
Co je GLM v R?
Generalizované lineární modely jsou podmnožinou lineárních regresních modelů a účinně podporuje neobvyklé distribuce. K tomu je doporučeno použít funkci glm (). GLM funguje dobře s proměnnou, pokud rozptyl není konstantní a distribuován normálně. Linková funkce je definována pro transformaci proměnné odezvy tak, aby odpovídala příslušnému modelu. Model LM se provádí jak s rodinou, tak se vzorcem. Model GLM má tři klíčové komponenty nazývané náhodný (pravděpodobnost), systematický (lineární prediktor), komponenta odkazu (pro logitovou funkci). Výhodou použití glm je, že mají flexibilitu modelu, nepotřebují konstantní rozptyl a tento model vyhovuje odhadu maximální pravděpodobnosti a jeho poměrům. V tomto tématu se dozvíme o GLM v R.
Funkce GLM
Syntaxe: glm (vzorec, rodina, data, váhy, podmnožina, Start = null, model = TRUE, metoda = ””…)
Typy rodin (včetně typů modelů) zde zahrnují binomické, Poissonovo, Gaussovo, gama, kvazi. Každá distribuce provádí jiné použití a může být použita v klasifikaci a predikci. A když je model gaussovský, odpověď by měla být skutečným celým číslem.
A když je model binomický, odpověď by měla být třídami s binárními hodnotami.
A když je model Poisson, odpověď by měla být nezáporná s číselnou hodnotou.
A když je modelem gama, odpověď by měla být kladná numerická hodnota.
glm.fit () - Přizpůsobení modelu
Lrfit () - označuje logickou regresní kondici.
update () - pomáhá při aktualizaci modelu.
anova () - jeho volitelný test.
Jak vytvořit GLM v R?
Zde uvidíme, jak vytvořit snadno zobecněný lineární model s binárními daty pomocí funkce glm (). A pokračováním se sadou dat Stromy.
Příklady
// Import knihovnylibrary(dplyr)
glimpse(trees)

Pro zobrazení kategorických hodnot jsou přiřazeny faktory.
levels(factor(trees$Girth))
// Ověření spojitých proměnných
library(dplyr)
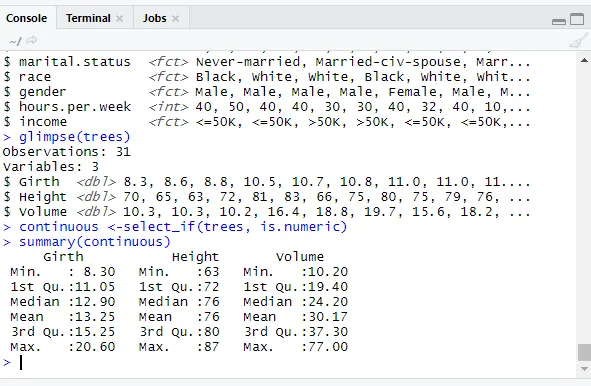
continuous <-select_if(trees, is.numeric)
summary(continuous)
// Zahrnutí datové sady stromů do vyhledávání R Pathattach (stromy)
x<-glm(Volume~Height+Girth)
x
Výstup:
| Volání: glm (vzorec = objem ~ výška + obvod)
Koeficienty: (Intercept) Výška obvodu -57, 9877 0, 3393 4, 7082 Stupně svobody: 30 Celkem (tj. Null); 28 Zbytkový Null Deviance: 8106 Zbytková odchylka: 421, 9 AIC: 176, 9 |
summary(x)
| Volání:
glm (vzorec = objem ~ výška + obvod) Zbytky deviance: Min 1Q Střední 3Q Max -6, 4065 -2, 6493 -0, 2876 2, 2003 8, 4847 Koeficienty: Odhad Std. Chyba t hodnota Pr (> | t |) (Intercept) -57, 9877 8, 6382 -6, 713 2, 75e-07 *** Výška 0, 3393 0, 1302 2, 607 0, 0145 * Obvod 4, 7082 0, 2664 17, 816 <2e-16 *** - Signif. kódy: 0 '***' 0, 001 '**' 0, 01 '*' 0, 05 '.' 0, 1 '' 1 (Parametr rozptylu pro gaussovskou rodinu je 15, 06862) Nulová odchylka: 8106, 08 při 30 stupních volnosti Zbytková odchylka: 421, 92 na 28 stupních volnosti AIC: 176, 91 Počet iterací pro hodnocení Fishera: 2 |
Výstup funkce souhrnu poskytuje volání, koeficienty a zbytky. Výše uvedená odpověď ukazuje, že jak výšková, tak obvodová součinnost nejsou významné, protože jejich pravděpodobnost je menší než 0, 5. A existují dvě varianty deviace nazvané nulová a reziduální. A konečně, hodnocení rybářů je algoritmus, který řeší problémy s maximální pravděpodobností. V případě binomie je odpovědí vektor nebo matice. cbind () se používá k vazbě vektorů sloupců v matici. A získat podrobné informace o souhrnu shody se používá.
