

Úvod do ANOVA v R
Následující článek ANOVA v R poskytuje přehled pro srovnání střední hodnoty různých skupin. Analýza odchylky (ANOVA) je velmi běžná technika používaná k porovnání střední hodnoty různých skupin. ANOVA model se používá pro testování hypotéz, kde se pro populaci generuje určitý předpoklad nebo parametr a statistická metoda se používá ke stanovení, zda je hypotéza pravdivá nebo nepravdivá.
Hypotéza je odvozena z předpokladu vyšetřovatele a dostupných informací o populaci. ANOVA se nazývá Analýza variací a používá se pro testování hypotéz, kde je třeba měřit prostředky proměnné ve více nezávislých skupinách.
Například v laboratoři, kde se bude studovat nebo vymýšlet nový lék na obezitu, vědci porovná výsledek experimentální a standardní léčby. Ve studii obezity lze získat cenné výsledky, když lze průměrnou míru obezity populace porovnat v různých věkových skupinách. V tomto případě bychom chtěli pozorovat průměrnou míru obezity u různých věkových skupin, jako je věk (5 až 18), (19, 35) a (36 až 50). Metoda ANOVA se používá, protože existují více než dvě skupiny, které jsou nezávislé. ANOVA metoda se používá k porovnání střední obezity nezávislých skupin. Používá se funkce aov () a Syntaxe je aov (vzorec, data = dataframe) V tomto článku se seznámíme s modelem ANOVA a dále diskutujeme o jednosměrném a obousměrném modelu ANOVA spolu s příklady.
Proč ANOVA?
- Tato technika se používá k zodpovězení hypotézy při analýze více skupin dat. Existuje několik statistických přístupů, avšak ANOVA v R se používá, když je třeba provést srovnání na více než dvou nezávislých skupinách, jako v našem předchozím příkladu tři různé věkové skupiny.
- Technika ANOVA měří průměr nezávislých skupin, aby vědcům poskytla výsledek hypotézy. Aby bylo možné získat přesné výsledky, je třeba vzít v úvahu průměrné hodnoty vzorku, velikost vzorku a standardní odchylku od každé jednotlivé skupiny.
- Je možné pozorovat průměr jednotlivě pro každou ze tří skupin pro srovnání. Tento přístup má však omezení a může se ukázat jako nesprávný, protože tato tři srovnání neberou v úvahu celková data, a mohou tedy vést k chybě typu 1. R nám poskytuje funkci provádět analýzu ANOVA a zkoumat variabilitu mezi nezávislými skupinami dat. Existuje pět fází provádění analýzy ANOVA. V první fázi jsou data uspořádána ve formátu CSV a sloupec je generován pro každou proměnnou. Jeden ze sloupců by byla závislá proměnná a zbývající jsou nezávislé proměnné. Ve druhé fázi jsou data načtena ve studiu R a příslušně pojmenována. Ve třetí fázi je datový soubor připojen k jednotlivým proměnným a čten z paměti. Nakonec je definována a analyzována ANOVA v R. V níže uvedených částech jsem uvedl několik příkladů případových studií, ve kterých by měly být použity techniky ANOVA.
- Na 12 polích bylo testováno šest insekticidů a vědci spočítali počet chyb, které v každém poli zůstaly. Nyní musí zemědělci vědět, zda insekticidy nějak ovlivňují, a pokud ano, který z nich nejlépe používají. Na tuto otázku odpovíte pomocí funkce aov () k provedení ANOVA.
- Padesát pacientů dostalo jednu z pěti léků na snížení hladiny cholesterolu (trt). Tři ze stavů léčby zahrnovaly stejné léčivo podávané jako 20 mg jednou denně (1krát) 10 mg dvakrát denně (2krát) 5 mg čtyřikrát denně (4krát). Zbývající dvě podmínky (drugD a drugE) představovaly konkurenční drogy. Která léčba lékem vyvolala největší snížení cholesterolu (odpověď)?
ANOVA Jednosměrná
- Jednosměrná metoda je jednou ze základních metod ANOVA, ve kterých se používá analýza rozptylu a porovnává se střední hodnota více skupin populace.
- Jednosměrná ANOVA dostala své jméno kvůli dostupnosti jednosměrných utajovaných dat. V jednosměrné ANOVA může být k dispozici jediná závislá proměnná a jedna nebo více nezávislých proměnných.
