
Přehled AWS RedShift
AWS poskytuje mnoho funkcí, které nám usnadňují práci. V tomto tématu se budeme učit o Co je AWS Redshift a některých technologiích AWS Redshift, které jsou uvedeny níže: -
- Amazon EC2
- Amazon RDS
- Amazon S3
- Amazon CloudFront
- Amazon Auto Scaling
- Amazon Lambda
- Amazon Redshift
Jednou z hlavních služeb poskytovaných AWS a budeme se zabývat, je Amazon RedShift. Co je tedy tento RedShift, k čemu se používá, to jsou základní otázky, které na nás přijdou, kdykoli si to přečteme. takže se podrobně podíváme, co je redshift a k čemu se používá. RedShift je podniková úroveň, petabyte měřítko a plně spravovaná služba skladování dat.
Co je tedy datový sklad? Odpověď na bydlení je sama o sobě, pokud víme, co je sklad všeobecný, obvykle skladiště je místo, kde mohou být suroviny nebo zpracované zboží skladovány před jejich distribucí k prodeji, to samé platí pro Data také datový sklad je místo pro sběr, ukládání a správu dat z různých zdrojů a poskytování relevantních a smysluplných obchodních poznatků. Amazon tedy poskytuje podnikový skladový nástroj, kde můžeme zpracovávat a spravovat data pomocí REDSHIFT. Rozsah těchto datových sad se liší od 100 s gigabajtů po petabajt.
Důvody pro použití AWS RedShift
Často se tedy setkáváme s obecnou otázkou, že před tímto nástrojem AWS, kde byl tento sklad, kde jsme dělali všechna tato zpracování, ukládání a výrobu dat. Takže dříve, když bylo načítání dat zcela normální, používali jsme fyzické servery, databáze, které byly použity pro sledování dat a jejich zpracování, ale protože došlo k exponenciálnímu nárůstu objemu dotazování a zpracování dat, stal se obtížným úkolem dotazy začaly trvat dlouho podle očekávání.
Zde jsme narazili na potřebu amazonského redshift, který byl mnohem rychlejší s velmi vysokým výkonem a škálovatelností pro ukládání a výrobu dat. Přicházel s obrovskou úložnou kapacitou a průhledným stanovováním cen a zabezpečen před různými porušeními dat. Díky podpoře rozhraní SQL a různých ovladačů ODBC / JDBC je poměrně snadné používat a dobře se sloučit s ostatními službami Amazonu.
Práce s AWS RedShift
Nyní se podívejme na schéma architektury Redshift a pokusíme se pochopit, jak RedShift ve skutečnosti funguje -
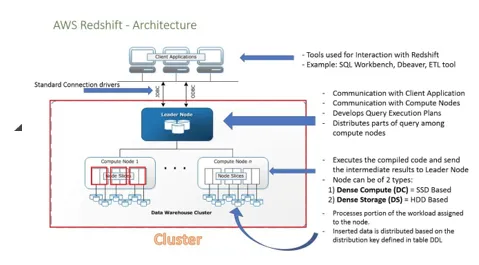
- Následující obrázek znázorňuje fungování Amazon RedShift. Podívejme se na to podrobně: -
- Pro připojení k klientské aplikaci máme několik ovladačů, které se připojují k Redshift.
- V rámci Redshift můžeme vytvořit více než jeden cluster a každý cluster může hostit více databází.
- Uzly jsou rozděleny do segmentů, z nichž každý má data.
- Z dostupných uzlů, pokud máme více než jeden uzel, je vybrán jako Leader, který bude hlavním zdrojem pro komunikaci klienta. Klientská aplikace bude mluvit pouze s vedoucím uzlem, vedoucí uzel je zodpovědný za přijímání dotazů a příkazů z klientského programu.
- Jakmile vedoucí uzel začne získávat dotazy prováděné klientem, začne analyzovat dotaz a sestavuje plán tak, aby byl spuštěn na jiných výpočetních uzlech. Jakmile je proces distribuován do příslušných uzlů, čeká na konečný výsledek z uzlů, než je vrátí klientovi.
- Můžeme přidat počet uzlů a také můžeme zvětšit paměť, jak se zvyšuje zatížení dat.
- Výpočtové uzly mají samostatnou síť, ke které klient nemá přístup, což ji také zajišťuje.
- Existují dva typy uzlů: Hustý úložný uzel a Hustý výpočetní uzly, kapacita úložiště se může pohybovat od 160 GB do 16 TB
Viděli jsme tedy základní architekturu toho, jak REDSHIFT funguje. Nyní přejdeme k tomu, jak použít pro Aws Redshift.