Chcete-li jako Test kapoty, je spuštěn následující kód.
step(x, test="LRT")
Start: AIC=176.91
Volume ~ Height + Girth
Df Deviance AIC scaled dev. Pr(>Chi)
421.9 176.91
- Height 1 524.3 181.65 6.735 0.009455 **
- Girth 1 5204.9 252.80 77.889 < 2.2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Call: glm(formula = Volume ~ Height + Girth)
Coefficients:
(Intercept) Height Girth
-57.9877 0.3393 4.7082
Degrees of Freedom: 30 Total (ie Null); 28 Residual
Null Deviance: 8106
Residual Deviance: 421.9 AIC: 176.9
Model fit
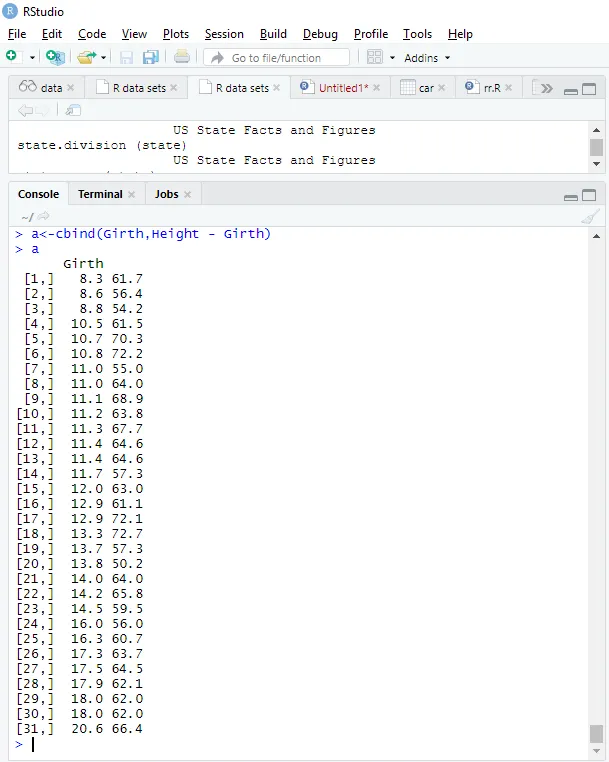
a<-cbind(Height, Girth - Height)
> a
shrnutí (stromy)
Girth Height Volume
Min. : 8.30 Min. :63 Min. :10.20
1st Qu.:11.05 1st Qu.:72 1st Qu.:19.40
Median :12.90 Median :76 Median :24.20
Mean :13.25 Mean :76 Mean :30.17
3rd Qu.:15.25 3rd Qu.:80 3rd Qu.:37.30
Max. :20.60 Max. :87 Max. :77.00
Chcete-li získat odpovídající standardní odchylku
apply(trees, sd)
Girth Height Volume
3.138139 6.371813 16.437846
predict <- predict(logit, data_test, type = 'response')
Dále se odkazujeme na proměnnou počet odpovědí na modelování dobré odpovědi. K výpočtu toho použijeme dataset USAccDeath.
