

Co je Hive Function?
Jak víme dnes, Hadoop je jednou z univerzálních technologií ve velkých datech. Hadoop má schopnost vyrovnat se s velkým souborem dat, ale protože růst dat je úměrný, psaní programů snižování map je obtížné. Aby bylo možné provádět dotazy SQL, byla v HDFS představena jedna taková technologie, kterou představil Hadoop s názvem apache Hive, který založil Facebook. Úl je vysoce využíván analytikem dat. Jsou nasazeny pro tři funkce, jmenovitě: Sumarizace dat, analýza dat na distribuovaném souboru a dotaz na data. Hive poskytuje SQL dotazy jako HQL - jazyk vysokých dotazů podporuje DML, uživatelem definované funkce. Kompilátor úlů interně převádí tento dotaz na úlohy snižující mapy, což zjednodušuje práci Hadoop při psaní složitých programů. Mohli bychom najít úl v aplikacích, jako jsou datové sklady, vizualizace dat a ad-hoc analýza, google analytics. Klíčovou výhodou je, že využívají znalosti SQL, což je základní dovednost implementovaná napříč vědci v oboru dat a softwarovými profesionály.
Různé funkce úlu v detailu
Podregistr podporuje různé typy dat, které se nenacházejí v jiných databázových systémech. zahrnuje mapu, pole a strukturu. Úl má některé vestavěné funkce pro provádění několika matematických a aritmetických funkcí pro zvláštní účely. Funkce v úlu lze rozdělit do následujících typů. Jsou to vestavěné funkce a uživatelem definované funkce.
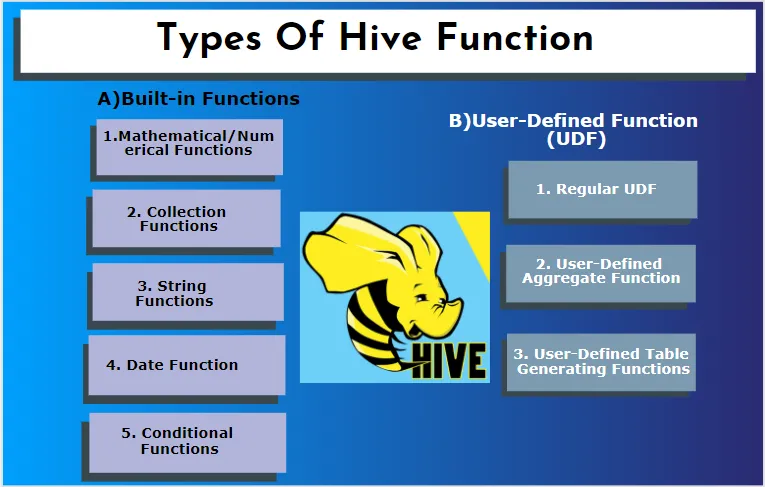
A) Vestavěné funkce
Tyto funkce extrahují data z tabulek podregistru a zpracovávají výpočty. Některé z vestavěných funkcí jsou:
1. Matematické / numerické funkce
Tyto funkce se používají hlavně pro matematické výpočty. Tyto funkce se používají v dotazech SQL.
| Název funkce | Příklad | Popis |
| ABS (double x) | Úl> vyberte ABS (-200) z tmp; | Vrátí absolutní hodnotu čísla. |
| CEIL (double x) | Úl> vyberte CEIL (8.5) z tmp; | Načte nejmenší celé číslo větší nebo rovno hodnotě x. |
| Rand (), rand (int seed) | Úl> vyberte Rand () z tmp;
Rand (0-9) | Vrací náhodné číslo, v závislosti na počáteční hodnotě, která by byla generovaná náhodná čísla určující. |
| Pow (double x, double y) | Úl> vyberte Pow (5, 2) z tmp; | Vrací hodnotu x zvýšenou na sílu y. |
| PODLAHA (double y) | Úl> vyberte PODLAHU (11, 8) z tmp; | Vrací maximální celé číslo menší než nebo rovno jako hodnota y. |
| EXP (double a) | Úl> vyberte Exp (30) z tmp; | Vrátí hodnotu exponentu 30. přirozených hodnot algoritmu. |
| PMOD (int a, int b) | Úl> vyberte PMOD (2, 4) z tmp; | Udává kladný modul čísla. |
2. Funkce kolekce
Výpis všech prvků dohromady a vrácení jednotlivých prvků závisí na zahrnutém typu dat.
| Název funkce | Příklad | Popis |
| Map_values (mapa) | Úl> vyberte Mapové hodnoty ('hi', 45) | Načte neuspořádané prvky pole. |
| Velikost (mapa) | Úl> vyberte velikost (mapa) | Vrátí počet prvků v mapě datového typu. |
| Array_contains (Array b) | Úl> select array_contains (a (10)) | Vrací TRUE, pokud pole obsahuje hodnotu. |
| Sort_array (pole a) | Úl> vyberte sort_array ((10, 3, 6, 1, 7)) | Seřadí vstupní pole ve vzestupném pořadí podle přirozeného uspořádání prvků pole a vrátí hodnotu. |
3. Řetězcové funkce
Pomocí řetězcových funkcí je analýza dat provedena excelentně.
