
Co je Úl?
Předtím, než nejprve porozumíme datovým typům úlu, prozkoumáme úl. Úl je technika Hadoop pro skladování dat. Hadoop je segment ukládání a zpracování dat velké datové platformy. Úl si drží pozici pro techniky zpracování dat pokračování. Stejně jako ostatní pokračovací prostředí lze úlu dosáhnout prostřednictvím následných dotazů. Hlavními nabídkami úlu jsou analýza dat, ad-hoc dotazování a shrnutí uložených dat z hlediska latence, dotazy jdou větší množství.
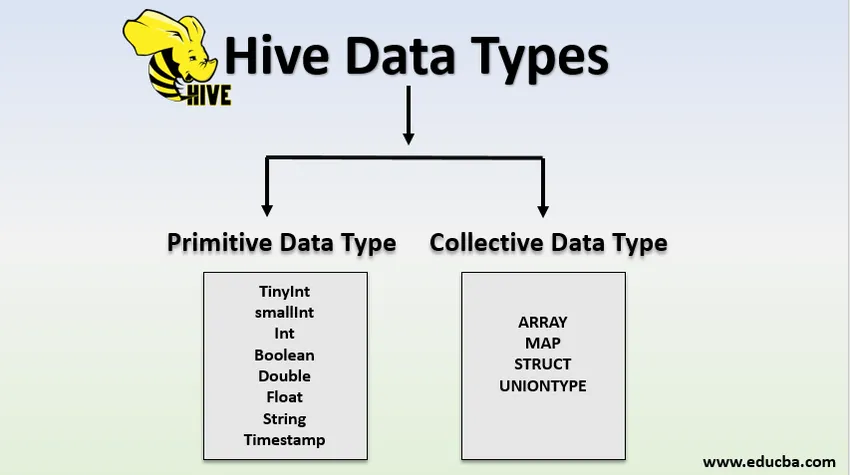
Typy úlů
Datové typy jsou rozděleny do dvou typů:
- Primitivní datové typy
- Typy hromadných dat
1. Primitivní datové typy
Primitivní prostředky byly staré a staré. všechny datové typy uvedené jako primitivní jsou starší. níže uvedené důležité primitivní oblasti datových typů:
| Typ | Velikost (bajt) | Příklad |
| TinyInt | 1 | 20 |
| SmallInt | 2 | 20 |
| Int | 4 | 20 |
| Bigint | 8 | 20 |
| Boolean | Boolean true / False | NEPRAVDIVÉ |
| Dvojnásobek | 8 | 10, 222 |
| Plovák | 4 | 10, 222 |
| Tětiva | Posloupnost znaků | abeceda |
| Časová známka | Celé číslo / float / string | 2/3/2012 12: 34: 56: 1234567 |
| datum | Celé číslo / float / string | 3. 3.1919 |
Datové typy úlu jsou implementovány pomocí JAVA
Příklad: Java Int se zde používá pro implementaci datového typu Int.
- V HIVE nejsou podporována znaková pole.
- Úl spoléhá na oddělovače, aby oddělil svá pole, úl na koordinaci s Hadoop umožňuje zvýšit výkon zápisu a čtení.
- V databázi úlu se neočekává zadání délky každého sloupce.
- Řetězcové literály lze artikulovat v obou uvozovkách („) jednoduchých uvozovkách (').
- V novější verzi úlu jsou představeny typy Varchar, které vytvářejí rozpětí specifikátoru (uprostřed 1 a 65535). Takže pro řetězec znaků to funguje jako největší délka hodnoty, kterou dokáže pojmout. Je-li vložena hodnota přesahující tuto délku, budou oříznuty nejvzdálenější prvky těchto hodnot. Délka znaku je rozlišení s číslem kódových bodů řízených řetězcem znaků.
- Všechny celočíselné literály (TINYINT, SMALLINT, BIGINT) jsou v podstatě považovány za datové typy INT a pouze délka překračuje skutečnou úroveň int, která je převedena na BIGINT nebo jakýkoli jiný příslušný typ.
- Desítkové literály umožňují ve srovnání s typem DOUBLE definované hodnoty a vynikající sbírku hodnot s pohyblivou řádovou čárkou. Zde jsou číselné hodnoty uloženy v jejich přesném tvaru, ale v případě dvojnásobku nejsou uloženy přesně jako číselné hodnoty.
