

Úvod do Hashingu v DBMS
Když mluvíme o obrovské struktuře databáze a jejich složitosti, je velmi neefektivní hledat všechny indexy a dosahování požadovaných dat je velmi neurčité a komplexní možnost. Použitím hashovací techniky lze těchto stavů dosáhnout a přímému ukazateli lze přiřadit přesné a přímé umístění na disku pro konkrétní záznam, aniž by se použila složitá indexová struktura. Data v případě hashovací techniky jsou uložena ve formě datových bloků, jejichž adresa je generována použitím funkce obvykle známé jako hashovací funkce. Umístění v paměti, kde je uloženo a jsou uloženy záznamy, se nazývá datové bloky nebo datová skupina.
Typy hašování v DBMS
V DBMS jsou obvykle dva typy hashovací techniky:
1. Statické hasení
2. Dynamické hašování
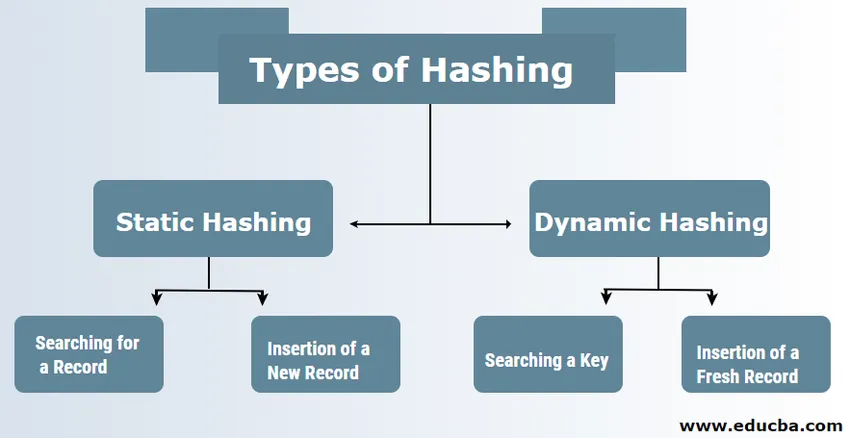
1) Statické hasení
V případě statického hašování se vytvoří datová sada a adresa v kbelíku je stejná. To znamená, že pokud se pokusíme vygenerovat adresu pro USER_ID = 113 pomocí modulu hashovací funkce 5, pak nám vždy poskytne výsledek jako 3 se stejnou vypadající adresou kbelíku. V takovém případě nedojde ke změně adresy poskytovaného kbelíku. Počet kbelíků proto zůstává během operace konstantní.
Provoz staticky typizovaného hasicího systému
A. Hledání záznamu: Pokud je potřeba najít záznam, pak se použije stejná hashovací funkce k načtení adresy a cesty datového bloku s uloženými daty.
b. Vložení nového záznamu: Pokud je nový a čerstvý záznam vložen do tabulky, vygeneruje se adresa pro nový záznam na základě hashovacího klíče, čímž se záznam uloží na toto místo.
- Vymazání záznamu: Aby byl záznam vymazán, musí být nejprve vyvolán záznam, který lze vymazat. Jakmile je tato úloha dokončena, musí být pro tuto paměťovou adresu záznamy odstraněny.
- Aktualizace záznamu: Abychom mohli aktualizovat záznam, nejprve jej prohledáme pomocí funkce založené na hašiši a jakmile je to provedeno, lze náš datový záznam označit jako aktualizovaný. Abychom mohli do souboru vložit nový záznam a adresa, která je generována pomocí hašovací funkce a datového bloku, není prázdná, nebo pokud jsou data již na zadané adrese. Tato situace, která nastává zejména v případě statického hašování, se dá lépe nazvat přetečením kbelíku, a proto existuje několik způsobů, jak tento problém překonat, například:
(i) Open Hashing: Pokud hashovací funkce vygeneruje adresu, na kterou lze data vidět již v uloženém stavu, v tomto případě bude automaticky přidělena další úroveň kbelíku. Tento mechanismus lze označit za techniku lineárního snímání.
Například, pokud R3 je nová adresa, kterou je třeba vložit, pak funkce založená na hašiši vygeneruje adresu jako číslo 102 pro R3 adresu. Generovaná adresa je v plném stavu, a proto je systém určen k hledání nového datového bloku, který je 113, a přiřazení R3 k tomuto datovému bloku.
(ii) Uzavřené hašování: Když jsou kbelíky zcela plné, je pro konkrétní výsledek hašování přidělen nový kbelík, který je spojen hned po tom, co bylo dokončeno dříve, a proto se tato metoda nazývá technikou přetečení řetězu.
Například R3 je nová adresa, která se má vložit do nové tabulky, hashovací funkce se používá ke generování adresy jako číslo 110. Tento kbelík je zase plný, a proto nemůže přijímat nová data, a proto je nový kbelík vložen na konec po 100.
2) Dynamic Hashing
Tuto metodu založenou na hašování lze použít k vyřešení základních problémů hašování založeného na statické elektřině, jako jsou ty, jako je přetečení kbelíku, protože datové kbelíky mohou růst a zmenšovat se s velikostí, že se jedná o techniku optimalizovanou na více prostoru, a proto se nazývá rozšiřitelný hašovací metoda. V této metodě je hašování dynamické, což znamená, že aktivita vložení nebo vymazání jsou povoleny, aniž by došlo k nedostatečnému výkonu.
A. Hledání klíče: Vypočítejte hašovací adresu požadovaného klíče a zkontrolujte počet bitů, které se používají v případě adresáře známého jako i. Pak jsou ty, které jsou nejméně významné z bitů I, převzaty z adresáře, který dává představu o indexu z adresáře. Použitím této hodnoty indexu přejděte do adresáře a vyhledejte adresu kbelíku pro hledání současných záznamů.
b. Vložení nového záznamu: Nejprve musíte postupovat přesně stejným postupem vyhledávání, který musí někde skončit někde v kbelíku. Vyhledejte místo v této vědro a vložte do něj záznamy. Pokud je vytvořený kbelík úplný a plný, pak se kbelík rozdělí a záznamy se znovu rozdělí.
Například poslední dva bity číslic 2 a 4 jsou 00. Takže jdou do kbelíku Bo a tak dále podle funkce modulu. Klíč 9 má adresu 10001, která musí být přítomna v prvním bloku, ale rozdělí se a přesune se do nového bloku B1, a to pokračuje, dokud nejsou všechny segmenty a klíče dynamicky hašovány. Hašovací funkce se používá způsobem, ve kterém se hashovací funkce používá k výběru sloupce a jeho hodnoty pro vygenerování adresy. Maximální doba hašovací funkce využívá primární klíč, který se zase používá ke generování adres datového bloku. Je to jednoduchá matematická funkce, kde primární klíč lze také považovat za adresu datového bloku, což znamená, že každý řádek se stejnou adresou jako primární klíč bude uložen v datovém bloku.
Doporučené články
Toto je průvodce Hashingem v DBMS. Zde diskutujeme úvod a různé typy hašování v DBMS, které zahrnuje statické hašování a dynamické hašování spolu s příklady. Další informace naleznete také v následujících článcích -
- Datové modely v DBMS
- Výhody DBMS
- Nástroj pro integraci dat
- Co je RDBMS?