

Úvod do mapy Připojte se k Úlu
Map join je funkce používaná v dotazech Hive ke zvýšení její účinnosti z hlediska rychlosti. Připojit je podmínka použitá ke sloučení dat ze 2 tabulek. Když tedy provedeme normální připojení, úloha se odešle do úlohy Map-Reduce, která hlavní úkol rozdělí na 2 fáze - „Mapová fáze“ a „Redukující fáze“. Mapová fáze interpretuje vstupní data a vrací výstup do redukční fáze ve formě párů klíč-hodnota. Toto dále prochází fází míchání, kde jsou tříděny a kombinovány. Reduktor vezme tuto seřazenou hodnotu a dokončí úlohu spojení.
Tabulka může být načtena do paměti zcela v mapovači a bez použití procesu Map / Reducer. Čte data z menší tabulky a ukládá je do hashovací tabulky v paměti a poté je serializuje do hashového paměťového souboru, čímž se podstatně zkracuje čas. Je také známý jako Map Side Join in Hive. V zásadě jde o provedení spojení mezi dvěma tabulkami pomocí pouze fáze Map a přeskočení fáze Reduce. Pokud pravidelně používají spojení malých stolů, lze pozorovat časový pokles výpočtu vašich dotazů.
Syntaxe pro připojení mapy do podregistru
Pokud chceme provést dotaz na spojení pomocí map-join, musíme do příkazu zadat klíčové slovo „/ * + MAPJOIN (b) * /“:
>SELECT /*+ MAPJOIN(c) */ * FROM tablename1 t1 JOIN tablename2 t2 ON (t1.emp_id = t2.emp_id);
V tomto příkladu musíme vytvořit 2 tabulky s názvy tablename1 a tablename2, které mají 2 sloupce: emp_id a emp_name. Jeden by měl být větší soubor a jeden by měl být menší.
Před spuštěním dotazu musíme nastavit níže uvedenou vlastnost na true:
hive.auto.convert.join=true
Dotaz na spojení pro připojení mapy je zapsán výše a výsledkem je:
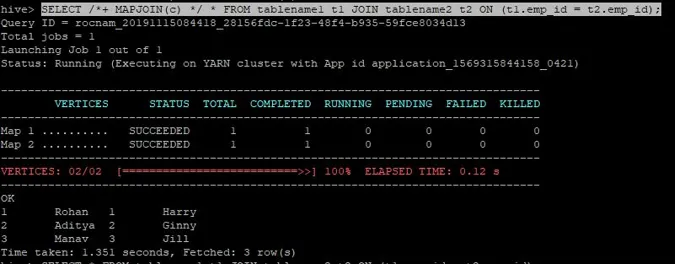
Dotaz byl dokončen za 1, 351 sekund.
Příklady spojení mapy do úlu
Níže uvádíme následující příklady
1. Příklad připojení mapy
V tomto příkladu vytvořme 2 tabulky s názvem table1 a table2 se 100 a 200 záznamy. Pro provedení stejného příkazu můžete použít níže uvedený příkaz a snímky obrazovky:
>CREATE TABLE IF NOT EXISTS table1 ( emp_id int, emp_name String, email_id String, gender String, ip_address String) row format delimited fields terminated BY ', ' tblproperties("skip.header.line.count"="1");
>CREATE TABLE IF NOT EXISTS table2 ( emp_id int, emp_name String) row format delimited fields terminated BY ', ' tblproperties("skip.header.line.count"="1");

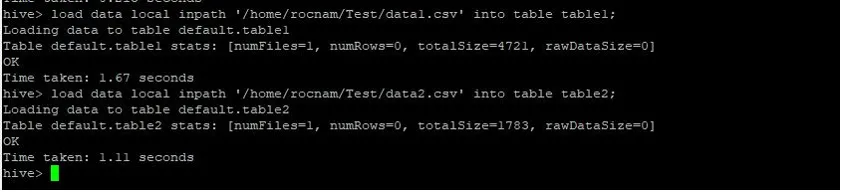
Nyní nahráváme záznamy do obou tabulek pomocí níže uvedených příkazů:
>load data local inpath '/relativePath/data1.csv' into table table1;
>load data local inpath '/relativePath/data2.csv' into table table2;
Udělejme běžný dotaz na spojení map na jejich ID, jak je znázorněno níže, a ověřte si čas potřebný k tomu:
>SELECT /*+ MAPJOIN(table2) */ table1.emp_name, table1.emp_id, table2.emp_id FROM table1 JOIN table2 ON table1.emp_name = table2.emp_name;
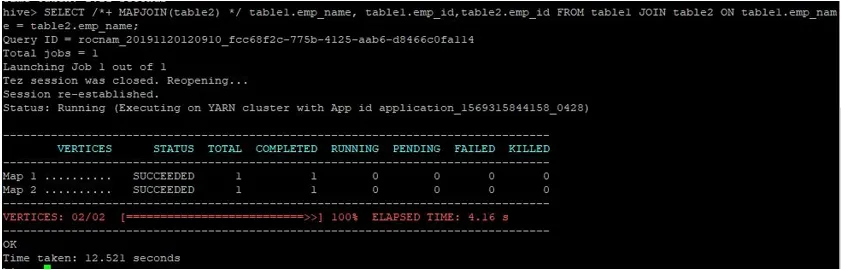
Jak vidíme, normální dotaz na spojení mapy trval 12 521 sekund.