- Například provedeme techniku ANOVA na datovém souboru cholesterolu. Datový soubor se skládá ze dvou proměnných trt (což jsou úpravy na 5 různých úrovních) a proměnných odezvy. Nezávislá proměnná - skupiny léčby drogami, závislá proměnná - znamená 2 nebo více skupin ANOVA. Z těchto výsledků můžete potvrdit, že užívání 5 mg dávek 4krát denně bylo lepší než užívání 20 mg dávky jednou denně. Lék D má ve srovnání s tímto léčivem E lepší účinky
Léčivo D poskytuje lepší výsledky, pokud je užíváno v 20mg dávkách ve srovnání s lékem E
Používá datový soubor cholesterolu v balíčku multcompinstall.packages('multcomp')
library(multcomp)
str(cholesterol)
attach(cholesterol)
aov_model <- aov(response ~ trt)
Test ANOVA F pro léčbu (trt) je významný (p <0, 0001), což poskytuje důkaz, že těchto pět ošetření
# nejsou všechny stejně účinné.
shrnutí (aov_model)
detach (cholesterol)

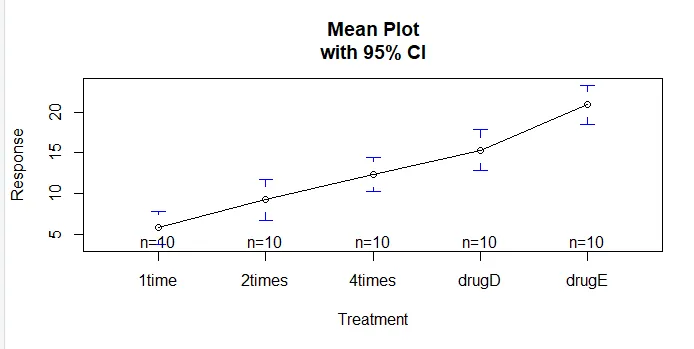
Funkce plotmeans () v balíčku gplots může být použita k vytvoření grafu skupinových prostředků a jejich intervalů spolehlivosti. To jasně ukazuje rozdíly v léčběinstall.packages('gplots')
library(gplots)
plotmeans(response ~ trt, xlab="Treatment", ylab="Response",
main="Mean Plot\nwith 95% CI")
Podívejme se na výstup z TukeyHSD () pro párové rozdíly mezi prostředky skupiny
TukeyHSD (aov_model)
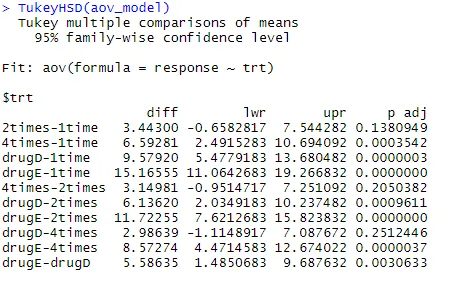
Průměrné snížení hladiny cholesterolu 1krát a 2krát se významně neliší (p = 0, 138), zatímco rozdíl mezi 1krát a 4krát je výrazně odlišný (p <0, 001).
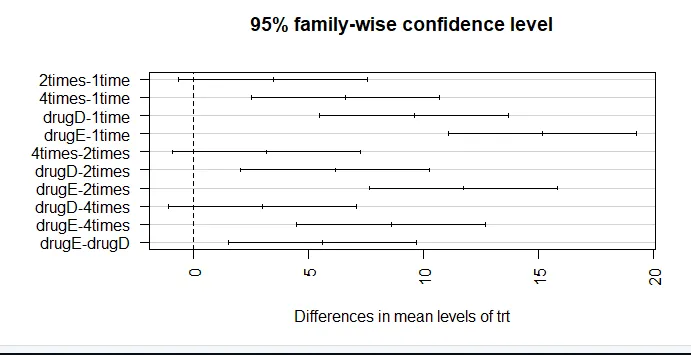
par (mar = c (5, 8, 4, 2)) # zvýšení grafu levého okraje (TukeyHSD (aov_model), las = 2)
Důvěra ve výsledky závisí na míře, v jaké vaše data splňují předpoklady, na nichž jsou založeny statistické testy. U jednosměrné ANOVA se předpokládá, že závislá proměnná je normálně distribuována a má v každé skupině stejnou varianci. Můžete použít QQ plot k posouzení knihovny předpokladů normality (auto).
QQ plot (lm (response ~ trt, data = cholesterol), simulovat = TRUE, main = ”QQ Plot”, label = FALSE)
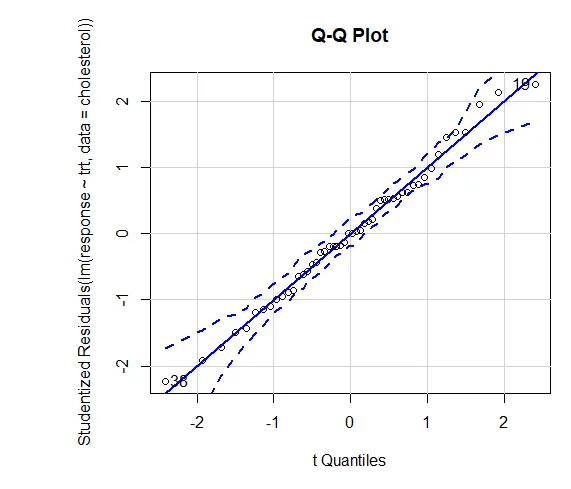
Tečkovaná čára = 95% spolehlivostní obálka, což naznačuje, že předpoklad normality byl splněn celkem dobře ANOVA předpokládá, že odchylky jsou stejné mezi skupinami nebo vzorky. K ověření tohoto předpokladu lze použít Bartlettův test
bartlett.test (odezva ~ trt, data = cholesterol). Bartlettův test ukazuje, že rozdíly v pěti skupinách se významně neliší (p = 0, 97).
