

Úvod do programu Spark SQL
Jak víme, spojení v SQL se používají ke kombinování dat nebo řádků ze dvou nebo více tabulek na základě společného pole mezi nimi. V tomto tématu se chystáme dozvědět více o připojení k Spark SQL Připojte se k Spark SQL.
Ve Spark SQL jsou Dataframe nebo Dataset tabulkovou strukturou v paměti, která má řádky a sloupce, které jsou distribuovány do více uzlů. Stejně jako běžné tabulky SQL, můžeme také provádět operace spojení na Dataframe nebo Datasetu přítomném ve Spark SQL na základě společného pole mezi nimi.
V SQL jsou k dispozici různé typy operací spojení. V závislosti na obchodním případu volíme operaci připojení. V následující části si ukážeme každý typ spojení s příkladem.
Typy spojení v programu Spark SQL
V Spark SQL jsou k dispozici různé typy spojení:
- VNITŘNÍ SPOJENÍ
- KRÍŽNÍ PŘIPOJENÍ
- LEFT OUTER JOIN
- PRÁVO VNĚJŠÍ PŘIPOJENÍ
- PLNÝ VNĚJŠÍ PŘIPOJENÍ
- LEFT SEMI JOIN
- LEFT ANTI JOIN
Příklad vytváření dat
Následující údaje použijeme k demonstraci různých typů spojení:
Soubor dat knihy:
case class Book(book_name: String, cost: Int, writer_id:Int)
val bookDS = Seq(
Book("Scala", 400, 1),
Book("Spark", 500, 2),
Book("Kafka", 300, 3),
Book("Java", 350, 5)
).toDS()
bookDS.show()

Dataset spisovatele:
case class Writer(writer_name: String, writer_id:Int)
val writerDS = Seq(
Writer("Martin", 1),
Writer("Zaharia " 2),
Writer("Neha", 3),
Writer("James", 4)
).toDS()
writerDS.show()

Druhy spojení
Níže je uvedeno 7 různých typů spojení:
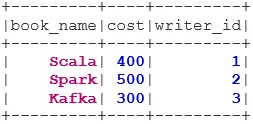
1. VNITŘNÍ PŘIPOJENÍ
INNER JOIN vrací dataset, který má řádky, které mají shodné hodnoty v obou datasetech, tj. Hodnota společného pole bude stejná.
val BookWriterInner = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "inner")
BookWriterInner.show()

2. PŘIPOJENÍ KŘÍŽE
CROSS JOIN vrací datovou sadu, což je počet řádků v první datové sadě vynásobený počtem řádků ve druhé datové sadě. Takový výsledek se nazývá karteziánský produkt.
Předpoklad: Pro použití křížového spojení musí být parametr spark.sql.crossJoin.enabled nastaven na true. Jinak bude vyvolána výjimka.
spark.conf.set("spark.sql.crossJoin.enabled", true)
val BookWriterCross = bookDS.join(writerDS)
BookWriterCross.show()
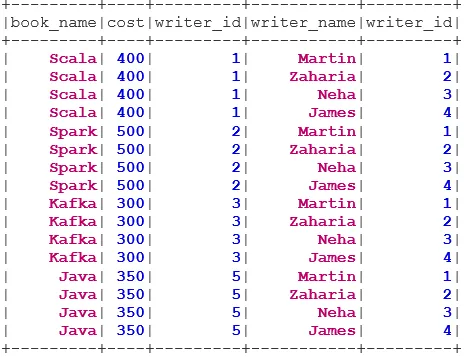
3. LEVÝ VNĚJŠÍ PŘIPOJENÍ
LEVÝ VNĚJŠÍ PŘIPOJENÍ vrátí datový soubor, který obsahuje všechny řádky z levého datového souboru a odpovídající řádky z pravého datového souboru.
val BookWriterLeft = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "leftouter")
BookWriterLeft.show()

4. PRÁVO VNĚJŠÍ PŘIPOJENÍ
PRAVÝ VNĚJŠÍ PŘIPOJENÍ vrátí datovou sadu, která obsahuje všechny řádky z pravého datového souboru a odpovídající řádky z levého datového souboru.
val BookWriterRight = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "rightouter")
BookWriterRight.show()

5. PLNÝ VNĚJŠÍ PŘIPOJENÍ
FULL OUTER JOIN vrací datovou sadu, která má všechny řádky, pokud existuje shoda v levém nebo pravém datovém souboru.
val BookWriterFull = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "fullouter")
BookWriterFull.show()

6. LEFT SEMI JOIN
VLEVO SEMI JOIN vrací dataset, který má všechny řádky z levého datasetu a jejich korespondence je v pravém datasetu. Na rozdíl od LEFT OUTER JOIN obsahuje vrácený dataset v LEFT SEMI JOIN pouze sloupce z levého datasetu.
val BookWriterLeftSemi = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "leftsemi")
BookWriterLeftSemi.show()
7. LEFT ANTI JOIN
ANTI SEMI JOIN vrací dataset, který obsahuje všechny řádky z levého datasetu, které nemají odpovídající údaje v pravém datasetu. Obsahuje také pouze sloupce z levého datového souboru.
val BookWriterLeftAnti = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "leftanti")
BookWriterLeftAnti.show()

Závěr - Připojte se k programu Spark SQL
Spojení dat je jednou z nejčastějších a nejdůležitějších operací pro splnění našeho obchodního použití. Spark SQL podporuje všechny základní typy spojení. Při připojování musíme brát v úvahu také výkon, protože mohou vyžadovat velké síťové přenosy nebo dokonce vytvářet datové sady mimo naši schopnost zpracovat. Pro zvýšení výkonu používá Spark k optimalizaci objednávek nebo tlačení filtrů SQL optimalizátor. Spark také omezuje nebezpečné spojení i. e CROSS JOIN. Pro použití křížového spojení musí být spark.sql.crossJoin.enabled explicitně nastaveno na true.
Doporučené články
Toto je průvodce, jak se připojit ke Spark SQL. Zde diskutujeme o různých typech spojení dostupných ve Spark SQL s příkladem. Můžete se také podívat na následující článek.
- Typy spojení v SQL
- Tabulka v SQL
- SQL Vložit dotaz
- Transakce v SQL
- PHP filtry | Jak ověřit vstup uživatele pomocí různých filtrů?