
Rozdíl mezi úlem a HBase
Apache Hive a HBase jsou technologie velkých dat založené na Hadoopu. Oba používali k dotazování dat. Hive a HBase běží na Hadoopu a liší se ve své funkčnosti. Úl je dialekt založený na dialektech SQL, zatímco HBase podporuje pouze MapReduce. HBase ukládá data ve formě párů klíč / hodnota nebo sloupec rodiny, zatímco Hive data neukládá.
Rozdíly mezi hlavami mezi Hive vs HBase (Infographics)
Níže je uveden Top 8 Rozdíl mezi Úlem a HBase
Klíčové rozdíly mezi Hive vs HBase
- Hbase je kompatibilní s ACID, zatímco Hive není.
- Podregistr podporuje rozdělení a kritéria filtrování na základě formátu data, zatímco HBase podporuje automatické rozdělení.
- Úl nepodporuje aktualizační příkazy, zatímco HBase je podporuje.
- Hbase je rychlejší ve srovnání s Hive při načítání dat.
- Hive se používá ke zpracování strukturovaných dat, zatímco HBase, protože neobsahuje schémata, může zpracovávat jakýkoli typ dat.
- Hbase je ve srovnání s Úlem vysoce (horizontálně) škálovatelný.
- Úl analyzuje data na HDFS s podporou SQL Queries a poté je převede na mapu a sníží úlohy, zatímco v Hbase, protože se jedná o streamování v reálném čase, přímo provádí své operace v databázi rozdělením na tabulky a rodiny sloupců.
- když přicházíme k dotazování na datový úl, používá k vydání příkazů prostředí známé jako shell Hive, zatímco HBase, protože je to databáze, použijeme příkaz ke zpracování dat v HBase.
- Pro přechod do shellu úlu použijeme příkazový úl. Poté, co to dáte, bude to vypadat jako úl>. V HBase jednoduše dáme jako Use HBase.
Srovnávací tabulka Hive vs HBase
| Základ pro srovnání | Úl | Hbase |
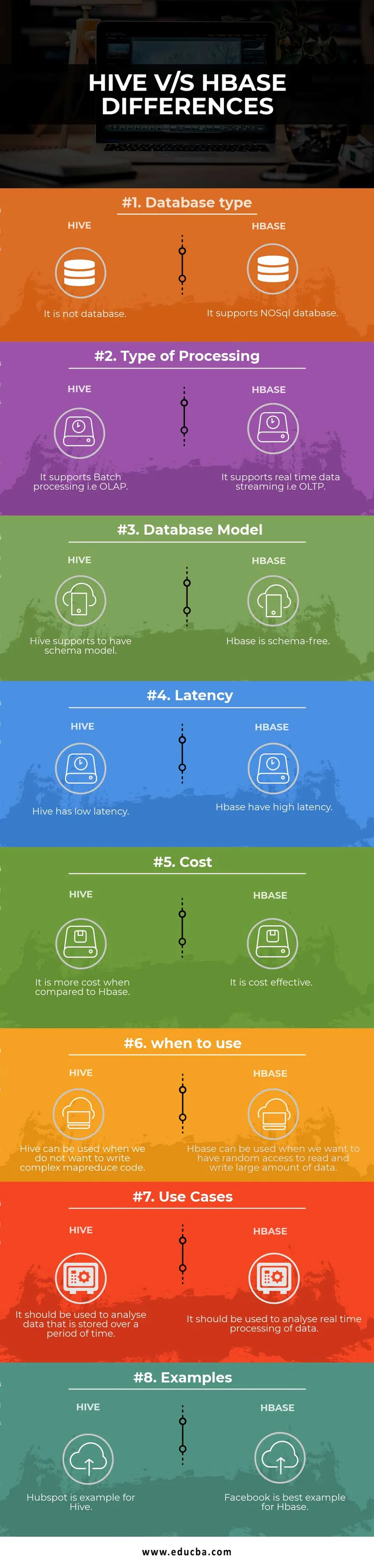
| Typ databáze | Není to databáze | Podporuje databázi NoSQL |
| Druh zpracování | Podporuje dávkové zpracování, tj. OLAP | Podporuje streamování dat v reálném čase, tj. OLTP |
| Databázový model | Podregistr podporuje model schématu | Hbase neobsahuje schémata |
| Latence | Úl má nízkou latenci | Hbase má vysokou latenci |
| Náklady | Ve srovnání s HBase je to nákladnější | Je to efektivní z hlediska nákladů |
| kdy použít | Úl lze použít, pokud nechceme psát složitý kód MapReduce | HBase lze použít, když chceme mít náhodný přístup ke čtení a zápisu velkého množství dat |
| Případy užití | Měl by být použit k analýze dat, která jsou uložena po určitou dobu | Měl by být použit k analýze zpracování dat v reálném čase. |
| Příklady | Hubspot je příkladem Úlu | Facebook je pro Hbase nejlepším příkladem |
Rozdíly v kódování mezi Hive vs HBase
Pojďme nyní diskutovat o základních rozdílech mezi Hive a HBase v kódování.
