

Úvod do Python Pandas DataFrame
Více rozšíření pro knihovnu Python Pandas lze najít online. Jedním takovým je Panel (pan) Data (das). Toto slovo * Panel * jemně naznačuje dvourozměrnou datovou strukturu přítomnou v této knihovně, což značně posiluje její uživatele. Tato struktura se nazývá DataFrame.
Je to v podstatě matice řádků a sloupců, která obsahuje celý váš soubor dat, s velmi propracovanými možnostmi indexování. DataFrame (DF), lze si představit obrazově velmi podobně jako excel list. Ale díky čemuž je výkonný, je snadné provádět analytické a transformační operace na datech uložených v DataFrame.
Co přesně je Python Pandas DataFrame?
Na stránku Pydata lze odkazovat jako na něco oficiálního.
Pokud je správně pochopeno, zmiňuje DataFrame jako sloupcovou strukturu, schopnou uložit jakýkoli pythonový objekt (včetně samotného DataFrame) jako jednu hodnotu buňky. (Buňka je indexována pomocí jedinečné kombinace řádků a sloupců)
DataFrames se skládá ze tří základních komponent: dat, řádků a sloupců.
- Data: Jedná se o skutečné objekty / entity uložené v buňce v DataFrame a hodnoty představované těmito entitami. Objekt má jakýkoli platný pythonový datový typ, ať už zabudovaný nebo definovaný uživatelem.
- Řádky: Odkazy používané k identifikaci (nebo indexování) určité sady pozorování z úplných dat uložených v DataFrame se nazývají Řádky. Abychom to vyjasnili, představuje použité indexy a ne pouze údaje v konkrétním pozorování.
- Sloupce: Odkazy používané k identifikaci (nebo indexování) nastavených atributů pro všechna pozorování v DataFrame. Stejně jako v případě řádků se tyto údaje týkají indexu sloupců (nebo záhlaví sloupců) namísto pouze dat ve sloupci.
Takže bez dalšího povyku, vyzkoušejte některé způsoby, jak vytvořit tyto úžasně silné struktury.
Kroky k vytvoření datových rámců Python Pandas
Python Pandas DataFrame lze vytvořit pomocí následující implementace kódu,
1. Import pand
Chcete-li vytvořit DataFrames, je třeba importovat knihovnu pandas (zde žádné překvapení). My pohodlně importujeme alias pd do referenčních objektů pod modulem.
Kód:
import pandas as pd
2. Vytvoření prvního objektu DataFrame
Po importu knihovny jsou ve vašem pracovním prostoru k dispozici všechny metody, funkce a konstruktéři. Zkusme tedy vytvořit vanilkovou DataFrame.
Kód:
import pandas as pd
df = pd.DataFrame()
print(df)
Výstup:
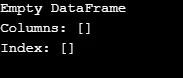
Jak je ukázáno na výstupu, konstruktor vrací prázdnou DataFrame.
Zaměřme se nyní na vytváření datových rámců z dat uložených v některých pravděpodobných reprezentacích.
- DataFrame from A Dictionary: Řekněme, že máme slovník ukládající seznam společností v softwarové doméně a počet let, v nichž byli aktivní.
Kód:
import pandas as pd
df = pd.DataFrame(
('Company':('Google', 'Amazon', 'Infosys', 'Directi'),
'Age':('21', '23', '38', '22') ))
print (df)
Podívejme se na reprezentaci vráceného objektu DataFrame jeho tiskem na konzoli.
Výstup:

Jak je vidět, každý klíč slovníku je v DataFrame považován za sloupec a indexy řádků jsou generovány automaticky počínaje 0. Docela snadné jo!
Řekněme, že jste mu chtěli dát vlastní index namísto 0, 1, … 4. Stačí předat požadovaný seznam jako parametr konstruktoru a pandy udělají potřebné.
