

Rozdíly mezi Sqoop a Flume
Sqoop je produkt ze softwaru Apache. Sqoop extrahuje užitečné informace z Hadoopu a poté přechází do externích datových úložišť. Pomocí Sqoop můžeme importovat data z RDBMS nebo mainframu do HDFS. Flume je také ze softwaru Apache. Shromažďuje a přesouvá generovaná rekurzivní data. Apache Flume není omezen pouze na agregaci dat protokolu, ale zdroje dat jsou přizpůsobitelné, a tak lze Flume použít k přepravě velkého množství dat. Nejlepší způsob sběru, agregace a přesunu velkého množství dat mezi distribuovaným systémem souborů Hadoop a RDBMS je pomocí nástrojů, jako je Sqoop nebo Flume.
Pojďme diskutovat o těchto dvou běžně používaných nástrojích pro výše uvedený účel.
Co je to Sqoop
Chcete-li použít Sqoop, musí uživatel určit nástroj, který chce uživatel použít, a argumenty, které daný nástroj ovládají. Data pak můžete také exportovat zpět do RDBMS pomocí Sqoop. Exportní funkce Sqoop se používá k extrahování užitečných informací z Hadoopu a jejich exportu do vnějších strukturovaných datových úložišť. Pracuje s různými databázemi jako Teradata, MySQL, Oracle, HSQLDB.
- Sqoop Architecture: -
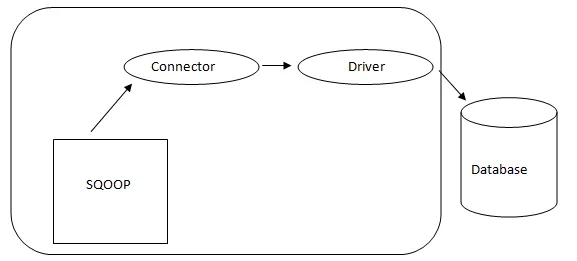
Architektura Sqoop
Konektor v Sqoop je plugin pro konkrétní zdroj databáze, takže je zásadní, že se jedná o součást založení Sqoop. Navzdory skutečnosti, že ovladače jsou součásti specifické pro databázi a distribuované různými dodavateli databází, je Sqoop sám dodáván s různými typy konektorů používaných pro převládající systém databázových a informačních skladů. Sqoop je tedy dodáván se směsicí různých konektorů mimo krabici. Sqoop poskytuje zásuvnou komponentu pro ideální síť a externí systém. Rozhraní Sqoop API poskytuje užitečnou strukturu pro sestavování nových konektorů, a proto lze do databáze Sqoop vložit libovolné databázové konektory, které umožní připojení různých datových systémů.
Co je to Flume
Apache Flume není omezen pouze na agregaci dat protokolu, ale zdroje dat jsou přizpůsobitelné, a proto Flume lze použít k přenosu velkého množství dat, včetně, ale neomezeno na e-mailové zprávy, data generovaná sociálními médii, data síťového provozu a téměř všechny možný zdroj dat.
Flume architecture: - Flume architecture je založena na mnoha základních koncepcích:
- Flume Event - je reprezentován jako jednotka toku dat, která má bajt užitečného zatížení a sadu řetězců s volitelnými záhlavími řetězců. Flume považuje událost za obecný blob bajtů.
- Flume Agent - Jedná se o proces JVM, který hostí komponenty, jako jsou kanály, umyvadlo a zdroje. Má potenciál přijímat, ukládat a předávat události z externího zdroje na další úroveň.
- Flume Flow - je okamžik, kdy je událost generována.
- Flume Client - odkazuje na rozhraní, kde klient pracuje v počátečním bodě události a doručuje jej agentovi Flume.
- Zdroj - Zdroj je zdroj, který spotřebovává události mající specifický formát a doručuje je prostřednictvím specifického mechanismu.
- Kanál - Jedná se o pasivní obchod, kde se konají události, dokud jej dřez neodstraní pro další transport.
- Sink - Odstraní událost z kanálu a umístí ji do externího úložiště, jako je HDFS. V současné době podporuje vytváření textových a sekvenčních souborů a podporuje kompresi v obou typech souborů.
