

Rozdíl mezi Hadoopem a Úlem
Hadoop:
Hadoop je Framework nebo Software, který byl vynalezen pro správu obrovských dat nebo Big Data. Hadoop se používá pro ukládání a zpracování velkých dat distribuovaných přes klastr komoditních serverů.
Hadoop ukládá data pomocí distribuovaného systému souborů Hadoop a zpracovává / dotazuje je pomocí programovacího modelu Map Reduce.
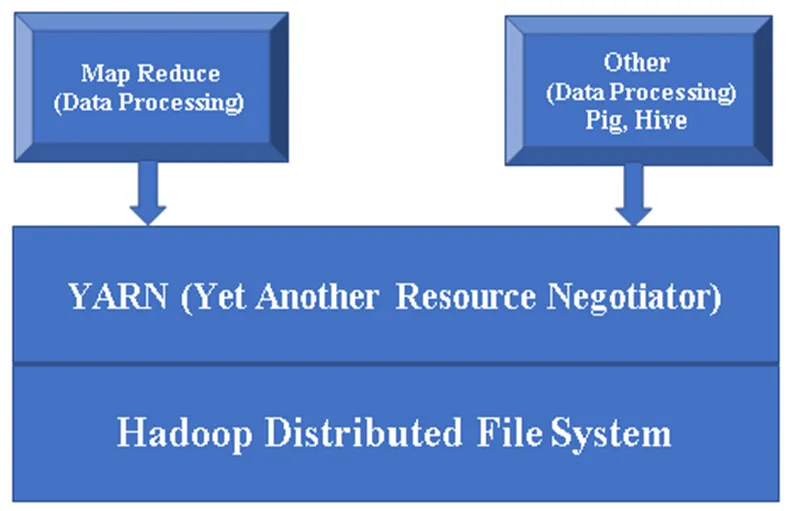
Obrázek 1, základní architektura komponenty Hadoop.
Hadoop hlavní komponenty:
Hadoop Base / Common: Hadoop common vám poskytne jednu platformu pro instalaci všech jeho komponent.
HDFS (Distribuovaný systém souborů Hadoop): HDFS je hlavní součástí rámce Hadoop a stará se o všechna data v Hadoop Cluster. Pracuje na architektuře Master / Slave a ukládá data pomocí replikace.
Master / Slave Architecture & Replication:
- Hlavní uzel / název: Uzel jména ukládá metadata každého bloku / souboru uloženého v HDFS, HDFS může mít pouze jeden hlavní uzel (v případě HA bude další hlavní uzel fungovat jako sekundární hlavní uzel).
- Uzel slave / datový uzel: Datové uzly obsahují skutečné datové soubory v blocích. HDFS může mít více datových uzlů.
- Replikace: HDFS ukládá svá data tak, že je rozdělí na bloky. Výchozí velikost bloku je 64 MB. Díky replikačním datům se data ukládají do 3 (výchozí replikační faktor, lze podle potřeby zvýšit) různé datové uzly, takže existuje nejmenší možnost ztráty dat v případě selhání uzlu.
YARN (Ještě jiný prostředek pro vyjednávání zdrojů): V zásadě se používá pro správu zdrojů Hadoop, také hraje důležitou roli při plánování aplikací uživatelů.
MR (Map Reduce): Toto je základní programovací model Hadoop. Používá se ke zpracování / dotazování dat v rámci Hadoop.
Úl:
Hive je aplikace, která běží přes rámec Hadoop a poskytuje rozhraní podobné SQL pro zpracování / dotazování dat. Úl je navržen a vyvinut společností Facebook, než se stane součástí projektu Apache-Hadoop.
Hive spustí svůj dotaz pomocí HQL (jazyk dotazu Hive). Úl má stejnou strukturu jako RDBMS a v Úlu lze použít téměř stejné příkazy.
Úl může ukládat data v externích tabulkách, takže není nutné používat HDFS a také podporuje formáty souborů, jako jsou ORC, Avro, Sequence File a Text soubory atd.
