

Úvod do XPath
XPath je hlavní a základní součást standardu XSLT. XPath lze použít k procházení prvků, atributů, textu, zpracování instrukcí, komentářů, jmenného prostoru a dokumentu v dokumentu XML (Extensible Markup Language). Jedná se o doporučení W3C, které obsahuje knihovnu s více než 200 vestavěnými funkcemi. XPath je syntaxe pro definování částí dokumentu XML. XSLT je jazyk stylů pro soubory XML. S XSLT můžete transformovat XML dokumenty do jiných formátů, jako je XHTML. XQuery je o dotazování na data XML. XQuery je navržen tak, aby dotazoval na vše, co se může objevit jako XML, včetně databází. Propojení v XML je rozděleno na dvě části: XLink a XPointer. XLink a XPointer definují standardní způsob vytváření hypertextových odkazů v XML dokumentech.
Vyjádření XPath
XPath umožňuje různým typům výrazů získat relevantní informace z dokumentu XML. XPath řeší konkrétní část dokumentu. Moduluje dokument XML jako strom uzlů. Výraz XPath je technika pro procházení a výběr uzlů z dokumentu.
Výrazy XPath lze použít v jazycích C, C ++, Python, Java, JavaScript, PHP, XML Schema a v mnoha dalších jazycích. Výraz XPath odkazuje na vzor pro výběr sady uzlů. XPointer tyto vzory používá pro účely adresování nebo k provedení transformací pomocí XSLT. Výraz XPath určuje sedm typů uzlů, které mohou být výsledkem provádění.
1. Kořen
Kořenový prvek XML dokumentu. Následující způsoby najdou kořenové prvky.
- Použít zástupný znak (/ *): Výběr kořenového uzlu
- Použít název (/ třída): Výběr kořenového uzlu podle názvu
- Použít jméno s zástupným znakem (/ class / *): Výběr všech prvků v kořenovém uzlu
Kód:
2. Prvek
Uzel prvku dokumentu XML. Níže jsou uvedeny způsoby, jak najít prvek
- / class / *: slouží k výběru všech prvků v kořenovém uzlu.
- / class / library: slouží k výběru všech prvků knihovny z kořenového uzlu.
- // library: slouží k výběru celého prvku knihovny z dokumentu.
Kód:
3. Atributy
Atribut uzlu prvku v dokumentu XML načtený a zkontrolovaný pomocí @ attribute-name elementu.
Kód:
4. Text
Text uzlu prvku v dokumentu XML, načtený a zkontrolovaný podle názvu prvku.
Kód:
5. Komentář
Příklad komentáře
Kód:
Uzel nebo seznam uzlu z XML
Následuje seznam užitečných výrazů pro výběr uzlu nebo seznamu uzlu z dokumentu XML.
- '/': Použití tohoto výběru začíná z kořenového uzlu.
- '//': Použití tohoto výběru začíná od aktuálního uzlu, který odpovídá výběru
- '.': Pro výběr aktuálního použitého výrazu.
- '..': Výběr nadřazeného uzlu aktuálního uzlu.
- '@': Výběr atributů.
Příklad XPath
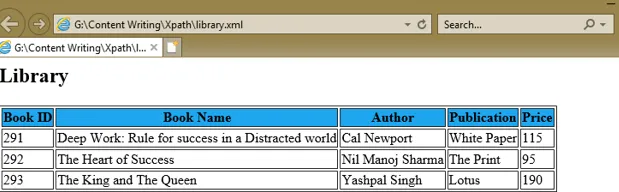
Abychom porozuměli výrazu XPath, vytvořili jsme dokument XML, library.xml a jeho list stylů document library.xsl, který používá výrazy XPath pod atributem select různých značek XSL k získání hodnot id knihy, názvu knihy, autor, publikace a cena každého uzlu knihy.
1. library.xml
Kód:
Deep Work: Rule for success in a Distracted world
Cal Newport
White Paper
115
The Heart of Success
Nil Manoj Sharma
The Print
95
The King and The Queen
Yashpal Singh
Lotus
190
2. library.xsl
Kód:
xmlns:xsl = "http://www.w3.org/1999/XSL/Transform">
Library
Book ID
Book Name
Author
Publication
Price
xmlns:xsl = "http://www.w3.org/1999/XSL/Transform">
Library
Book ID
Book Name
Author
Publication
Price
xmlns:xsl = "http://www.w3.org/1999/XSL/Transform">
Library
Book ID
Book Name
Author
Publication
Price
xmlns:xsl = "http://www.w3.org/1999/XSL/Transform">
Library
Book ID
Book Name
Author
Publication
Price
xmlns:xsl = "http://www.w3.org/1999/XSL/Transform">
Library
Book ID
Book Name
Author
Publication
Price
| | | | |
|---|---|---|---|---|
xmlns:xsl = "http://www.w3.org/1999/XSL/Transform">
Library
Book ID
Book Name
Author
Publication
Price
Výstup:
Výhody XPath
Výhody Xpath jsou níže:
- Dotazy XPath lze snadno psát a číst a také jsou kompaktní.
- Syntaxe XPath je pro běžné a jednoduché případy snadná.
- Řetězce dotazů jsou snadno vloženy do skriptů, programů a atributů HTML nebo XML.
- Dotazy XPath lze snadno analyzovat.
- Každý dokument může v dokumentu XML jednoznačně rozpoznat.
- V dokumentu XML lze určit výskyt jakékoli cesty nebo jakékoli sady podmínek pro uzly v cestě.
- Dotazy vracejí libovolný počet výsledků, včetně nuly.
- V dokumentu XML lze podmínky dotazu vypočítat na jakékoli úrovni a neměly by procházet z horního uzlu dokumentu XML.
- Dotazy XPath vracejí jedinečné uzly, ne opakované uzly.
- V mnoha kontextech se XPath používá k poskytování odkazů na uzly, k nalezení úložišť a mnoha dalších aplikací.
- Pro programátory nejsou dotazy XPath procedurální, ale deklarativnější. Definují, jak mají být prvky procházeny. Aby bylo možné dosáhnout efektivních výsledků, musí být optimalizátory dotazů používány zdarma indexy a další struktury.
Závěr
XPath je jazyk dotazu používaný k procházení elementů, atributů, textu skrz dokument XML. XPath je široce používán k nalezení konkrétních prvků nebo atributů s odpovídajícími vzory. Když je definován dotaz, pak mohou být data XML reprezentována jako strom. Hierarchická reprezentace dat XML se nazývá strom. Horní část stromu je kořenový uzel. Ve stromu odpovídá každý atribut, prvky, text, komentáře, řetězec a instrukce zpracování jednomu uzlu. Vztahy mezi uzly mohou být reprezentovány stromem.
Doporučené články
Toto je průvodce Co je XPath ?. Zde diskutujeme výraz, seznam, příklady a výhody Xpath. Další informace naleznete také v dalších souvisejících článcích.
- Co je XPath v selenu?
- Co je to XML?
- Nová kariérní cesta
- Pracovní cesta informační bezpečnosti
- Příklady vestavěných funkcí Pythonu