
Úvod do Hive Group By
Seskupit podle, jak název napovídá, seskupí záznam, který splňuje určitá kritéria. V tomto článku se podíváme na skupinu HIVE. Ve starších RDBMS, jako je MySQL, SQL atd., Je skupina podle jedné z nejstarších používaných klauzulí. Nyní si našlo své místo podobným způsobem v ukládání dat na základě souborů, které je známé jako HIVE.
Víme, že Úl překonal mnoho starých RDBMS při manipulaci s obrovskými daty, aniž by se utratila centy za prodejce za údržbu databází a serverů. Potřebujeme pouze nakonfigurovat HDFS, aby zvládl úl. Obecně se přesuneme do tabulek, protože koncový uživatel může interpretovat ze své struktury a může dotazovat, protože soubory pro ně budou nemotorné. Museli jsme to však udělat tak, že prodejcům zaplatili za poskytování serverů a udržování našich dat ve formátu tabulek. Úl tedy poskytuje nákladově efektivní mechanismus, kde využívá výhod systémů založených na souborech (způsob, jakým úl ukládá svá data), jakož i tabulek (struktura tabulek pro koncové uživatele, na které se mohou ptát).
Skupina vytvořená
Seskupit data pomocí definovaných sloupců z tabulky Úl. Například, zvažte, že máte tabulku s údaji ze sčítání lidu ze všech měst všech států, kde název města a název státu je jedním ze sloupců. Nyní v dotazu, pokud budeme seskupovat podle států, budou všechna data z různých měst určitého státu seskupena dohromady a jeden může snadno vizualizovat data lépe nyní před tím, než byla použita skupina podle.
Syntaxe Hive Group By
Obecná syntaxe skupiny podle klauzule je následující:
SELECT (ALL | DISTINCT) select_expr, select_expr, …
FROM table_reference
(WHERE where_condition) (GROUP BY col_list) (HAVING having_condition) (ORDER BY col_list)) (LIMIT number);
nebo pro jednodušší dotazy,
from Group By
Select department, count(*) from the university.college Group By department;
Zde se katedra odkazuje na jeden ze sloupců vysokoškolské tabulky, který je přítomen v univerzitní databázi, a jeho hodnota je různá na katedrách jako je umění, matematika, strojírenství atd. Nyní se podívejme na ukázku skupiny, kterou lze demonstrovat.
Vytvořil jsem ukázkovou tabulku deck_of_cards, abych demonstroval skupinu. Jeho příkaz vytvořit tabulku je následující:
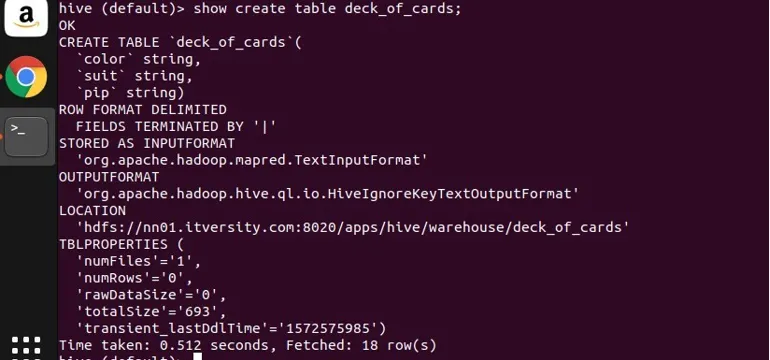
můžete vidět shora, že má tři sloupce barvy barvy, barvy a pip. Dovolte mi napsat dotaz, aby se data seskupila podle barvy a získala se její počet.
select color, count(*) from deck_of_cards group by color;
Úl v podstatě vezme výše uvedený dotaz a převede jej do programu pro zmenšení mapy generováním odpovídajícího kódu java a souboru jar a poté provede. Tento proces může chvíli trvat, ale ve srovnání s tradičními RDBMS určitě zvládne velká data. Viz níže uvedený screenshot s podrobným protokolem pro provedení výše uvedeného dotazu.