Kód:
df = pd.DataFrame(
('Company':('Google', 'Amazon', 'Yahoo', 'Infosys', 'Directi'),
'Age':('21', '23', '24', '38', '22') ),
index=('Alpha', 'Beta', 'Gamma', 'Delta'))
print(df)
Výstup:
Věk společnosti
Alpha Google 21
Beta Amazon 23
Gamma Infosys 38
Delta Directi 22
Nyní můžete nastavit indexy řádků na libovolnou požadovanou hodnotu.
- DataFrame ze souboru CSV: Vytvořme soubor CSV obsahující stejná data jako v našem slovníku. Zavolejme soubor CompanyAge.csv
Google, 21
Amazon, 23
Infosys, 38
Directi, 22
Soubor lze načíst do dataframe (za předpokladu, že je přítomen v aktuálním pracovním adresáři) následujícím způsobem.
Kód:
csv_df = pd.read_csv(
'CompanyAge.csv', names=('Company', 'Age'), header=None)
print(csv_df)
Výstup:
Věk společnosti
0 Google 21
1 Amazon 23
2 Infosys 38
3 Directi 22
Nastavení názvů parametrů , obejití seznamu hodnot, přiřadí je jako záhlaví sloupců ve stejném pořadí, v jakém jsou v seznamu. Podobně lze indexy řádků nastavit předáním seznamu parametru indexu, jak je uvedeno v předchozí části. Záhlaví = Žádné označuje chybějící záhlaví sloupců v datovém souboru.
Nyní řekněme, že názvy sloupců byly součástí datového souboru. Poté nastavení header = False provede požadovanou úlohu.
3. CompanyAgeWithHeader.csv
Společnost, věk
Google, 21
Amazon, 23
Infosys, 38
Directi, 22
Kód se změní na
csv_df = pd.read_csv(
'CompanyAgeWithHeader.csv', header=False)
print(csv_df)
Výstup:
Věk společnosti
0 Google 21
1 Amazon 23
2 Infosys 38
3 Directi 22
- DataFrame ze souboru Excel: Data jsou často sdílena v excel souborech, protože zůstává nejoblíbenějším nástrojem, který běžní lidé používají pro sledování Adhoc. Naše diskuse by tedy neměla být ignorována.
Předpokládejme, že data, stejně jako v CompanyAgeWithHeader.csv, jsou nyní uložena v CompanyAgeWithHeader.xlsx, v listu s názvem Company Age. Stejný DataFrame jako výše bude vytvořen následujícím kódem.
Kód:
excel_df= pd.read_excel('CompanyAgeWithHeader.xlsx', sheet_name='CompanyAge')
print(excel_df)
Výstup:
Věk společnosti
0 Google 21
1 Amazon 23
2 Infosys 38
3 Directi 22
Jak vidíte, stejný DataFrame lze vytvořit předáním názvu souboru a názvu listu.
Další čtení a další kroky
Zobrazené metody představují velmi malou podmnožinu ve srovnání se všemi různými způsoby, jak lze vytvořit datové rámce. Byly vytvořeny s úmyslem začít jeden. Určitě byste měli prozkoumat uvedené odkazy a pokusit se prozkoumat jiné způsoby, včetně připojení k databázi a načíst data přímo do DataFrame.
Závěr
Ukázalo se, že Pandas DataFrame se mění ve hře Data Science a Data Analytics a je vhodný i pro krátkodobé krátkodobé projekty. Je dodáván s armádou nástrojů schopných krájení a nakrájení datových souborů s extrémně lehkou. Doufejme, že to bude sloužit jako odrazový můstek na vaší cestě vpřed.
Doporučené články
Toto je průvodce datovým rámcem Python-Pandas. Zde diskutujeme kroky k vytvoření datového rámce python-pandas spolu s jeho implementací kódu. Další informace naleznete také v následujících článcích -
- Top 15 funkcí Pythonu
- Různé typy Pythonových sad
- Top 4 typy proměnných v Pythonu
- Top 6 editorů Pythonu
- Pole ve struktuře dat