| Split (string s, string pat) | Hive> select split ('educba ~ hive ~ Hadoop, ' ~ ') výstup: ("educba", "hive", "Hadoop") | Rozdělí řetězec kolem pat výrazů a vrátí matici. |
| zatížení (string s, int Len, string pad) | Úl> vyberte zatížení („EDUCBA“, 6, „H“) | Vrací řetězce s pravým polstrováním s délkou řetězce. (znak pad). |
| Délka (str. Str.) | Úl> vyberte délku ('educba') | Tato funkce vrací délku řetězce. |
| Rtrim (řetězec a) | Úl> vyberte rtrim ('TOPIC');
Výstup: 'Téma' | Vrací výsledek oříznutím mezer z pravých konců. |
| Concat (řetězec m, řetězec n) | Úl> vyberte concat ('data', 'ware') Výsledek: Dataware | Výsledkem je řetězec zřetězením dvou řetězců, což může mít libovolný počet vstupů. |
| Reverzní (řetězce) | Úl> vyberte reverzní („mobilní“) | Vrátí výsledek obráceného řetězce. |
4. Funkce data
Je nutné mít datový formát v podregistru, aby nedošlo k chybě Null na výstupu. Je nutné mít kompatibilitu data, aby bylo možné přejít s funkcemi data zavedenými v úlu.
| Unix_timestamp (Datum řetězce, řetězec) | Úl> vyberte časové razítko Unix_ ('2019-06-08', 'rrrr-mm-dd'); Výsledek: 124576 400 odebraného času: 0, 146 sekundy | Tato funkce vrací datum do specifického formátu a vrací sekundy mezi datem a Unixem. |
| Unix_timestamp (datum řetězce) | Úl> vyberte časové razítko Unix_ ('2019-06-08 09:20:10', 'rrrr-mm-dd'); | Vrací datum ve formátu „rrrr-MM-dd HH: mm: ss“ do časové značky Unix. |
| Hour (String date) | Úl> vyberte hodinu ('2019-06-08 09:20:10'); Výsledek: 09 hodin | Vrací hodinu časových razítek |
5. Podmíněné funkce
| Pokud (booleovský test, T hodnota true, t false) | Úl> vyberte IF (1 = 1, 'TRUE', 'FALSE') jako IF_CONDITION_TEST; | Kontroluje se podmínkou, zda je hodnota true, vrací 1 a false vrací 0. |
| Není null (b) | Úl> Vybrat není null (null); | To vyvolá null prohlášení. pokud null vrátí false. |
| Koalesce (hodnota1, hodnota2) | Příklad: úl> vyberte koalesci (Null, Null, 4, Null, 6). vrací 4. | Načte nejprve ne nulové hodnoty ze seznamu hodnot. |
B) Uživatelem definovaná funkce (UDF)
Podregistr používá uživatelské funkce podle požadavků klienta, které jsou zapsány v programování java. Je implementován dvěma rozhraními, a to jednoduchým API a komplexním API. Jsou vyvolány z dotazu úlu. Tři typy UDF:
1. Pravidelné UDF
Funguje na stole s jedním řádkem. Vytváří se vytvořením třídy java a poté jejich zabalením do souboru .jar. Dalším krokem je ověření pomocí cesty podregistru. a nakonec je provedeme v dotazu podregistru.
2. Uživatelem definovaná agregační funkce
Používají agregační funkce, jako je průměr / průměr, implementací pěti metod init (), iterate (), parciální (), merge (), terminate ().
3. Uživatelem definované funkce generování tabulky
Pracuje s jedním řádkem v tabulce a výsledkem je více řádků.
Závěr
Závěrem jsme se naučili, jak v tomto úlu pracovat s vestavěnými funkcemi a uživatelsky definovanými funkcemi. Většina organizací má programátora a vývojáře SQL, kteří pracují na procesu na straně serveru, ale úl apache je výkonný nástroj, který jim pomáhá používat framework Hadoop bez předchozích znalostí o programech a snižování map. Úl pomáhá novým uživatelům začít a prozkoumávat analýzu dat bez jakýchkoli překážek.
Doporučené články
Toto je průvodce funkcí Úlu. Zde diskutujeme o konceptu, dvou různých typech funkcí a dílčích funkcí v Úlu. Další informace naleznete také v dalších navrhovaných článcích -
- Nejlepší funkce řetězce v úlu
- Hive Interview Otázky
- Co je RMAN Oracle?
- Co je Waterfall Model?
- Úvod do architektury úlu
- Hive Order By