

Úvod do rozhodovacího stromu při těžbě dat
V dnešním světě „Velkých dat“ znamená pojem „dolování dat“, že musíme prozkoumat velké datové soubory a provést „dolování“ dat a přinést důležitou šťávu nebo podstatu toho, co data chtějí říci. Velmi podobná situace je situace v těžbě uhlí, kde jsou zapotřebí různé nástroje k těžbě uhlí zakopaného hluboko pod zemí. Z nástrojů v těžbě dat je „rozhodovací strom“ jedním z nich. Těžba dat je tedy sama o sobě obrovským polem, v němž v následujících několika odstavcích hlouběji ponoříme do „nástroje“ stromu rozhodování v dolování dat.
Algoritmus rozhodovacího stromu při dolování dat
Rozhodovací strom je supervizovaný přístup k učení, ve kterém trénujeme přítomná data s věděním, co vlastně cílová proměnná je. Jak název napovídá, tento algoritmus má stromovou strukturu. Podívejme se nejprve na teoretický aspekt Rozhodovacího stromu a poté se na něj díváme grafickým přístupem. V rozhodovacím stromu algoritmus rozdělí datový soubor do podskupin na základě nejdůležitějšího nebo významného atributu. Nejvýznamnější atribut je určen v kořenovém uzlu a to je místo, kde dochází k rozdělení celého souboru dat přítomného v kořenovém uzlu. Toto rozdělení je známé jako rozhodovací uzly. V případě, že již není možné další rozdělení, uzel se nazývá listový uzel.
Za účelem zastavení algoritmu k dosažení ohromující fáze se používá kritérium zastavení. Jedním z kritérií pro zastavení je minimální počet pozorování v uzlu, než dojde k rozdělení. Při použití stromu rozhodování při rozdělení datového souboru je třeba dávat pozor, aby mnoho uzlů mohlo mít jen hlučná data. Abychom zvládli problémy s odlehčenými nebo hlučnými daty, používáme techniky známé jako Prořezávání dat. Prořezávání dat není nic jiného než algoritmus pro klasifikaci dat z podmnožiny, která je pro učení z daného modelu obtížná.
Algoritmus rozhodovacího stromu byl vydán jako ID3 (Iterative Dichotomiser) strojním výzkumníkem J. Rossem Quinlanem. Později C4.5 byl propuštěn jako nástupce ID3. ID3 i C4.5 jsou chamtivý přístup. Nyní se podívejme na vývojový diagram algoritmu rozhodovacího stromu.
Abychom porozuměli pseudokódům, vezmeme datové body „n“, z nichž každý má atributy „k“. Níže je vývojový diagram proveden s ohledem na „informační zisk“ jako podmínku rozdělení.
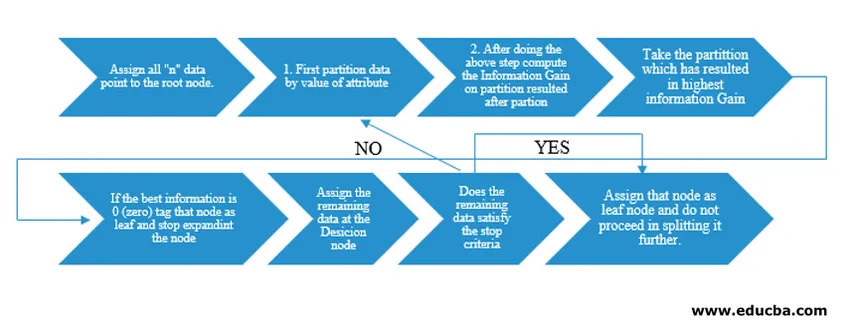
IG (on individual split) = Entropy before the split – Entropy after a split (On individual split)
Namísto informačního zisku (IG) můžeme jako kritérium rozdělení použít také index Gini. Pro pochopení rozdílu mezi těmito dvěma kritérii v laikovém pojetí můžeme uvažovat o tom, že tato informace získá jako rozdíl entropie před rozdělení a po rozdělení (rozdělení na základě všech dostupných funkcí).