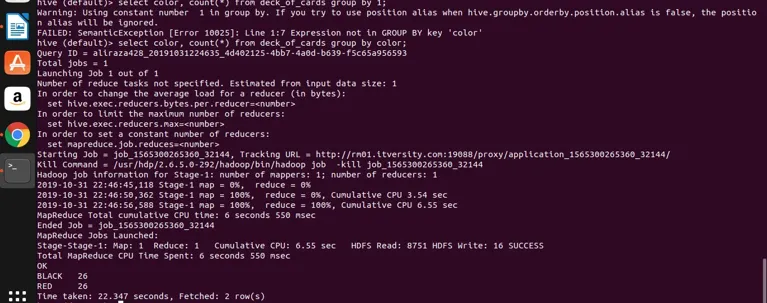
můžete vidět, že BLACK je 26 a RED je 26.
Nyní použijeme seskupení na dva sloupce (barva a barvy a získání počtu skupin) a podívejte se na výsledek níže.
Select color, suit, count(*) from deck_of_cards group by color, suit
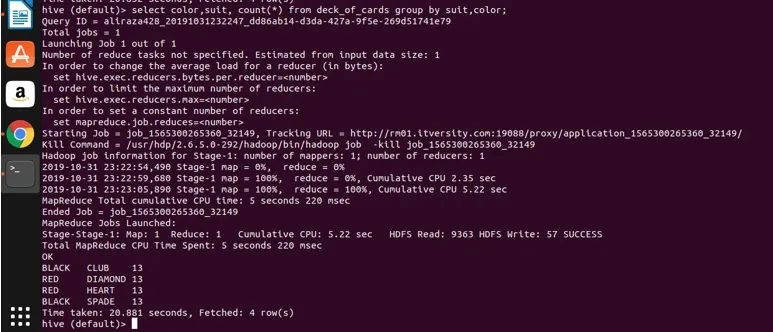
V zásadě existují čtyři odlišné skupiny nad klubem Spade, které mají černou barvu a Diamond a srdce červené.
Uložení výsledku ze skupiny podle příčiny v jiné tabulce
Úl také, jako každý jiný RDBMS, nabízí funkci vkládání dat pomocí příkazů vytváření tabulek. Podívejme se na uložení výsledku z vybraného výrazu pomocí skupiny do jiné tabulky. Dovolte mi použít výše uvedený dotaz sám, pokud jsem použil dva sloupce ve skupině podle.
create table cards_group_by
as
select color, suit, count(*) from deck_of_cards
group by color, suit;
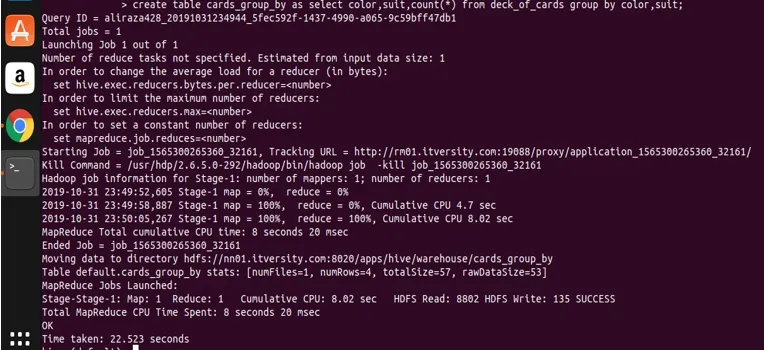
Nyní se pokusíme vytvořit vytvořenou tabulku a zobrazit a ověřit data.

Nyní omezme výsledek skupiny pomocí klauzule. Jak je ukázáno v obecné syntaxi, můžeme na skupinu použít omezení pomocí. Zde používám tabulku ordser_items a její struktura je následující z popisu.