Vstoupíme do konzoly R do následujících úryvků a uvidíme, jak se na nich provádí počítání roků a náměstí roku.
data("USAccDeaths")
force(USAccDeaths)
// Analyzovat rok 1973-1978.
disc <- data.frame(count=as.numeric(USAccDeaths), year=seq(0, (length(USAccDeaths)-1), 1)))
yearSqr=disc$year^2
a1 <- glm(count~year+yearSqr, family="poisson", data=disc)
summary(a1)
| Volání:
glm (formula = count ~ year + yearSqr, family = “poisson”, data = disc) Zbytky deviance: Min 1Q Střední 3Q Max -22, 4344 -6, 4401 -0, 0981 6, 0508 21, 4578 Koeficienty: Odhad Std. Chyba z hodnota Pr (> | z |) (Intercept) 9, 177e + 00 3, 557e-03 2582, 49 <2e-16 *** rok -7, 207e-03 2, 354e-04 -30, 62 <2e-16 *** yearSqr 8, 841e-05 3, 221e-06 27, 45 <2e-16 *** - Signif. kódy: 0 '***' 0, 001 '**' 0, 01 '*' 0, 05 '.' 0, 1 '' 1 (Disperzní parametr pro rodinu Poissonů je 1) Nulová odchylka: 7357, 4 při 71 stupních volnosti Zbytková odchylka: 6358, 0 při 69 stupních volnosti AIC: 7149, 8 Počet iterací pro hodnocení Fishera: 4 |
K ověření nejlepšího přizpůsobení modelu lze k nalezení použít následující příkaz
zbytky při zkoušce. Z níže uvedeného výsledku je hodnota 0.
1 - pchisq(deviance(a1), df.residual(a1))
Použití rodiny QuasiPoisson pro větší rozptyl v daných datech
a2 <- glm(count~year+yearSqr, family="quasipoisson", data=disc)
summary(a2)
| Volání:
glm (formula = count ~ year + yearSqr, family = “quasipoisson”, data = disk) Zbytky deviance: Min 1Q Střední 3Q Max -22, 4344 -6, 4401 -0, 0981 6, 0508 21, 4578 Koeficienty: Odhad Std. Chyba t hodnota Pr (> | t |) (Intercept) 9, 187e + 00 3, 417e-02 268, 822 <2e-16 *** rok -7, 207e-03 2, 261e-03 -3, 188 0, 00216 ** yearSqr 8, 841e-05 3, 095e-05 2, 857 0, 00565 ** - (Parametr disperze pro rodinu quasipoisson je 92.28857) Nulová odchylka: 7357, 4 při 71 stupních volnosti Zbytková odchylka: 6358, 0 při 69 stupních volnosti AIC: NA Počet iterací pro hodnocení Fishera: 4 |
Porovnání Poissonova s binomickou hodnotou AIC se výrazně liší. Mohou být analyzovány přesností a poměrem vzpomínek. Dalším krokem je ověření, že rozptyl reziduí je úměrný průměru. Pak můžeme vykreslit pomocí knihovny ROCR pro vylepšení modelu.
Závěr
Proto jsme se zaměřili na speciální model zvaný generalizovaný lineární model, který pomáhá při zaměření a odhadu parametrů modelu. Je to především potenciál proměnné nepřetržité reakce. A viděli jsme, jak glm zapadá do vestavěných balíčků R. Jsou to nejoblíbenější přístupy k měření počtu dat a robustní nástroj pro klasifikační techniky používané vědcem dat. Jazyk R samozřejmě pomáhá při provádění složitých matematických funkcí
Doporučené články
Toto je průvodce GLM v R. Zde diskutujeme funkce GLM a jak vytvořit GLM v R pomocí příkladů a výstupů datových sad stromů. Další informace naleznete také v následujícím článku -
- R Programovací jazyk
- Architektura velkých dat
- Logistická regrese v R
- Úlohy analýzy velkých dat
- Poissonova regrese v R | Provádění Poissonovy regrese