2. Příklad připojení k lopatkové mapě
Pojďme nyní použít Bucket-map join ke spuštění stejného. Existuje několik omezení, která je třeba dodržovat při bucketingu:
- Kbelíky mohou být vzájemně spojeny pouze tehdy, je-li celkový počet kbelíků jedné tabulky násobkem počtu kbelíků v druhé tabulce.
- K provedení bucketingu musí mít tabulky s bucketed. Vytvořme tedy totéž.
Následující příkazy se používají k vytvoření tabulek bucketed table1 a table2:
>>CREATE TABLE IF NOT EXISTS table1_buk (emp_id int, emp_name String, email_id String, gender String, ip_address String) clustered by(emp_name) into 4 buckets row format delimited fields terminated BY ', ';
>CREATE TABLE IF NOT EXISTS table2_buk ( emp_id int, emp_name String) clustered by(emp_name) into 8 buckets row format delimited fields terminated BY ', ' ;

Stejné záznamy z tabulky1 vložíme také do těchto bucketed tabulek:
>insert into table1_buk select * from table1;
>insert into table2_buk select * from table2;
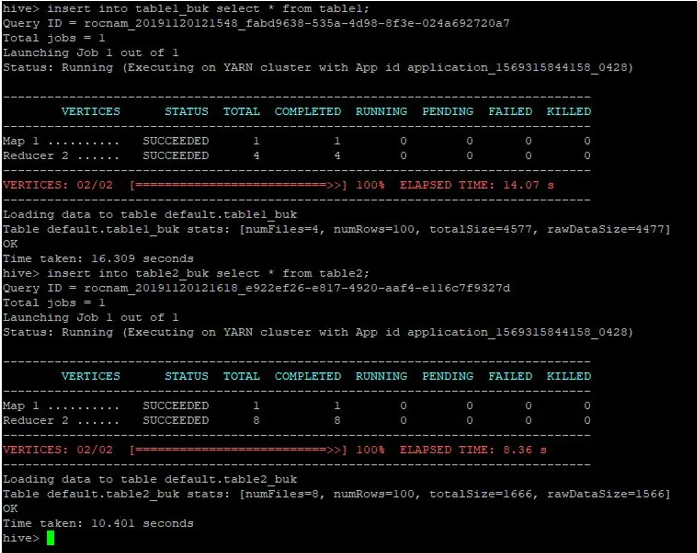
Nyní, když máme 2 tabulky s bucketami, připojme se k nim kbelíková mapa. První tabulka má 4 kbelíky, zatímco druhá tabulka má 8 kbelíků vytvořených ve stejném sloupci.
Aby dotaz na spojovací mapu fungoval, měli bychom v podregistru nastavit vlastnost true na true:
set hive.optimize.bucketmapjoin = true
>SELECT /*+ MAPJOIN(table2_buk) */ table1_buk.emp_name, table1_buk.emp_id, table2_buk.emp_id FROM table1_buk JOIN table2_buk ON table1_buk.emp_name = table2_buk.emp_name ;
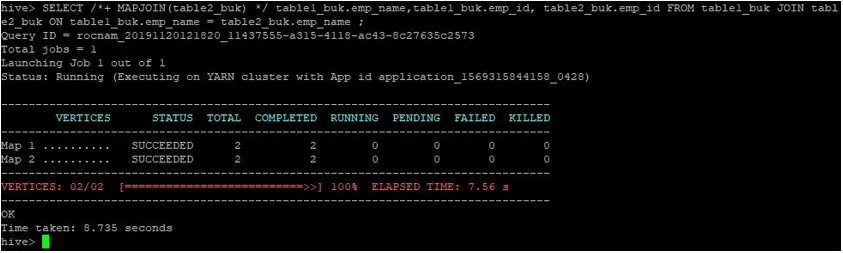
Jak vidíme, dotaz byl dokončen za 8, 735 sekund, což je rychlejší než normální spojení mapy.