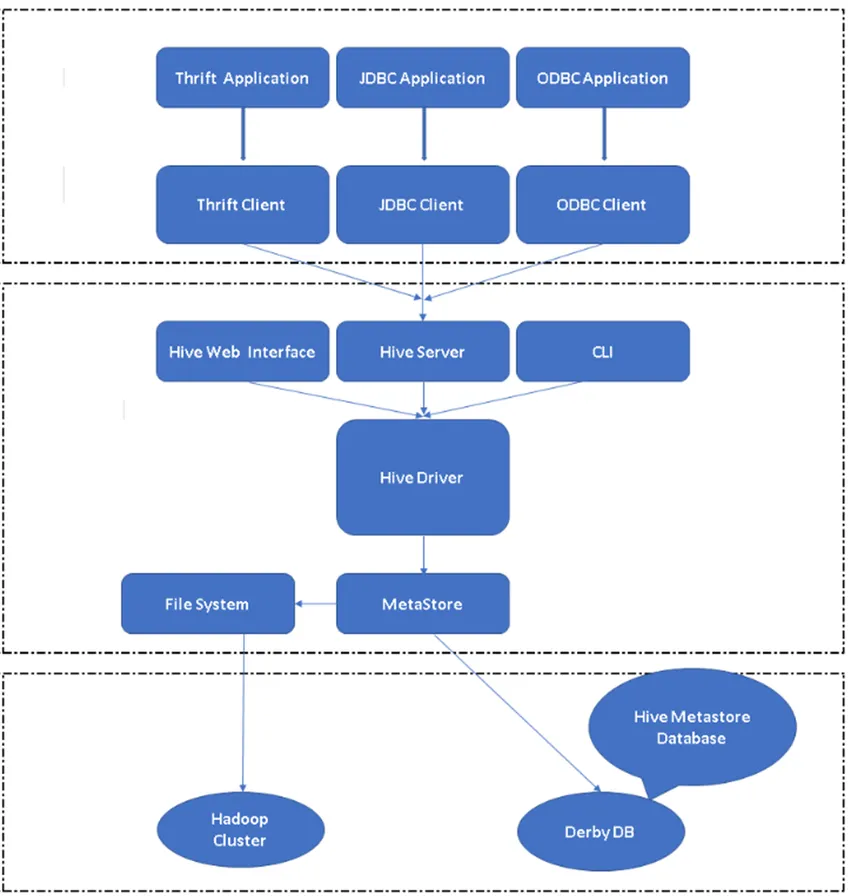
Obrázek 2, Hive's Architecture & Je to hlavní součást.
Hlavní komponenta Úlu:
Hive Clients: Nejen SQL, Hive také podporuje programovací jazyky jako Java, C, Python pomocí různých ovladačů jako ODBC, JDBC a Thrift. Člověk může psát jakoukoli klientskou aplikaci podregistru v jiných jazycích a pomocí těchto klientů může běžet v Úlu.
Služby podregistru: Ve službách podregistru probíhá provádění příkazů a dotazů. Webové rozhraní Úlu má pět dílčích složek.
- CLI: Výchozí rozhraní příkazového řádku poskytované Hive pro provádění dotazů / příkazů Hive.
- Hive Web Interfaces: Jedná se o jednoduché grafické uživatelské rozhraní. Je to alternativa k příkazovému řádku Hive a používá se ke spouštění dotazů a příkazů v aplikaci Hive.
- Hive Server: Nazývá se také Apache Thrift. Je odpovědné přijímat příkazy z různých rozhraní příkazového řádku a odesílat všechny příkazy / dotazy Hive a také získává konečný výsledek.
- Ovladač Apache Hive: Je zodpovědný za převzetí vstupů z rozhraní CLI, webového uživatelského rozhraní, ODBC, JDBC nebo Thrift klientem a předání informací metastoru, kde jsou uloženy všechny informace o souborech.
- Metastore: Metastore je úložiště pro uložení všech informací o metadatech Úlu. Metadata Hive ukládají informace, jako je struktura tabulek, oddílů a typu sloupců atd.…
Úložné úložiště: Je to místo, kde se provádí skutečná úloha. Všechny dotazy spuštěné z Úlu provedly akci uvnitř Úložného úložiště.
Srovnání mezi hlavami mezi Hadoopem a Úlem (infografika)
Níže je osm nejlepších rozdílů mezi Hadoopem a Hive
Klíčové rozdíly mezi Hadoop vs Hive:
Níže jsou uvedeny seznamy bodů, které popisují klíčové rozdíly mezi Hadoop a Hive:
1) Hadoop je rámec pro zpracování / dotazování velkých dat, zatímco Hive je nástroj založený na SQL, který vytváří přes Hadoop zpracování dat.
2) Zpracovat / dotazovat všechna data pomocí HQL (Hive Query Language), je to jazyk podobný SQL, zatímco Hadoop dokáže porozumět pouze Map Reduce.
3) Mapa Reduce je nedílnou součástí Hadoopu, Hiveho dotaz se nejprve převede na Map Reduce, než jak jej zpracoval Hadoop pro dotazování dat.
4) Hive pracuje na dotazu SQL Like, zatímco Hadoop to chápe pouze pomocí Java Map Mapu Reduce.
5) V Hive, dříve používané tradiční příkazy „Relational Database's“, lze také použít k dotazování na velká data, zatímco v Hadoopu musí psát složité programy Map Reduce pomocí Java, která není podobná jako tradiční Java.
6) Úl může zpracovávat / dotazovat pouze strukturovaná data, zatímco Hadoop je určen pro všechny typy dat, ať už se jedná o strukturovaná, nestrukturovaná nebo polostrukturovaná.