| Základ pro srovnání | Úl | Hbase |
| Vytvoření databáze | VYTVOŘIT DATABÁZE (POKUD NEEXISTUJE) JMÉNO DATABÁZE; | Protože Hbase je databáze, nemusíme vytvářet konkrétní databázi |
| Přetažení databáze | DROP DATABASE (POKUD existuje) DATABASE-NAME (RESTRICT OR CASCADE); | NA |
| Vytvoření tabulky | VYTVOŘENÍ (DOČASNÉ NEBO VNĚJŠÍ) TABULKA (POKUD NENÍ EXISTUJÍ) TABULKA JMÉNO ((název sloupce-název_dokumentu (sloupec s komentářem-komentář), ….))) (tabulka s tabulkou komentářů) (formát řádků ROW FORMAT) (uložen jako formát souboru) | VYTVOŘIT '', '' |
| Chcete-li změnit tabulku | ALTER TABLE name RENAME TO new-name
ALTER TABLE name DROP (COLUMN) název sloupce ALTER TABLE name ADD COLUMNS (col-spec (, col-spec ..)) ALTER TABLE name ZMĚNA column-name new-name new-type ALTER TABLE name VÝMĚNA STĹPŮ (col-spec (, col-spec ..)) | ALTER 'TABLE-NAME', NAME => 'COLUMN-NAME', VERSIONS => |
| Zakázání tabulky | NA | deaktivovat 'TABLE-NAME' -> pro deaktivaci zadaného názvu tabulky
disable_all 'r *' -> pro deaktivaci všech tabulek, které odpovídají regulárnímu výrazu |
| Povolení tabulky | NA | povolit 'TABLE-NAME' |
| Vypuštění tabulky | DROP TABLE IF EXISTS table-name | Pokud chceme zrušit tabulku, musíme ji nejprve vypnout
zakázat 'jméno-tabulky' drop 'table-name' Podobně můžeme použít disable_all a drop_all k odstranění tabulek, které odpovídají zadanému regulárnímu výrazu. |
| Seznam databází | ukázat databáze; | NA |
| Seznam tabulek v databázi | ukázat tabulky; | seznam |
| Popsat schéma tabulky | popsat název tabulky; | popiš 'název tabulky' |
Integrace Hive vs HBase
- Nainstalujte a nakonfigurujte Úl.
- Nainstalujte a nakonfigurujte HBase.
- Pro integraci Hive a HBase používáme SKLADOVACÍ MANIPULÁTORY v Úlu.
- Obslužné programy pro ukládání dat jsou kombinací SERDE, InputFormat a OutputFormat, které přijímají jakoukoli externí entitu jako tabulku v Úlu.
- Tato funkce tedy pomáhá uživateli vydávat dotazy SQL, ať už se jedná o tabulku v Hadoopu nebo v databázi založené na NOSQL, jako je HBase, MongoDB, Cassandra, Amazon DynamoDB.
- Nyní se podíváme na jeden příklad propojení Hive s HBase pomocí HiveStorageHandler:
- Nejprve musíme vytvořit tabulku Hbase pomocí příkazu.
vytvořit 'Student', 'personalinfo', 'dept info'
-> Personalinfo a dept info vytvoří dvě různé rodiny sloupců v Studentské tabulce.
- Potřebujeme vložit některá data do studentské tabulky. Například, jak je uvedeno níže.
dát 'student', 'sid01 ′, ' personalinfo: name ', ' Ram '
vložte 'student', 'sid01 ′, ' personalinfo: mailid ', ' '
vložte 'student', 'sid01 ′, ' deptinfo: deptname ', ' Java '
dát 'Student', 'sid01', 'deptinfo: joinyear', '1994'
-> Podobně můžeme vytvořit data pro sid02, sid03…
- Nyní musíme vytvořit tabulku Hive směřující na tabulku HBase.
- Pro každý sloupec v Hbase vytvoříme jednu konkrétní tabulku pro tento sloupec v Úlu. V tomto případě vytvoříme 2 tabulky v Úlu
create external table student_hbase(sid String, name String, mailid String)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler with serdeproperties("hbase.columns.mapping"=":key, personalinfo:name, personalinfo:mailid")
tblproperties("hbase.table.name"="student");
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
-> Podobně musíme v úlu vytvořit tabulku podrobností o podrobnostech.
- Nyní můžeme napsat dotaz SQL do podregistru, jak je uvedeno níže.
select * from student_hbase;
Tímto způsobem můžeme integrovat Hive s HBase.
Závěr - Úl vs HBase
Jak již bylo řečeno, oba jsou různé technologie, které poskytují různé funkce, kde Hive pracuje s použitím jazyka SQL, a lze jej také nazvat, protože HQL a HBase používají páry klíč-hodnota k analýze dat. Hive a HBase fungují lépe, pokud jsou kombinovány, protože Hive mají nízkou latenci a mohou zpracovat obrovské množství dat, ale nemohou udržovat aktuální data a HBase nepodporuje analýzu dat, ale podporuje aktualizace na úrovni řádků ve velkém množství dat.
Doporučený článek
Toto byl průvodce Hive vs. HBase, jejich význam, srovnání hlava-hlava, hlavní rozdíly, srovnávací tabulka a závěr. Další informace naleznete také v následujících článcích -
- Apache Pig vs Apache Hive - Top 12 užitečných rozdílů
- Zjistěte 7 nejlepších rozdílů mezi Hadoopem a HBase
- Top 12 Porovnání Apache Hive vs Apache HBase (Infographics)
- Hadoop vs Hive - Zjistěte nejlepší rozdíly