3. Příklad sloučení sloučené mapy segmentů (SMB)
SMB lze provádět na tabulkách bucketed, které mají stejný počet kbelíků, a pokud je třeba tabulky třídit a bucketed ve sloupcích join. Úroveň Mapper se k těmto kbelíkům odpovídajícím způsobem připojí.
Stejně jako v Bucket-map join existují 4 kbelíky pro tabulku1 a 8 kbelíků pro tabulku2. V tomto příkladu vytvoříme další tabulku se 4 kbelíky.
Chcete-li spustit dotaz SMB, musíme nastavit následující vlastnosti podregistru, jak je uvedeno níže:
Hive.input.format = org.apache.hadoop.hive.ql.io.BucketizedHiveInputFormat;
hive.optimize.bucketmapjoin = true;
hive.optimize.bucketmapjoin.sortedmerge = true;
Pro provedení spojení SMB je třeba data seřadit podle sloupců spojení. Proto jsme přepsali data v tabulce1 bucketed, jak je uvedeno níže:
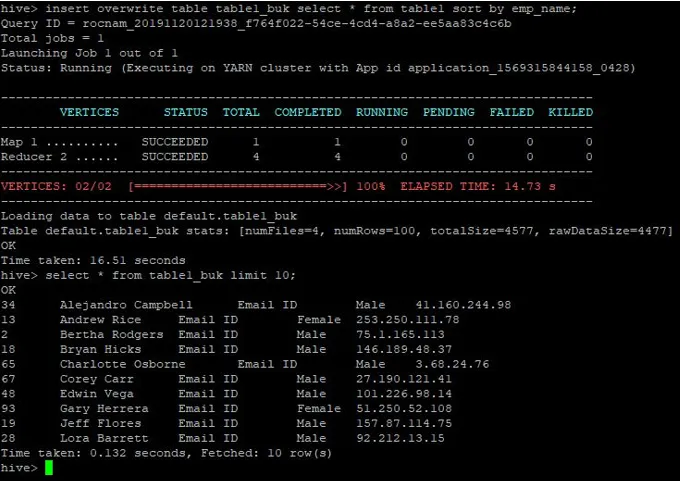
>insert overwrite table table1_buk select * from table1 sort by emp_name;
Data jsou nyní tříděna, což lze vidět na níže uvedeném snímku obrazovky:
Rovněž přepíšeme data v tabulce Bucketed2, jak je uvedeno níže:
>insert overwrite table table2_buk select * from table2 sort by emp_name;

Proveďte spojení pro výše uvedené 2 tabulky takto:
>SELECT /*+ MAPJOIN(table2_buk) */ table1_buk.emp_name, table1_buk.emp_id, table2_buk.emp_id FROM table1_buk JOIN table2_buk ON table1_buk.emp_name = table2_buk.emp_name ;
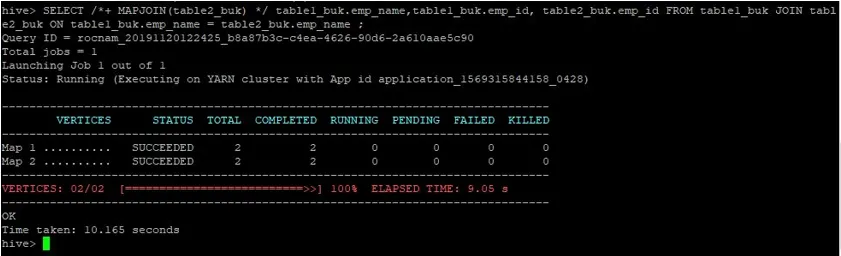
Vidíme, že dotaz trval 10, 165 sekund, což je opět lepší než normální spojení mapy.
Nyní vytvoříme další tabulku pro tabulku 2 se 4 vědry a stejná data seřazená podle emp_name.
