

Úvod do architektury Hadoop
Hadoop Architecture je open source framework, který pomáhá při snadném zpracování velkých datových souborů. Pomáhá při vytváření aplikací, které zpracovávají obrovská data rychleji. Využívá distribuované výpočetní koncepty, kde jsou data šířena napříč různými uzly klastru. Aplikace vytvořené pomocí Hadoop využívají komoditní počítače. Tyto počítače jsou na trhu snadno dostupné za nízké ceny. Tento výsledek dosahuje vyšší výpočetní síly při nízkých nákladech. Všechna data v Hadoopu jsou umístěna na HDFS namísto lokálního systému souborů. HDFS je distribuovaný systém souborů Hadoop. Tento model je založen na datové lokalitě, kde je výpočetní logika odeslána do uzlů přítomných v klastru, který obsahuje data. Tato logika není nic jiného než logika, která sestavuje program.
Hadoop architektura
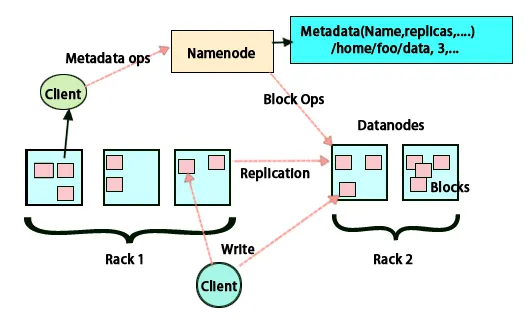
Základní myšlenkou této architektury je, že celé ukládání a zpracování se provádí ve dvou krocích a dvěma způsoby. Prvním krokem je zpracování, které se provádí programem Map redu a druhým krokem je ukládání dat, která se provádí na HDFS. Má architekturu master-slave pro ukládání a zpracování dat. Hlavní uzel pro ukládání dat v Hadoop je uzel s názvem. K dispozici je také hlavní uzel, který provádí monitorování a paralelní zpracování dat pomocí Hadoop Map Reduce. Otroky jsou další stroje v klastru Hadoop, které pomáhají při ukládání dat a také provádějí složité výpočty. Každý podřízený uzel má přiřazen sledovač úloh a datový uzel má sledovač úloh, který pomáhá při provádění procesů a jejich účinné synchronizaci. Tento typ systému lze nastavit buď na cloud, nebo na premise. Uzel Název je jediný bod selhání, když není spuštěn v režimu vysoké dostupnosti. Architektura Hadoop také obsahuje opatření pro udržování pohotovostního uzlu pro pohotovostní režim, aby byl systém chráněn před selháním. Dříve existovaly uzly sekundárních jmen, které fungovaly jako záloha, když byl uzel primárního názvu vypnutý.
FSimage and Edit Log
Protokol FSimage a Edit zajistí perzistenci metadat systému souborů, aby držely krok se všemi informacemi a uzel názvů ukládá metadata do dvou souborů. Tyto soubory jsou FSimage a protokol úprav. Úkolem FSimage je udržovat kompletní snímek systému souborů v daném čase. Změny, které jsou v systému neustále prováděny, musí být vedeny. Tyto dílčí změny, jako je přejmenování nebo přidání podrobností do souboru, jsou uloženy v protokolu úprav. Rámec poskytuje lepší možnost než vytvořit nový FSimage pokaždé, lepší možností je ukládat data a zároveň nový soubor pro FSimage. FSimage vytvoří nový snímek pokaždé, když jsou provedeny změny. Pokud uzel Název selže, může obnovit svůj předchozí stav. Uzel sekundárního názvu může také aktualizovat svou kopii, kdykoli dojde ke změnám v protokolech FSimage a úpravách. Tím je zajištěno, že i když je uzel názvu vypnutý, v přítomnosti sekundárního uzlu jména nedojde ke ztrátě dat. Uzel názvů nevyžaduje, aby se tyto obrazy musely znovu načíst do sekundárního uzlu názvů.
