

Rozdíl mezi R a R na druhou
V článku R vs R Squared je R programovací jazyk, který poskytuje médium pro statistické a grafické výpočty obrovského souboru dat. Tento programovací jazyk je open-source, který má softwarová zařízení, která jsou velmi užitečná v dnešních trendových technologiích, jako je věda o datech, strojové učení atd. Programovací jazyk R je jedním z účinných jazyků pro zobrazování grafů analýzy datových sad s mnoha nástroji a knihovnami. vestavěný. Tento jazyk je velmi jednoduchý na pochopení statistických technik, které mají být implementovány. Má také mnoho knihoven, které jsou zapsány v R a jsou uloženy v CRAN, ale pro velmi vysokou výpočetní úlohu se používají kódy C, C ++ a Fortan.
R na druhou (R2) je zpracován lineárními modely s využitím určitého vnímání nebo části variace proměnných odezvy. R hranatý je také jako programovací jazyk R pro statistická měření datových sad, které jsou nejlépe umístěny v regresní linii. R čtverec je také známý jako z hlediska koeficientu stanovení nebo koeficientu více stanovení pro více regresí.
Srovnání hlava-hlava mezi R a R na druhou (infografika)
Níže je osm nejlepších rozdílů mezi R a R na druhou:
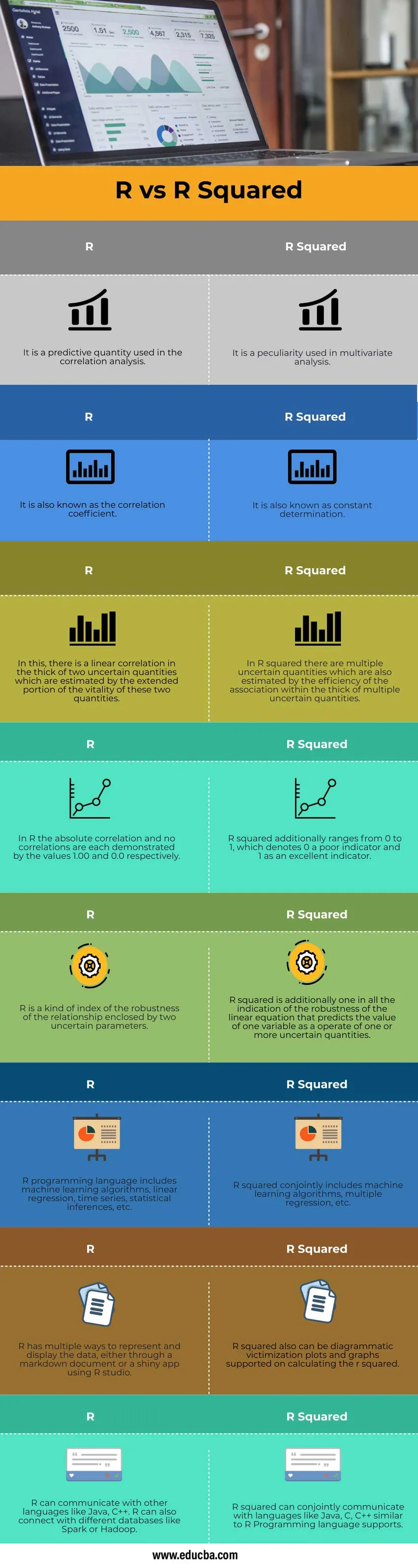
Klíčové rozdíly mezi R a R na druhou
Podívejme se na některé z hlavních klíčových rozdílů mezi R a R na druhou.
- Definice: R je programovací jazyk, který podporuje výpočet statistických datových sad a demonstraci těchto datových sad graficky pro snadnou analýzu daných dat. R squared také podporuje statistické datové sady pro vývoj lepší analýzy dat s tímto softwarem pro těžbu dat. R na druhou není nic dvojnásobného R, tj. Více R-násobků R na získání R na druhou. Jinými slovy, konstanta determinace je čtvercem konstantní korelace.
- Konstanty : R udává hodnotu, která je regresním výstupem v souhrnné tabulce a tato hodnota v R se nazývá koeficient korelace. Na druhou mocninu R udává hodnotu, která je vícenásobným regresním výstupem nazývaným koeficient determinace.
- Porozumění konceptu: Je snadné vysvětlit R čtverec s regresní koncepcí, ale je obtížné to udělat s R.
- Rozsah hodnot proměnných: V R se hodnoty dvou nejistých veličin pohybují v rozmezí od -1 do 1. V R na druhou se hodnoty dvou nejistých veličin pohybují v rozmezí 0 až 1, protože nikdy nemůže být záporné, protože jeho hodnota se dostane na druhou.
