
Úvod do architektury úlu
Architektura úlu je postavena na vrcholu ekosystému Hadoop. Úl často komunikuje s Hadoopem. Apache Hive se vyrovnává jak s databázovým systémem SQL domény, tak s mapovou redukcí. Úlové aplikace lze psát v různých jazycích, jako je Java, python. Architektura podregistru ukazuje, jak psát jazyk podregistru Query a jak jsou interakce mezi programátorem prováděny pomocí rozhraní příkazového řádku. Jazyk dotazu podregistru provádí převádění všech úloh klastru Hadoop pomocí map-redukovat. Jak jsme všichni věděli, Hadoop zpracovává velká data v distribuovaném prostředí a tvoří open-source framework. Díky podregistru je flexibilní spravovat a provádět dotaz a je dobrým podporovatelem pro provádění funkcí, jako je zapouzdření, dotazy ad hoc. Tento článek poskytuje stručný úvod do architektury podregistru, který se nachází ve vrstvě Hadoop, a provádí shrnutí velkých dat.
Architektura úlu s jeho komponenty
Úl hraje hlavní roli v analýze dat a integraci business intelligence a podporuje formáty souborů jako textový soubor, rc soubor. Hive používá distribuovaný systém ke zpracování a provádění dotazů a úložiště se nakonec provádí na disku a nakonec se zpracovává pomocí rámce pro snižování map. Řeší problém optimalizace nalezený v rámci map-redukovat a podregistr provádí dávkové úlohy, které jsou jasně vysvětleny v pracovním postupu. Zde meta obchod ukládá informace o schématu. Rámec s názvem Apache Tez je navržen pro výkon dotazů v reálném čase.
Hlavní složky úlu jsou uvedeny níže:
- Úl klienty
- Úlové služby
- Úl úložiště (úložiště Meta)
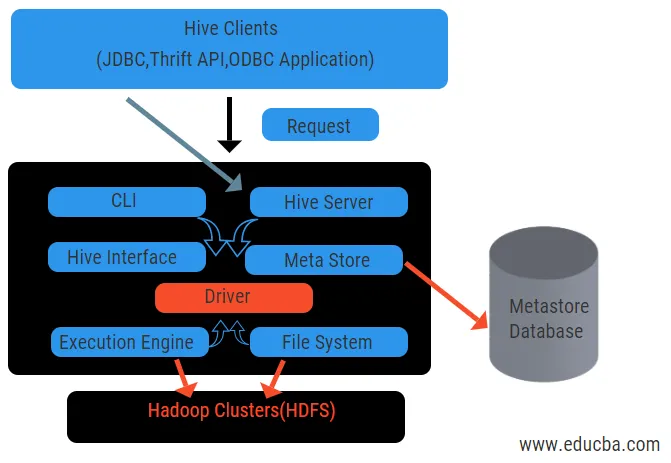
Výše uvedený diagram ukazuje architekturu Úlu a jeho prvků.
Klienti podregistru:
Zahrnují aplikaci Thrift pro provádění snadných příkazů podregistru, které jsou k dispozici pro python, ruby, C ++ a ovladače. Výhody těchto klientských aplikací pro provádění dotazů v podregistru. Úl má tři typy kategorizace klientů: thrift klienty, JDBC a ODBC klienti.
Úlové služby:
Zpracovat všechny dotazy úl má různé služby. Všechny funkce jsou snadno definovány uživatelem v úlu. Podívejme se stručně na všechny tyto služby:
- Rozhraní příkazového řádku (uživatelské rozhraní): Umožňuje interakci mezi uživatelem a podregistrem, výchozí shell. Poskytuje GUI pro provádění příkazového řádku úlu a vhled do úlu. K odesílání dotazů a interakcí s webovým prohlížečem můžeme také použít webové rozhraní (HWI).
- Ovladač úlu: Přijímá dotazy z různých zdrojů a klientů, jako je server Thrift, a ukládá a načítá ovladače ODBC a JDBC, které jsou automaticky připojeny k úlu. Tato komponenta provádí sémantickou analýzu zobrazení tabulek z metastoru, který analyzuje dotaz. Ovladač využívá pomoc kompilátoru a provádí funkce, jako je syntaktický analyzátor, plánovač, provádění úloh MapReduce a optimalizátor.
- Kompilátor: Analýza a sémantický proces dotazu provádí kompilátor. Převede dotaz na abstraktní strom syntaxe a znovu zpět do DAG pro kompatibilitu. Optimalizátor pak rozdělí dostupné úkoly. Úkolem vykonavatele je spouštět úkoly a sledovat rozvrh úkolů.