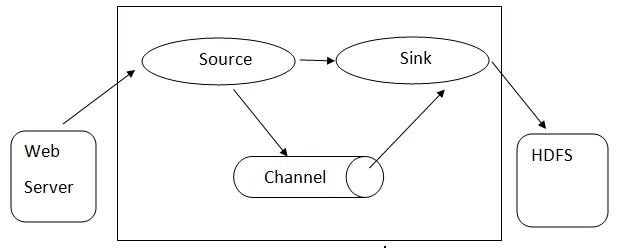
Architektura Flume
Srovnání hlava-hlava mezi Sqoop vs Flume (Infographics)
Níže je prvních 7 srovnání mezi Sqoop vs Flume

Klíčové rozdíly mezi Sqoop vs Flume
Nyní víme, že existuje mnoho rozdílů mezi Sqoop vs. Flume, zde jsou nejdůležitější rozdíly mezi nimi uvedené níže -
1. Sqoop je určen k výměně hromadných informací mezi Hadoopem a relační databází.
Zatímco Flume se používá ke sběru dat z různých zdrojů, které generují data týkající se konkrétního případu použití, a poté přenáší toto velké množství dat z distribuovaných zdrojů do jediného centralizovaného úložiště.
2. Sqoop také obsahuje sadu příkazů, které vám umožní prohlédnout si databázi, se kterou pracujete. Můžeme tedy považovat Sqoop za soubor souvisejících nástrojů.
Při shromažďování data Flume škáluje data vodorovně a lze použít více agentů Flume pro shromažďování data a jejich agregaci. Poté jsou datové protokoly přesunuty do centralizovaného datového úložiště, tj. Hadoop Distributed File System (HDFS).
3. Klíčovým faktorem pro používání služby Flume je to, že data musí být generována nepřetržitě a streamováním. Podobně je Sqoop nejvhodnější v situacích, kdy vaše data žijí v databázových systémech, jako jsou MySQL, Oracle, Teradata, PostgreSQL.
Sqoop vs Flume (srovnávací tabulka)
| Základ pro srovnání | SQOOP | FLUME |
|
Základní povaha | Sqoop dobře pracuje s jakýmkoli RDBMS, který má JDBC (Java Database Connectivity), jako je Oracle, MySQL, Teradata atd. | Flume funguje dobře pro zdroj datových proudů, který neustále generuje, jako jsou protokoly, JMS, adresář, zprávy o selhání atd. |
| Datový tok | Sqoop se používá speciálně pro paralelní přenos dat. Z tohoto důvodu může být výstup ve více souborech | Flume se používá pro sběr a agregaci dat kvůli své distribuované povaze. |
| Řízené události | Sqoop není poháněn událostmi. | Flume je zcela řízený událostmi. |
| Architektura | Sqoop sleduje architekturu založenou na konektorech, což znamená konektory, ví, jak se připojit k jinému zdroji dat. | Flume následuje architekturu založenou na agentech, kde kód v ní zapsaný je známý jako agent, který je zodpovědný za načítání dat. |
| Kde se používá | Používá se především pro rychlejší kopírování dat a poté je používá pro generování analytických výsledků. | Obecně se používá pro stahování dat, když společnosti chtějí analyzovat vzorce, kořenové příčiny nebo analýzu sentimentu pomocí protokolů a sociálních médií. |
| Výkon | Snižuje nadměrné zatížení úložiště a zpracování jejich přenosem do jiných systémů a má rychlý výkon. | Flume je odolný vůči chybám, robustní a má spolehlivý mechanismus spolehlivosti pro převzetí služeb při selhání a zotavení. |
| Historie vydání | První verze Apache Sqoop byla spuštěna v březnu 2012. Aktuální stabilní verze je 1.4.7 | První stabilní verze 1.2.0 Apache Flume byla spuštěna v červnu 2012. Aktuální stabilní verze je Apache Flume verze 1.8.0. |
Závěr - Sqoop vs Flume
Jak jste se dozvěděli výše, Sqoop a Flume, jsou primárně dva použité nástroje Data Ingestion použité ve světě velkých dat. Pokud potřebujete přijímat data textového protokolu do Hadoop / HDFS, pak je Flume tou správnou volbou. Pokud vaše data nebudou generována pravidelně, bude Flume stále fungovat, ale v této situaci to bude nadměrné. Podobně Sqoop není nejvhodnější pro zpracování dat řízených událostmi.
Doporučené články
Toto byl průvodce rozdíly mezi Sqoop vs. Flume, jejich význam, srovnání hlava-hlava, hlavní rozdíly, srovnávací tabulka a závěr. tento článek obsahuje všechny užitečné rozdíly mezi Sqoop a Flume. Další informace naleznete také v následujících článcích
- Hadoop vs Teradata - užitečné rozdíly, které byste se měli učit
- 5 nejdůležitějších rozdílů mezi Apache Kafka a Flume
- Big Data vs Apache Hadoop - Nejlepší 4 srovnání, které se musíte naučit
- 5 nejdůležitějších rozdílů mezi Apache Kafka a Flume
- Těžba důležitého textu vs zpracování přirozeného jazyka - 5 nejlepších srovnání