
Definice průměrného algoritmu posunu
Algoritmus průměrného posunu spadá pod učení bez dozoru, které je kategorizováno jako algoritmus klastru. Ideologie algoritmu Mean Shift spočívá v tom, že iterativně přiřazuje datové body klastrům posunutím směrem k bodu, který má nejvyšší bod hustoty (režim). Logika průměrného posunu je založena na konceptu odhadu hustoty jádra označovaného jako KDE.
Clustering průměrného posunu algoritmu
Technika učení bez dozoru, kterou objevili Fukunaga a Hostetler k nalezení shluků:
- Mean Shift je také známý jako algoritmus pro vyhledávání režimů, který přiřazuje datové body klastrům způsobem posunutím datových bodů směrem k oblasti s vysokou hustotou. Nejvyšší hustota datových bodů se nazývá model v regionu. Algoritmus Mean Shift má aplikace široce používané v oblasti počítačového vidění a segmentace obrazu.
- KDE je metoda pro odhad distribuce datových bodů. Funguje tak, že do každého datového bodu umístíte jádro. Jádro v matematickém termínu je váhová funkce, která bude aplikovat váhy pro jednotlivé datové body. Přidání všech jednotlivých jader generuje pravděpodobnost.
Funkce jádra je vyžadována pro splnění následujících podmínek:
- Prvním požadavkem je zajistit, aby byl odhad hustoty jádra normalizován.
- Druhým požadavkem je, aby KDE byla dobře spojena se symetrií prostoru.
Dvě populární funkce jádra
Níže jsou použity dvě populární funkce jádra:
- Ploché jádro
- Gaussovo jádro
- Na základě použitého jádra se výsledná hustota liší. Pokud není uveden žádný parametr jádra, je ve výchozím nastavení vyvoláno Gaussovo jádro. KDE využívá konceptu funkce hustoty pravděpodobnosti, která pomáhá najít lokální maxima distribuce dat. Algoritmus pracuje tak, že se datové body vzájemně přitahují, což umožňuje datovým bodům směrem k oblasti s vysokou hustotou.
- Datové body, které se snaží konvergovat k lokálním maximům, budou ze stejné skupiny clusterů. Na rozdíl od shlukového algoritmu K-Means výstup algoritmu Mean Shift nezávisí na předpokladech na tvaru datového bodu a počtu shluků. Počet shluků bude určen algoritmem s ohledem na data.
- K provedení implementace algoritmu Mean Shift využíváme balíček python SKlearn.
Implementace algoritmu střední posunu
Níže je implementace algoritmu:
Příklad č. 1
Založeno na kurzu Sklearn pro algoritmus Clustering Clustering Algorithm. První úryvek implementuje algoritmus průměrného posunu, aby našel shluky dvojrozměrné sady dat. Balíčky používané k implementaci algoritmu střední směny.
Kód:
fromcluster importMeanShift, estimate_bandwidth
from sklearn.datasets.samples_generator import make_blobs as mb
importpyplot as plt
fromitertools import cycle as cy
Jednou z klíčových věcí je, že budeme používat knihovnu make_blobs společnosti sklearn pro generování datových bodů soustředěných na 3 místech. Aby bylo možné aplikovat algoritmus průměrného posunu na vygenerované body, musíme nastavit šířku pásma, která představuje interakci mezi délkou. Knihovna Sklearn's Library má vestavěné funkce pro odhadování šířky pásma.
Kód:
#Sample data points
cen = ((1, .75), (-.75, -1), (1, -1)) x_train, _ = mb(n_samples=10000, centers= cen, cluster_std=0.6)
# Bandwidth estimation using in-built function
est_bandwidth = estimate_bandwidth(x_train, quantile=.1,
n_samples=500)
mean_shift = MeanShift(bandwidth= est_bandwidth, bin_seeding=True)
fit(x_train)
ms_labels = mean_shift.labels_
c_centers = ms_labels.cluster_centers_
n_clusters_ = ms_labels.max()+1
# Plot result
figure(1)
clf()
colors = cy('bgrcmykbgrcmykbgrcmykbgrcmyk')
fori, each inzip(range(n_clusters_), colors):
my_members = labels == i
cluster_center = c_centers(k) plot(x_train(my_members, 0), x_train(my_members, 1), each + '.')