Replikace dat
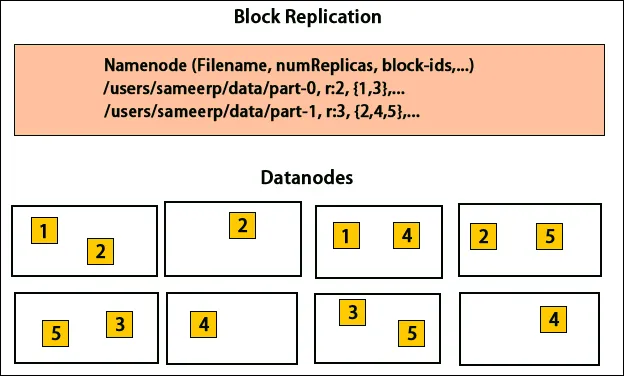
HDFS je navržen pro rychlé zpracování dat a poskytování spolehlivých dat. Ukládá data napříč stroji a ve velkých klastrech. Všechny soubory jsou uloženy v řadě bloků. Tyto bloky jsou replikovány pro odolnost proti chybám. O velikosti bloku a replikačním faktoru mohou rozhodovat uživatelé a konfigurovat podle požadavků uživatele. Ve výchozím nastavení je replikační faktor 3. Replikační faktor může být určen v okamžiku vytvoření souboru a může být později změněn. Všechna rozhodnutí týkající se těchto replik jsou přijímána jménem uzlu. Uzel názvu udržuje pravidelné odesílání prezenčních signálů a blokování zpráv pro všechny datové uzly v klastru. Přijetí prezenčního signálu znamená, že datový uzel funguje správně. Zpráva o bloku určuje seznam všech bloků přítomných v datovém uzlu.
Umístění replik
Umístění replik je v Hadoopu velmi důležitým úkolem pro spolehlivost a výkon. Všechny různé datové bloky jsou umístěny na různých stojanech. Implementaci umístění replik lze provést podle spolehlivosti, dostupnosti a využití šířky pásma sítě. Klastr počítačů lze rozložit do různých stojanů. Na jeden stojan nelze umístit více než dva uzly. Třetí replika by měla být umístěna na jiném stojanu, aby byla zajištěna větší spolehlivost dat. Dva uzly na stojanu komunikují prostřednictvím různých přepínačů. Uzel názvu má ID racku pro každý datový uzel. Umístění všech uzlů do různých stojanů však zabraňuje ztrátě veškerých dat a umožňuje využití šířky pásma z více stojanů. Rovněž snižuje provoz mezi stojany a zlepšuje výkon. Pravděpodobnost selhání stojanu je také ve srovnání s pravděpodobností selhání uzlu velmi menší. Snižuje celkovou šířku pásma sítě, když se data načítají ze dvou jedinečných stojanů, nikoli ze tří.
Mapa Reduce
Map Reduce se používá pro zpracování dat uložených na HDFS. Píše distribuovaná data napříč distribuovanými aplikacemi, což zajišťuje efektivní zpracování velkého množství dat. Zpracovávají na velkých klastrech a vyžadují zboží, které je spolehlivé a odolné vůči chybám. Jádrem programu Map-redukovat mohou být tři operace, jako je mapování, sběr párů a míchání výsledných dat.
Závěr - architektura Hadoop
Hadoop je open source framework, který pomáhá v systému odolném proti chybám. Může ukládat velké množství dat a pomáhá při ukládání spolehlivých dat. Dvě části ukládání dat v HDFS a jejich zpracování pomocí map-redukovat pomoc při správné a efektivní práci. Má architekturu, která pomáhá při správě všech bloků dat a také má nejnovější kopii tím, že je ukládá do FSimage a edituje protokoly. Faktor replikace také pomáhá při kopírování dat a jejich získávání zpět, kdykoli dojde k selhání. HDFS také přesouvá odstraněné soubory do koše pro optimální využití místa.
Doporučené články
Toto byl průvodce architekturou Hadoop. Zde jsme probrali architekturu, zmenšení mapy, umísťování replik, replikaci dat. Další informace naleznete také v dalších navrhovaných článcích -
- Staňte se vývojářem Hadoop
- Úvod do Androidu
- Co je Tableau? | Přehled
- Co je MapReduce v Hadoopu?