- Korelace mezi počtem proměnných: V R lze korelaci snadno zpracovat pro jednoduchou lineární regresi, protože zahrnuje pouze dvě nejisté proměnné, jedna je xa druhá je y. Na druhou mocninu R rozpracovává jednoduchou lineární regresi i vícenásobné regrese, přičemž R je obtížné vysvětlit vícenásobné regrese.
- Omezení : Na druhou mocninu R nelze určit, zda jsou odhady koeficientů a predikce zkreslené. Nemůže naznačit, zda regresní model poskytuje vhodné údaje pro dané údaje. Stejně jako v R, to podporuje obrovskou sadu dat, jako je řešení s velkými daty.
- Hodnoty R a R na druhou : V R na druhou koeficient stanovení ukazuje procentuální změnu v y, která je vysvětlena všemi proměnnými x dohromady. Takže se pohybuje od 0 do 1, kde 1 dává vynikající hodnotu a 0 chudým. V koeficientu korelace R je míra vztahu mezi dvěma proměnnými, které říkají pouze x a y, takže se pohybuje v rozmezí od -1 do 1, kde 1 označuje, že se dvě proměnné pohybují v souzvuku a -1 označuje, že dvě proměnné jsou v dokonalých protikladech.
Porovnávací tabulka R vs R
Pojďme diskutovat o nejlepším srovnání mezi R a R na druhou
Pro analýzu dat je k dispozici spousta nástrojů. Protože věda o údajích je jednou z vyvíjejících se technologií pro řízení a rozvoj podniků. Protože jsme schopni vidět i Python a SAS, jsou další nástroje pro aplikovanou matematiku, jako je statistická analýza dat, ale SAS není zdarma a Python postrádá komunikační možnosti, takže R je dobrý nástroj mezi implementací a analýzou dat.
| Sr.Ne | R | R na druhou |
| 1. | Je to prediktivní veličina použitá v korelační analýze. | Je to zvláštnost používaná v multivariační analýze. |
| 2. | Je také znám jako korelační koeficient. | To je také známé jako neustálé určování. |
| 3. | Přitom existuje lineární korelace v hustotě dvou nejistých veličin, které jsou odhadnuty rozšířenou částí vitality těchto dvou veličin. | Na druhou mocninu R existuje několik nejistých veličin, které se také odhadují na základě účinnosti asociace v hustotě velkého množství nejistých veličin. |
| 4. | V R je absolutní korelace a žádná korelace prokázána hodnotami 1, 00 a 0, 0. | R na druhou se navíc pohybuje v rozmezí od 0 do 1, což označuje 0 jako špatný indikátor a 1 jako vynikající indikátor. |
| 5. | R je druh indexu robustnosti vztahu uzavřeného dvěma nejistými parametry. | R mocnina je navíc jedna ze všech indikací robustnosti lineární rovnice, která předpovídá hodnotu jedné proměnné jako operaci jedné nebo více nejistých veličin. |
| 6. | Programovací jazyk R zahrnuje algoritmy strojového učení, lineární regresi, časové řady, statistické závěry atd. | R na druhou společně zahrnuje algoritmy strojového učení, vícenásobnou regresi atd. |
| 7. | R má několik způsobů, jak reprezentovat a zobrazovat data, a to buď prostřednictvím dokumentu ke stažení nebo lesklé aplikace pomocí aplikace R studio. | R čtverec také může být grafický graf viktimizace a grafy podporované pro výpočet r čtverce. |
| 8. | R umí komunikovat s jinými jazyky, jako je Java, C ++. R se také může spojit s různými databázemi jako Spark nebo Hadoop. | R na druhou může společně komunikovat s jazyky, jako je Java, C, C ++, podobně jako podpora jazyků R Programming. |
Závěr
Jak jsme viděli v tomto článku, R na druhou je čtverec R, tj. Čtverec korelace mezi dvěma nejistými veličinami (x a y). Nepřímo tedy uvádí, že R je koeficient korelace lineárního vztahu mezi pouze dvěma nejistými veličinami nebo proměnnými. Ale v případě R na druhou může měřit sílu vztahů mezi více proměnnými, což není možné v R. Takže můžeme dojít k závěru, že R na druhou je lepší než R, protože je násobkem R krát R. Proto,
R na druhou = 1 - (první součet chyb / druhý součet chyb)
Doporučené články
Toto byl průvodce R vs R na druhou. Zde také diskutujeme o klíčových rozdílech R vs R s infografiky a srovnávací tabulkou. Další informace naleznete také v následujících článcích -
- Jednoduchá lineární regrese
- Variace vs. standardní odchylka
- Korelační koeficient vzorce
- Regrese vs. ANOVA