hive (retail_db_ali)> describe order_items;
OK
order_item_id int
order_item_order_id int
order_item_product_id int
order_item_quantity tinyint
order_item_subtotal float
order_item_product_price float
Time taken: 0.387 seconds, Fetched: 6 row(s)
select order_item_id, order_item_order_id from order_items group by order_item_id, order_item_order_id having order_item_order_id=5;
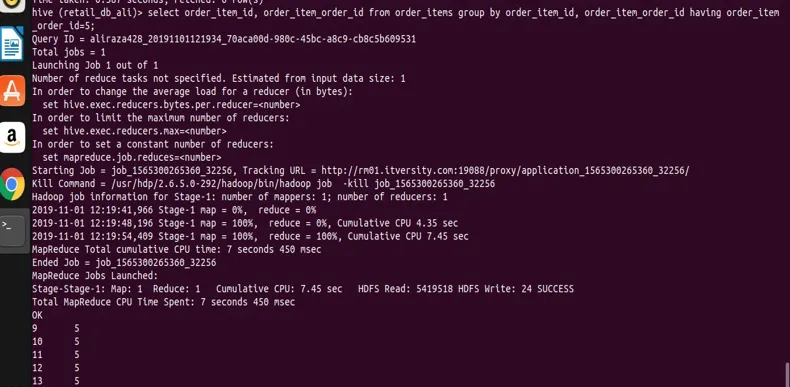
z výsledku vidíte snímek obrazovky, který máme pouze s hodnotou order_item_order_id 5.
Seskupte společně s případem
Nyní se podívejme na složité dotazy týkající se příkazů CASE se skupinou. Použijeme to na tabulku order_items. Uvidíme níže, že můžeme kategorizovat neagregující sloupce, na které nemůžeme skupinu přímo použít.
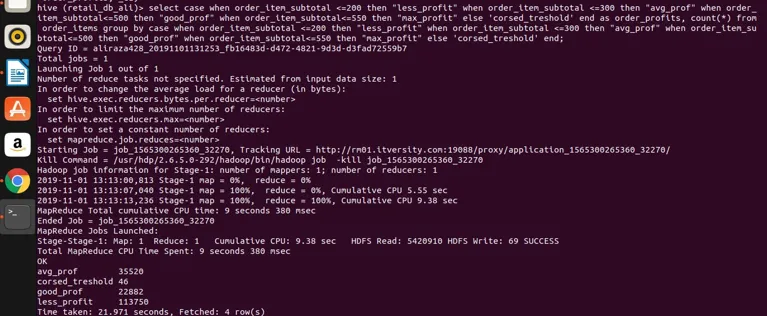
Select
case
when order_item_subtotal <=200 then "less_profit"
when order_item_subtotal <=300 then "avg_prof"
when order_item_subtotal<=500 then "good_prof"
when order_item_subtotal<=550 then "max_profit"
else 'corsed_treshold'
end
as order_profits,
count(*) from order_items
group by
case
when order_item_subtotal <=200 then "less_profit"
when order_item_subtotal <=300 then "avg_prof"
when order_item_subtotal<=500 then "good_prof"
when order_item_subtotal<=550 then "max_profit"
else 'corsed_treshold'
end;
nechme to provést v úlu, abychom dosáhli výsledků
Závěr - Hive Group By
takže vidíme, že jsme seskupili order_item_subtotal do čtyř různých kategorií (pokud si všimnete, že order_item_subtotal je neagregační sloupec a přímá skupina podle toho nelze použít) a my jsme je seskupili dohromady a také jsme za ně započítali hodnoty, které splňují rozsah definovaný ve vybraném výrazu. Zde je jednoduché pravidlo, pokud je sloupec neagregující a náš výběrový výraz je složitý, pak cokoli, co existuje ve výběrovém výrazu, které by mělo být také přítomno ve skupině výrazem klauzule. Viděli jsme, jak lze slavnou klauzuli RDBMS klauzule použít také na Úlu bez jakýchkoli omezení. Lze ji použít na jednoduché vybrané výrazy. Agregovat a filtrovat výrazy, spojovat výrazy a také komplexní CASE výrazy.
Doporučené články
Toto je průvodce Hive Group By. Zde diskutujeme o skupině podle syntaxe, příkladů skupiny úlu s různými podmínkami a implementací. Další informace naleznete také v následujících článcích -
- Připojí se v Úlu
- Co je Úl?
- Architektura úlu
- Funkce úlu
- Hive Order By
- Instalace podregistru
- Top 6 typů spojení v MySQL s příklady