Používání AWS RedShift -
Pro práci s AWS Redshift musíme provést některé níže uvedené základní kroky: -
1) Přihlaste se do AWS a vytvořte si tam účet. (Pokud ne)
2) Přejděte na konzoli Amazon Redshift pomocí následujícího odkazu: -
https://console.aws.amazon.com/redshift/
3) Nyní musíme vytvořit roli I AM, kterou musíme přejít na níže uvedený odkaz: -
https://console.aws.amazon.com/iam/
- Přejít na role
- Zvolte vytvoření rolí.
- Ve službě AWS zvolte Redshift
- Vyberte možnost Redshift - Přizpůsobitelné a poté Další: Oprávnění v části vyberte případ použití.
- Nastavte hranici oprávnění
- Zadejte název své role
- Zkontrolujte a vytvořte roli.
4) Nyní musíme vytvořit klastr výběrem nabídky regionu v konzole.
- Vyberte oblast, kde je vytvořen klastr.
- Klikněte na Spustit.
- Musíme vyplnit několik podrobností, jako je název databáze, heslo a zkontrolovat tlačítko pokračovat
- Jakmile je cluster viditelný, zkontrolujte to v seznamu a zkontrolujte stavové informace.
- Jakmile s námi máme klastr, musíme dále nastavit skupinu zabezpečení, zde musíme nastavit zdroj a rozsah protokolu příchozích pravidel.
- Zkontrolujte požadovanou konfiguraci a připojte se k clusteru Redshift.
5) Jakmile skončíme se všemi konfiguracemi souvisejícími s klastry, musíme se nyní připojit k našemu Redshift. K tomuto Redshiftu se můžeme připojit přímo nebo přes SSL. Pro přímé připojení potřebujeme ovladače JDBC / ODBC, které musíme nastavit přes konfigurační stránku klastru.
Po dokončení těchto několika konfigurací jsme připraveni použít Redshift.
Výhody AWS RedShift -
Proč tedy někdo bude používat AWS Redshift, musí existovat určitá výhoda oproti jiným službám, které to činí zvláštním. Nyní tedy zkontrolujeme některé z výhod používání Redshift.
- Vysoká rychlost : - Doba zpracování dotazu je poměrně rychlejší než ostatní nástroje pro zpracování dat a vizualizace dat má mnohem jasnější obrázek.
- Hromadné zpracování dat : - Být větší velikost dat redshift má schopnost zpracování obrovského množství dat v dostatečném čase.
- Minimální ztráta dat : - Protože jsou data distribuována v klastru a zpracovávána paralelně v síti, existuje minimální pravděpodobnost ztráty dat a dobře je přesnost zpracovaných dat lepší.
- Nákladově efektivní : - Je nákladově efektivní a je levnější než jiné dostupné alternativy, díky nimž je silnější oproti průmyslovému využití. Vzhledem k tomu, že ceny jsou nižší, můžeme pojmout velké množství dat a zpracovat je v rámci rozpočtu.
- Rozhraní SQL : - Modul dotazu založený na Redshift je stejný jako u Postgres SQL, což vývojářům SQL usnadňuje hraní s ním.
- Zabezpečení : - Data uvnitř Redshift jsou šifrovaná, která jsou k dispozici na více místech v RedShift. Můžeme také definovat pravidlo příchozí a odchozí, díky kterému jsou data mnohem bezpečnější.
Existuje mnohem více výhod, že redshift je lepší volbou pro datový sklad.
Ceny AWS RedShift -
RedShift přichází s úžasným seznamem cen, který přitahuje vývojáře nebo trh k němu. Protože přichází s funkcí ceny na vyžádání, můžeme ji použít jen přes hodinovou základnu a počet uzlů v našem klastru. Spectrum Pricing nám pomáhá spouštět dotazy SQL přímo proti všem našim datům.
Můžeme vytvořit velké datové sklady pomocí HDD za velmi nízkou cenu. Více informací o přesných podrobnostech o cenách najdete v dokumentu Amazon:
https://aws.amazon.com/redshift/pricing/
Výše uvedený dokument obsahuje všechny podrobnosti o různých cenách pro AWS REDSHIFT.
Závěr
Z výše uvedeného článku, který jsme viděli pro Redshift, musíme mít spravedlivou představu o tom, co je vlastně redshift a jeho použití. RedShift, který je tak velmi škálovatelný a snadno použitelný, je v průmyslu nejpoužívanější díky podpoře různých dalších technologií Amazonu, díky kterým je výkonnější. Takže ve světě plném dat Redshift přichází s velmi dobrým balíčkem datových skladů a zpracování.
Doporučené články
Toto je průvodce Co je AWS RedShift. Zde diskutujeme o práci, používání a výhodách AWS RedShift. Další informace naleznete také v následujícím článku -
- Architektura AWS
- Co je AWS?
- Co je Azure?
- Co je AWS Lambda?
- AWS Storage Services