plot(cluster_center(0), cluster_center(1),
'o', markerfacecolor=each,
markeredgecolor='k', markersize=14)
title('Estimated cluster numbers: %d'% n_clusters_)
show()
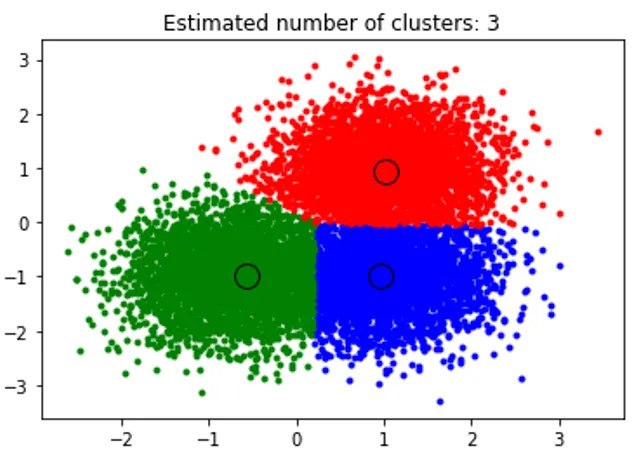
Výše uvedený fragment provádí shlukování a algoritmus nalezl shluky soustředěné na každé vytvořené blob. Vidíme, že z níže uvedeného obrázku vyneseného úryvkem ukazuje algoritmus průměrného posunu schopný identifikovat počet shluků potřebných v době běhu a zjistit příslušnou šířku pásma pro reprezentaci délky interakce.
Výstup:
Příklad č. 2
Na základě segmentace obrazu v počítačovém vidění. Druhý úryvek prozkoumá, jak algoritmus průměrného posunu použitý v programu Deep Learning provedl segmentaci barevného obrazu. K identifikaci prostorových shluků využíváme algoritmus střední posunu. Dřívější úryvek jsme použili datovou sadu 2-D, zatímco v tomto příkladu prozkoumáme prostor 3D. Pixel obrázku bude považován za datové body (r, g, b). Musíme převést obrázek do formátu pole tak, aby každý pixel představoval datový bod v obrázku, který jdeme do segmentu. Shlukování hodnot barev v prostoru vrací řadu shluků, kde pixely v klastru budou podobné prostoru RGB. Balíčky používané k implementaci algoritmu průměrného posunu:
Kód:
importnumpy as np
fromcluster importMeanShift, estimate_bandwidth
fromdatasets.samples_generator importmake_blobs
importpyplot as plt
fromitertools import cycle
fromPIL import Image
Pod úryvkem provedete segmentaci původního obrázku:
#Segmentation of Color Image
img = Image.open('Sample.jpg.webp')
img = np.array(img)
#Need to convert image into feature array based
flatten_img=np.reshape(img, (-1, 3))
#bandwidth estimation
est_bandwidth = estimate_bandwidth(flatten_img,
quantile=.2, n_samples=500)
mean_shift = MeanShift(est_bandwidth, bin_seeding=True)
fit(flatten_img)
labels= mean_shift.labels_
# Plot image vs segmented image
figure(2)
subplot(1, 1, 1)
imshow(img)
axis('off')
subplot(1, 1, 2)
imshow(np.reshape(labels, (854, 1224)))
axis('off')
Generovaný obraz uvádí, že tento přístup k identifikaci tvarů obrazů a určení prostorových shluků lze provést efektivně bez jakéhokoli zpracování obrazu.
Výstup:


Výhody a aplikace Průměrný algoritmus posunu
Níže jsou uvedeny výhody a použití průměrného algoritmu:
- Široce se používá k řešení počítačového vidění, kde se používá pro segmentaci obrazu.
- Seskupování datových bodů v reálném čase, aniž by se uvedl počet klastrů.
- Funguje dobře při segmentaci obrázků a sledování videa.
- Více robustní vůči odlehlým.
Pros o střední algoritmus posunu
Níže jsou uvedeny algoritmy průměrného posunu pro:
- Výstup algoritmu je nezávislý na inicializaci.
- Procedura je účinná, protože má pouze jeden parametr - šířku pásma.
- Žádné předpoklady o počtu datových klastrů a tvaru.
- Má lepší výkon než K-Means Clustering.
Nevýhody středního algoritmu posunu
Níže jsou uvedeny nevýhody algoritmu průměrného posunu:
- Drahé pro velké funkce.
- Ve srovnání s K-Means je shlukování velmi pomalé.
- Výstup algoritmu závisí na šířce pásma parametru.
- Výstup závisí na velikosti okna.
Závěr
Přestože se jedná o přímý přístup, který primárně používal k řešení problémů souvisejících s segmentací obrazu, shlukování. Je poměrně pomalejší než K-Means a je výpočetně nákladná.
Doporučené články
Toto je průvodce algoritmem střední posunu. Zde diskutujeme o problémech spojených se segmentací obrazu, shlukování, výhodami a dvěma funkcemi jádra. Další informace naleznete také v dalších souvisejících článcích.
- K- Znamená Clustering Algorithm
- KNN Algoritmus v R
- Co je to genetický algoritmus?
- Metody jádra
- Metody jádra ve strojovém učení
- Detail Vysvětlení algoritmu C ++