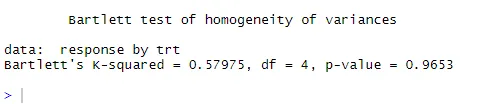
ANOVA je také citlivá na odlehlý test odlehlých hodnot pomocí funkce outlierTest () v balíčku do auta. Možná nebudete muset tento balíček spouštět, abyste aktualizovali knihovnu aut.update.packages(checkBuilt = TRUE)
install.packages("car", dependencies = TRUE)
library(car)
outlierTest(aov_model)
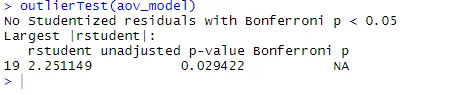
Z výstupu je vidět, že v údajích o cholesterolu nejsou žádné náznaky extrémních hodnot (NA nastane, když p> 1). Když vezmeme graf QQ, Bartlettův test a test outlier společně, zdá se, že data se docela dobře hodí k modelu ANOVA.
Obousměrná Anova
Další proměnná je přidána v testu obousměrné ANOVA. Pokud existují dvě nezávislé proměnné, budeme muset použít spíše dvoucestnou ANOVA než jednosměrnou ANOVA techniku, která byla použita v předchozím případě, kdy jsme měli jednu spojitou závislou proměnnou a více než jednu nezávislou proměnnou. K ověření obousměrné ANOVA je třeba splnit několik předpokladů.
- Dostupnost nezávislých pozorování
- Pozorování by měla být normálně distribuována
- Variace by měly být v pozorování stejné
- Odlehlé hodnoty by neměly být přítomny
- Nezávislé chyby
K ověření obousměrné ANOVA je do datové sady přidána další proměnná zvaná BP. Proměnná udává rychlost krevního tlaku u pacientů. Chtěli bychom ověřit, zda existuje statistický rozdíl mezi BP a dávkou podávanou pacientům.
df <- read.csv („file.csv“)
df
anova_two_way <- aov (odpověď ~ trt + BP, data = df)
shrnutí (anova_two_way)
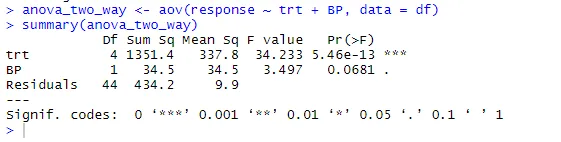
Z výstupu lze usoudit, že jak trt, tak BP se statisticky liší od 0. Proto lze hypotézu Null odmítnout.
Výhody ANOVA v R
ANOVA test určuje rozdíl mezi dvěma nebo více nezávislými skupinami. Tato technika je velmi užitečná pro analýzu více položek, která je nezbytná pro analýzu trhu. Pomocí testu ANOVA lze získat potřebný přehled z dat. Například během průzkumu produktů, kde se od uživatelů shromažďuje více informací, jako jsou nákupní seznamy, zákaznické lajky a nepáči. Test ANOVA nám pomáhá porovnávat skupiny populace. Skupinou může být buď Muž vs Žena, nebo různé věkové skupiny. Technika ANOVA pomáhá rozlišovat mezi průměrnými hodnotami různých skupin populace, které se skutečně liší.
Závěr - ANOVA v R
ANOVA je jednou z nejčastěji používaných metod pro testování hypotéz. V tomto článku jsme provedli test ANOVA na souboru údajů sestávajícího z padesáti pacientů, kteří dostávali léky snižující hladinu cholesterolu, a dále jsme viděli, jak lze provést obousměrnou ANOVA, když je k dispozici další nezávislá proměnná.
Doporučené články
Toto je průvodce ANOVA v R. Zde diskutujeme o jednosměrném a obousměrném modelu Anova spolu s příklady a výhodami ANOVA. Můžete si také prohlédnout naše další doporučené články -
- Regrese vs. ANOVA
- Co je to SPSS?
- Jak interpretovat výsledky pomocí testu ANOVA
- Funkce v R