Proces odlévání hodnoty data
| Obsazení provedeno | Výsledek |
| obsazení (datum jako datum) | Stejná hodnota data |
| obsazení (časové razítko jako datum) | Místní časové pásmo se používá k vyhodnocení hodnot rok / měsíc / datum a vytiskne se na výstupu. |
| obsazení (řetězec jako datum) | Výsledkem tohoto obsazení bude výzva k odpovídající hodnotě data, ale musíme se ujistit, že řetězec je ve formátu „RRRR-MM-DD“. Null bude vrácena, pokud hodnota řetězce nedokáže platnou shodu. |
| obsazení (datum jako časové razítko) | Podle aktuálního místního časového pásma bude pro tento proces odesílání vytvořena hodnota časového razítka |
| obsazení (datum jako řetězec) | RRRR-MM-DD je vytvořen pro hodnotu rok / měsíc / datum a výstup bude ve formátu řetězce. |
2. Typy dat kolekce
V úlu jsou čtyři datové typy kolekce, které se také nazývají komplexními datovými typy.
- ARRAY
- MAPA
- STRUCT
- UNIONTYPE
1. ARRAY: Posloupnost prvků běžného typu, které lze indexovat a hodnota indexu začíná od nuly.
Kód:
array ('anand', 'balaa', 'praveeen');
2. MAP: Jedná se o prvky, které jsou deklarovány a načteny pomocí párů klíč-hodnota.
Kód:
'firstvalue' -> 'balakumaran', 'lastvalue' -> 'pradeesh' is represented as map('firstvalue', 'balakumaran', 'last', 'PG'). Now 'balakumaran ' can be retrived with map('first').
3. STRUCT: Stejně jako v C, struct je datový typ, který akumuluje sadu polí, která jsou označena a mohou mít jakýkoli jiný typ dat.
Kód:
For a column D of type STRUCT (Y INT; Z INT) the Y field can be retrieved by the expression DY
4. UNIONTYPE: Unie může pojmout kterýkoli ze specifikovaných typů dat.
Kód:
CREATE TABLE test(col1 UNIONTYPE ) CREATE TABLE test(col1 UNIONTYPE )
Výstup:

Níže jsou uvedeny různé oddělovače používané ve složitých typech dat,
| Oddělovač | Kód | Popis |
| \ n | \ n | Oddělovač záznamu nebo řádku |
| A (Ctrl + A) | \ 001 | Oddělovač pole |
| B (Ctrl + B) | \ 002 | STRUCTS A ARRAYS |
| C (Ctrl + C) | \ 003 | MAP |
Příklad složitých datových typů
Níže uvádíme příklady komplexních datových typů:
1. TABULKA VYTVOŘENÍ
Kód:
create table store_complex_type (
emp_id int,
name string,
local_address STRUCT,
country_address MAP,
job_history array)
row format delimited fields terminated by ', '
collection items terminated by ':'
map keys terminated by '_';
2. VZOROVÉ TABULKY ÚDAJŮ
Kód:
100, Shan, 4th : CHN : IND : 600101, CHENNAI_INDIA, SI : CSC
101, Jai, 1th : THA : IND : 600096, THANJAVUR_INDIA, HCL : TM
102, Karthik, 5th : AP : IND : 600089, RENIKUNDA_INDIA, CTS : HCL
3. NAKLÁDÁNÍ ÚDAJŮ
Kód:
load data local inpath '/home/cloudera/Desktop/Hive_New/complex_type.txt' overwrite into table store_complex_type;
4. ZOBRAZENÍ ÚDAJŮ
Kód:
select emp_id, name, local_address.city, local_address.zipcode, country_address('CHENNAI'), job_history(0) from store_complex_type where emp_id='100';
Závěr - typy dat úlu
Být na relační DB a přesto Sequel spojuje, HIVE nabízí všechny klíčové vlastnosti obvyklých SQL databází velmi sofistikovaným způsobem, díky čemuž je tato mezi účinnějšími jednotkami strukturovaného zpracování dat v Hadoopu.
Doporučené články
Toto je průvodce datovým typem Úl. Zde diskutujeme dva typy datových typů podregistrů se správnými příklady. Další informace naleznete také v dalších souvisejících článcích -
- Co je Úl?
- Alternativy úlu
- Vestavěné funkce Úlu
- Hive Interview Otázky
- Datové typy PL / SQL
- Příklady vestavěných funkcí Pythonu
- Různé typy dat SQL s příklady