

Úvod do BFS algoritmu
Pro efektivní přístup k datům a jejich správu lze data ukládat a organizovat ve zvláštním formátu známém jako datová struktura. Existuje mnoho datových struktur, jako je zásobník, pole, propojený seznam, fronty, stromy a grafy atd. V lineárních datových strukturách, jako je zásobník, pole, propojený seznam a fronta, jsou data organizována v lineárním pořadí, zatímco v lineární datové struktury, jako jsou stromy a grafy, jsou data organizována hierarchicky nikoli v sekvenci. Graf je nelineární datová struktura, která má uzly a hrany. Uzly v grafu lze také označovat jako vrcholy, které jsou konečně v počtu a hrany jsou spojovacími čarami mezi libovolnými dvěma uzly.
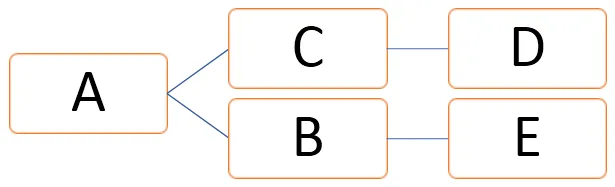
Ve výše uvedeném grafu lze vrcholy znázornit jako V = (A, B, C, D, E) a hrany lze definovat jako
E = (AB, AC, CD, BE)
Co je algoritmus BFS?
Obecně existují dva algoritmy, které se používají pro průchod grafu. Jsou to algoritmy BFS (Bththth First Search) a DFS (Depth First Search). Průchod grafu navštěvuje přesně jednou každý vrchol nebo uzel a hranu, v přesně definovaném pořadí. Je také velmi důležité sledovat vrcholy, které byly navštíveny, aby stejný vrchol nebyl překročen dvakrát. V algoritmu Breath First Search začíná procházení z vybraného uzlu nebo zdrojového uzlu a procházení pokračuje uzly přímo připojenými ke zdrojovému uzlu. Zjednodušeně řečeno, v algoritmu BFS bychom se měli nejprve vodorovně pohybovat a posouvat aktuální vrstvu, po které by se mělo provést přesunutí na další vrstvu.
Jak funguje algoritmus BFS?
Vezměme si příklad níže uvedeného grafu.
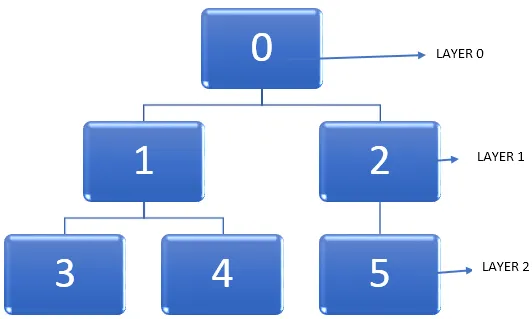
Důležitým úkolem je najít nejkratší cestu v grafu při procházení uzly. Když procházíme grafem, vrchol přechází z neobjeveného stavu do objeveného stavu a nakonec se zcela objeví. Je třeba poznamenat, že je možné uvíznout v určitém bodě, zatímco procházení grafem a uzlem lze navštívit dvakrát. Můžeme tedy použít metodu označení uzlů poté, co změní stav neobjevení na zcela objevený.
Na obrázku níže vidíme, že uzly lze v grafech označit, jakmile jsou zcela objeveny jejich označením černou barvou. Můžeme začít u zdrojového uzlu a jak postupuje skrz každý uzel, lze je označit jako identifikované.
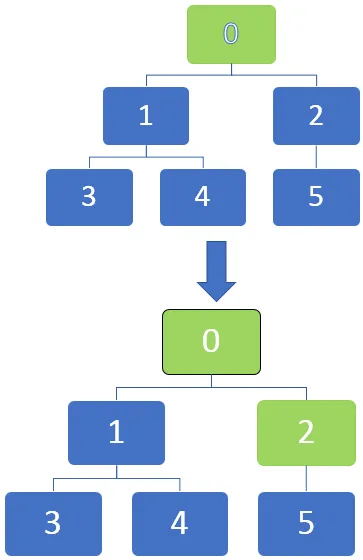
Traversal začíná od vrcholu a pak cestuje k odchozím okrajům. Když hrana přejde do neobjeveného vrcholu, je označena jako objevená. Když ale hrana přejde na zcela objevený nebo objevený vrchol, bude ignorován.
U směrovaného grafu je každá hrana navštívena jednou a pro neorientovaný graf je navštívena dvakrát, tj. Jednou při návštěvě každého uzlu. Algoritmus, který se má použít, se rozhodne na základě způsobu, jakým jsou zjištěné vrcholy uloženy. V algoritmu BFS se fronta používá tam, kde je nejdříve objeven nejstarší vrchol a poté se šíří skrze vrstvy z počátečního vrcholu.
Kroky se provádějí pro algoritmus BFS
Níže uvedené kroky se provádějí pro algoritmus BFS.
- V daném grafu začněme od vrcholu, tj. Ve výše uvedeném diagramu je uzel 0. Úroveň, ve které je tento vrchol přítomen, může být označena jako vrstva 0.
- Dalším krokem je nalezení všech ostatních vrcholů, které sousedí s počátečním vrcholem, tj. Uzlem 0, nebo z něj okamžitě přístupné. Potom můžeme označit tyto sousední vrcholy tak, aby byly přítomny ve vrstvě 1.
- Je možné dojít ke stejnému vrcholu díky smyčce v grafu. Měli bychom tedy cestovat pouze do těch vrcholů, které by měly být ve stejné vrstvě.
- Dále je označen nadřazený vrchol aktuálního vrcholu, ve kterém se nacházíme. Totéž je třeba provést pro všechny vrcholy ve vrstvě 1.
- Dalším krokem je nalezení všech těch vrcholů, které jsou jeden okraj od všech vrcholů, které jsou ve vrstvě 1. Tato nová sada vrcholů bude ve vrstvě 2.
- Výše uvedený proces se opakuje, dokud neproběhnou všechny uzly.
Příklad:
Vezměme si příklad níže uvedeného grafu a pochopíme, jak funguje algoritmus BFS. Obecně je v algoritmu BFS fronta používána pro frontu uzlů při procházení uzly.
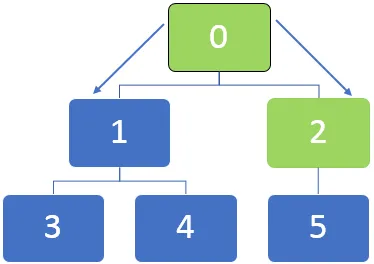
Ve výše uvedeném grafu musí být nejprve navštíven uzel 0 a tento uzel je zařazen do fronty níže:

Po návštěvě uzlu 0 jsou sousední uzly 0, 1 a 2 zařazeny do fronty. Frontu lze znázornit níže: 
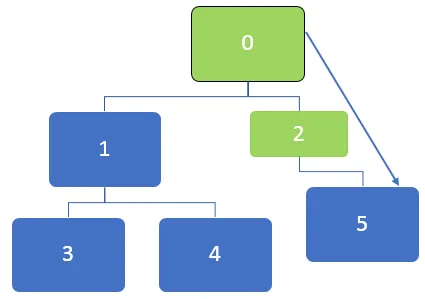
Poté bude navštíven první uzel ve frontě, který je 2. Po návštěvě uzlu 2 lze frontu reprezentovat níže:

Po návštěvě uzlu 2 bude 5 zařazeno do fronty a protože neexistují žádné nevítané sousední uzly pro uzel 5, přesto je 5 zařazeno do fronty, ale nebude dvakrát navštíveno.
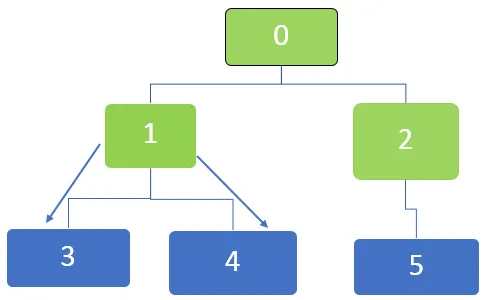
Dále je prvním uzlem ve frontě 1, který bude navštíven. Sousední uzly 3 a 4 jsou zařazeny do fronty. Fronta je znázorněna níže

Dále je první uzel ve frontě 5 a pro tento uzel již neexistují žádné další nenavštívené sousední uzly. Totéž platí pro uzly 3 a 4, pro které již neexistují žádné další nenavštívené sousední uzly.
Všechny uzly tedy procházejí a fronta se nakonec vyprázdní.

Závěr
Algoritmus vyhledávání podle šířky přichází s několika skvělými výhodami. Jednou z mnoha aplikací algoritmu BFS je výpočet nejkratší cesty. Používá se také v síti k vyhledání sousedních uzlů a lze ji najít na sociálních sítích, v síťovém vysílání a v garbage collection. Uživatelé musí pochopit požadavek a vzorec dat, aby ho mohli použít pro lepší výkon.
Doporučené články
Toto byl průvodce algoritmem BFS. Zde diskutujeme koncept, práci, kroky a příklad výkonu v algoritmu BFS. Další informace naleznete také v našich dalších doporučených článcích -
- Co je to chamtivý algoritmus?
- Algoritmus trasování paprsku
- Algoritmus digitálního podpisu
- Co je to Java Hibernate?
- Kryptografie digitálního podpisu
- BFS VS DFS | 6 hlavních rozdílů s infografiky