- Prováděcí modul : Všechny dotazy jsou zpracovávány prováděcím modulem. Plány fází DAG jsou prováděny motorem a pomáhají spravovat závislosti mezi dostupnými fázemi a provádět je na správné komponentě.
- Metastore: Funguje jako centrální úložiště pro ukládání všech strukturovaných informací metadat a je také důležitou součástí úlu, protože obsahuje informace, jako jsou tabulky a podrobnosti o rozdělení a ukládání souborů HDFS. Jinými slovy, řekneme, že metastore funguje jako jmenný prostor pro tabulky. Metastore je považován za samostatnou databázi, která je sdílena i jinými komponenty. Metastore má dva kusy nazvané service a backlog storage.
Datový model úlu je strukturován do oddílů, kbelíků, tabulek. To vše lze filtrovat, mít klíče pro rozdělení a vyhodnotit dotaz. Dotaz podregistru funguje na rámci Hadoop, nikoli na tradiční databázi. Server podregistru je rozhraní mezi dotazy vzdáleného klienta do podregistru. Spouštěcí modul je zcela zabudován do podregistru. Aplikaci úlů můžete najít ve strojovém učení, obchodní inteligenci v detekčním procesu.
Pracovní tok úlu:
Úl pracuje ve dvou typech režimů: interaktivní režim a neinteraktivní režim. Bývalý režim umožňuje všem příkazům podregistru přejít přímo do prostředí podregistru, zatímco pozdější typ spustí kód v konzolovém režimu. Data jsou rozdělena do oddílů, které se dále dělí na kbelíky. Realizační plány jsou založeny na agregaci a zkreslení dat. Další výhodou použití podregistru je to, že snadno zpracovává velké množství informací a má více uživatelských rozhraní.
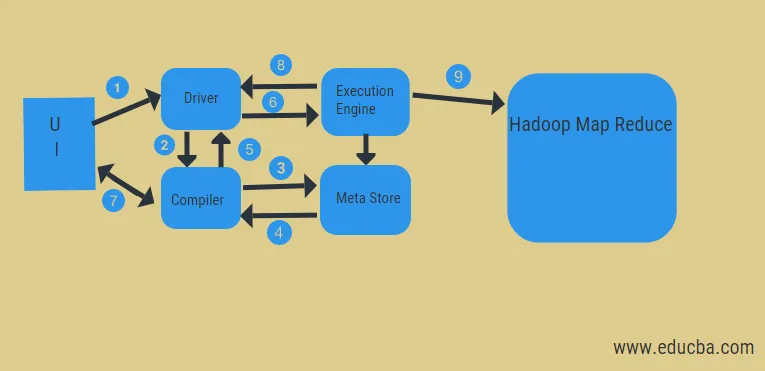
Z výše uvedeného schématu můžeme vidět útržek dat v úlu se systémem Hadoop.
Kroky zahrnují:
- spusťte dotaz z uživatelského rozhraní
- získat plán z DAG fází úkolů řidiče
- získat metadatový požadavek z meta obchodu
- poslat metadata z kompilátoru
- odeslání plánu zpět řidiči
- Proveďte plán v prováděcím motoru
- načítání výsledků pro příslušný uživatelský dotaz
- odesílání výsledků obousměrně
- zpracování prováděcího modulu v HDFS s výsledky mapování a načítání z datových uzlů vytvořených sledovačem úloh. funguje jako spojnice mezi Hive a Hadoop.
Úkolem spouštěcího stroje je komunikovat s uzly a získat informace uložené v tabulce. Pro přístup do tabulky se zde provádějí operace SQL, jako je vytvoření, přetažení nebo změna.
Závěr:
Prošli jsme architekturou úlu a jejich pracovním tokem, úl v podstatě provádí množství petabyte dat, a proto jde o balíček datového skladu na platformě Hadoop. Protože úl je dobrou volbou zacházení s velkým objemem dat, pomáhá při přípravě dat pomocí průvodce rozhraním SQL vyřešit problémy MapReduce. Úl Apache je nástroj ETL pro zpracování strukturovaných dat. Znalost fungování architektury úlu pomáhá podnikovým lidem pochopit princip fungování úlu a má dobrý začátek s programováním úlu.
Doporučené články:
Toto byl průvodce architekturou Úlu. Zde diskutujeme architekturu úlu, různé komponenty a pracovní postup úlu. můžete se také podívat na následující články a dozvědět se více -
- Hadoop architektura
- Použití Ruby
- Co je C ++
- Co je MySQL databáze
- Hive Order By