůže být tento prvek znovu vybrán. Stručně řečeno, zpětná eliminace nemá flexibilní přístup k přidávání nebo odebírání prvků / prediktorů.
- Normy pro výběr hodnoty významnosti (0, 06) v modelu jsou nepružné. Zpětná eliminace nemá flexibilní postup, který umožňuje nejen vybrat, ale také změnit nevýznamnou hodnotu podle potřeby, aby se dosáhlo nejlepšího výsledku v odpovídajícím souboru dat.
Závěr
Technika zpětné eliminace realizovaná za účelem zlepšení výkonu modelu a optimalizaci jeho složitosti. Živě se používá v několika regresích, kde se model zabývá rozsáhlým souborem dat. Je to snadný a jednoduchý přístup ve srovnání s předním výběrem a křížovou validací, při které došlo k přetížení optimalizace. Technika zpětné eliminace iniciuje eliminaci prvků s vyšší významnou hodnotou. Jeho základním cílem je učinit model méně složitým a zakázat překrývání situace.
Doporučené články
Toto je průvodce zpětným vyloučením. Zde diskutujeme o tom, jak aplikovat zpětné odstranění spolu se zásluhami a nedostatky. Další informace naleznete také v následujících článcích
- Hyperparametrické strojové učení
- Shlukování ve strojovém učení
- Virtuální stroj Java
- Strojové učení bez dozoru