Entropie je jako náhodnost a my bychom dosáhli bodu po rozdělení, abychom měli nejméně náhodný stav. Z tohoto důvodu musí být funkce Information Gain největší funkcí, kterou chceme rozdělit. Jinak, pokud se rozhodneme pro dělení na základě indexu Gini, najdeme index Gini pro různé atributy a pomocí stejného zjišťujeme vážený index Gini pro různé rozdělení a ten, který má vyšší index Gini, použije k rozdělení datové sady.
Důležité podmínky stromu rozhodování při těžbě dat
Níže uvádíme několik důležitých pojmů stromu rozhodování při těžbě dat:
- Kořenový uzel: Toto je první uzel, kde dochází k rozdělení.
- Uzel Leaf: Toto je uzel, po kterém už nedochází k větvení.
- Rozhodovací uzel: Uzel vytvořený po rozdělení dat z předchozího uzlu je známý jako rozhodovací uzel.
- Větev: Subsekce stromu obsahující informace o následcích rozdělení v rozhodovacím uzlu.
- Prořezávání: Když dojde k odebrání pod-uzlů rozhodovacího uzlu, který se stará o odlehlé nebo hlučné údaje, se nazývá prořezávání. To je také myšlenka být opakem rozdělení.
Aplikace rozhodovacího stromu při těžbě dat
Rozhodovací strom má vývojový diagram architektury zabudovanou do typu algoritmu. Během dělení má v podstatě vzor „If X, potom Y else Z“. Tento typ vzorce se používá k pochopení lidské intuice v programovém poli. Proto je možné toto rozsáhle použít při různých kategorizačních problémech.
- Tento algoritmus lze široce použít v oblasti, kde je objektivní funkce spojená s provedenou analýzou.
- Pokud je k dispozici řada způsobů jednání.
- Mimořádná analýza.
- Pochopení významné sady funkcí pro celý datový soubor a „důlních“ několika funkcí ze seznamu stovek funkcí ve velkých datech.
- Výběr nejlepšího letu pro cestu do cíle.
- Rozhodovací proces založený na různých okolnostech.
- Churnova analýza.
- Analýza sentimentu.
Výhody rozhodovacího stromu
Zde jsou některé výhody stromu rozhodnutí vysvětleného níže:
- Snadnost porozumění: Způsob, jakým je strom rozhodování zobrazen v jeho grafických formách, usnadňuje pochopení pro osobu s neanalytickým pozadím. Zejména pro lidi ve vedení, kteří se chtějí podívat na to, jaké funkce jsou důležité pouhým pohledem na strom rozhodování, mohou vycházet jejich hypotéza.
- Zkoumání dat: Jak již bylo řečeno, získání významných proměnných je základní funkčností rozhodovacího stromu a při jejich použití lze při zkoumání dat zjistit, která proměnná by vyžadovala zvláštní pozornost během fáze těžby a modelování dat.
- Ve fázi přípravy dat dochází k velmi malému lidskému zásahu a v důsledku doby, která je během dat potřebná, se čištění snižuje.
- Rozhodovací strom je schopen zpracovat kategorické i numerické proměnné a také řešit problémy klasifikace s více třídami.
- Jako součást předpokladu nemají rozhodovací stromy žádný předpoklad ze struktury prostorového rozložení a klasifikátoru.
Závěr
A konečně, na závěr Rozhodovací stromy přinášejí zcela jinou třídu nelinearity a řeší řešení problémů nelinearity. Tento algoritmus je nejlepší volbou k napodobení myšlení lidí na úrovni rozhodnutí a jeho zobrazení v matematicko-grafické podobě. Při určování výsledků z nových neviditelných dat používá přístup shora dolů a řídí se zásadou rozdělení a dobytí.
Doporučené články
Toto je průvodce rozhodovacím stromem při těžbě dat. Zde diskutujeme algoritmus, význam a aplikaci rozhodovacího stromu při získávání dat spolu s jeho výhodami. Další informace naleznete také v následujících článcích -
- Data Science Machine Learning
- Typy technik analýzy dat
- Rozhodovací strom v R
- Co je dolování dat?
- Průvodce různými metodikami analýzy dat