7) Pomocí Hive lze zpracovávat / dotazovat data bez složitého programování, zatímco v ekosystému Simple Hadoop je třeba psát komplexní Java program pro stejná data.
8) Rámce Hadoop na jedné straně vyžadují řádek 100 s pro přípravu MR programu založeného na Java. Druhá strana Hadoop with Hive může dotazovat stejná data pomocí 8 až 10 řádků HQL.
9) V Hive je velmi obtížné vložit výstup jednoho dotazu jako vstup jiného, zatímco stejný dotaz lze snadno provést pomocí Hadoop s MR.
10) Není povinné mít Metastore v klastru Hadoop, zatímco Hadoop ukládá všechna svá metadata do HDFS (Hadoop Distributed File System).
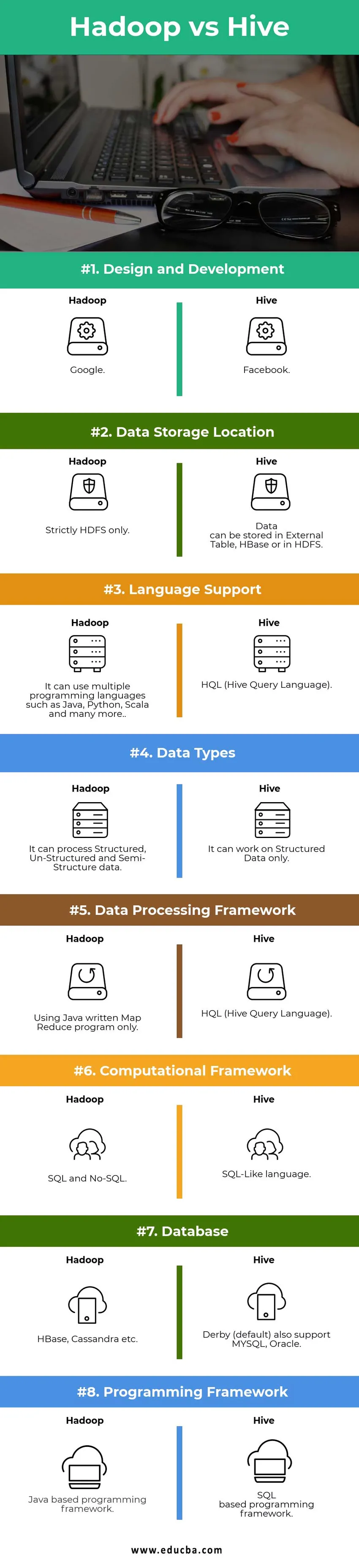
Srovnávací tabulka Hadoop vs Hive
| Srovnávací body | Úl | Hadoop |
|
Návrh a vývoj | ||
| Umístění úložiště dat |
Data mohou být uložena v externím zařízení Tabulka, HBase nebo v HDFS. | Pouze striktně HDFS. |
| Jazyková podpora | HQL (jazyk dotazu úlu) |
Může používat více programovacích jazyků, jako je Java, Python, Scala a mnoho dalších. |
| Typy dat | Může pracovat pouze na strukturovaných datech. |
Může zpracovávat strukturovaná, nestrukturovaná a polostrukturovaná data. |
| Framework pro zpracování dat |
HQL (jazyk dotazu úlu) | Používání pouze programu Java Map Mapuce. |
|
Výpočetní rámec | SQL-jako jazyk. | SQL a No-SQL. |
| Databáze |
Derby (výchozí) také podporuje MYSQL, Oracle… | HBase, Cassandra atd.…. |
| Programovací rámec |
Programovací rámec založený na SQL. | Programovací rámec Java. |
Závěr - Hadoop vs Hive
Hadoop a Hive se používají ke zpracování velkých dat. Hadoop je rámec, který poskytuje platformu pro další aplikace pro dotazování / zpracování Big Data, zatímco Hive je pouze aplikace založená na SQL, která zpracovává data pomocí HQL (Hive Query Language).
Hadoop lze použít bez Hive ke zpracování velkých dat, zatímco použití Hive bez Hadoop není snadné.
Závěrem nemůžeme srovnávat Hadoop a Hive v žádném případě a v žádném ohledu. Hadoop i Hive jsou úplně jiné. Společné fungování obou technologií může pro uživatele velkých dat výrazně usnadnit a usnadnit zpracování dotazů na velká data.
Doporučené články:
Toto byl průvodce Hadoop vs Hive, jejich význam, srovnání hlava-hlava, hlavní rozdíly, srovnávací tabulka a závěr. Další informace naleznete také v následujících článcích -
- Hadoop vs Apache Spark - Zajímavé věci, které potřebujete vědět
- HADOOP vs RDBMS | Poznejte 12 užitečných rozdílů
- Jak velká data mění tvář zdravotnictví
- Top 12 Porovnání Apache Hive vs Apache HBase (Infographics)
- Úžasný průvodce Hadoop vs Spark