>CREATE TABLE IF NOT EXISTS table2_buk1 (emp_id int, emp_name String) clustered by(emp_name) into 4 buckets row format delimited fields terminated BY ', ' ;
>insert overwrite table table2_buk1 select * from table2 sort by emp_name;
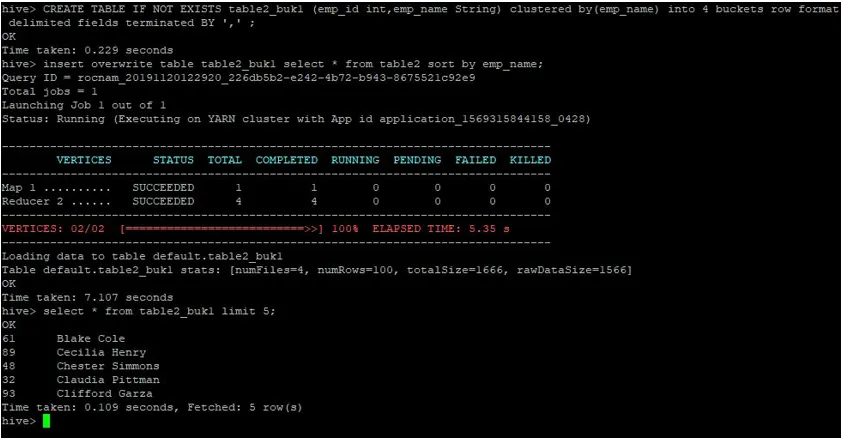
Vzhledem k tomu, že nyní máme obě tabulky se 4 kbelíky, proveďte znovu dotaz na spojení.
>SELECT /*+ MAPJOIN(table2_buk1) */table1_buk.emp_name, table1_buk.emp_id, table2_buk1.emp_id FROM table1_buk JOIN table2_buk1 ON table1_buk.emp_name = table2_buk1.emp_name ;
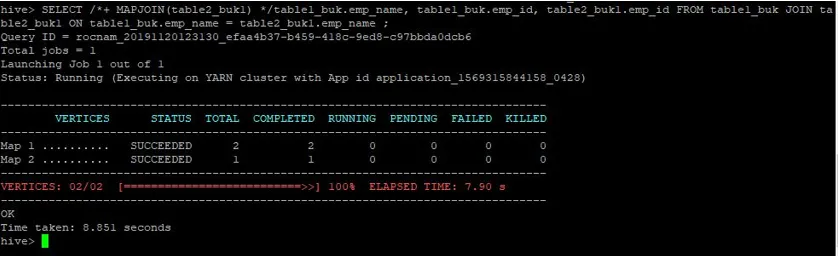
Dotaz trvalo 8, 81 sekund znovu rychleji než normální dotaz na připojení mapy.
Výhody
- Map join snižuje čas potřebný pro třídění a slučování procesů probíhajících v náhodném pořadí a snižuje fáze a tím minimalizuje také náklady.
- Zvyšuje účinnost výkonu úkolu.
Omezení
- Stejnou tabulku / alias nelze použít pro spojení různých sloupců ve stejném dotazu.
- Dotaz na spojení mapy nemůže převést úplné vnější spojení na spojení na straně mapy.
- Připojení mapy lze provést pouze v případě, že jedna z tabulek je dostatečně malá, aby se mohla přizpůsobit paměti. Nelze tedy provést tam, kde jsou data tabulky obrovská.
- Levé spojení je možné provést s mapovým spojením, pouze pokud je správná velikost tabulky malá.
- K spojení mapy je možné provést pravé spojení, pouze pokud je velikost levé tabulky malá.
Závěr
Pokusili jsme se zahrnout nejlepší možné body Map Join in Hive. Jak jsme viděli výše, spojení na straně Map funguje nejlépe, když jedna tabulka obsahuje méně dat, takže se úloha rychle dokončí. Čas potřebný pro dotazy, které jsou zde uvedeny, závisí na velikosti datové sady, takže zde zobrazený čas je pouze pro analýzu. Map join lze snadno implementovat v aplikacích v reálném čase, protože máme obrovská data, což pomáhá snížit síťový I / O provoz.
Doporučené články
Toto je průvodce mapou Připojit se do Úlu. Zde diskutujeme příklady Map Připojte se do Úlu spolu s výhodami a omezeními. Další informace naleznete také v následujícím článku -
- Připojí se v Úlu
- Vestavěné funkce Úlu
- Co je Úl?
- Příkazy úlu