

Rozdíl mezi velkými daty a Apache Hadoop
Všechno je na internetu. Internet má mnoho dat. Proto je všechno Big Data. Víte, že 2, 5 milionu bajtů dat se vytváří každý den a hromadí se jako velká data? Naše každodenní aktivity, jako je komentování, hodnocení Líbí se, příspěvky atd. Na sociálních médiích jako Facebook, LinkedIn, Twitter a Instagram, se sčítají jako Big Data. Předpokládá se, že do roku 2020 bude vytvořeno téměř 1, 7 megabajtů dat každou sekundu, pro každou osobu na Zemi. Dokážete si představit a zvážit, kolik dat se generuje za předpokladu, že každá osoba na Zemi. Dnes jsme propojeni a sdílejí naše životy online. Většina z nás je připojena online. Žijeme v inteligentním domě a používáme inteligentní vozidla a všichni jsou připojeni k našim chytrým telefonům. Dovedete si někdy představit, jak se tato zařízení stávají chytrými? Rád bych vám dal velmi jednoduchou odpověď, protože je to kvůli analýze velkého množství dat, tj. Big Data. Do pěti let bude na světě více než 50 miliard inteligentních připojených zařízení, vše vyvinuté pro sběr, analýzu a sdílení dat, aby se náš život pohodlněji zlepšil.
Následuje úvod velkých dat vs Apache Hadoop
Představujeme termín Big Data
Co je Big Data? Jaká velikost dat je považována za velkou a bude označována jako velká data? Máme mnoho relativních předpokladů pro termín Big Data. Je možné, že množství dat říká, že 50 terabajtů lze pro začínající podniky považovat za velká data, ale nemusí to být velká data pro společnosti jako Google a Facebook. Je to proto, že mají infrastrukturu pro ukládání a zpracování tohoto množství dat. Chtěl bych definovat pojem Big Data jako:
- Big Data je množství dat, které přesahuje schopnost technologie efektivně ukládat, spravovat a zpracovávat.
- Big Data jsou data, jejichž rozsah, rozmanitost a složitost vyžadují novou architekturu, techniky, algoritmy a analytiku, které je spravují a extrahují z ní hodnoty a skryté znalosti.
- Velká data jsou velkoobjemová a vysokorychlostní a různorodá informační aktiva, která vyžadují nákladově efektivní, inovativní formy zpracování informací, které umožňují lepší přehled, rozhodování a automatizaci procesů.
- Big Data se týká technologií a iniciativ, které zahrnují data, která jsou příliš různorodá, rychle se měnící nebo masivní pro konvenční technologie, dovednosti a infrastrukturu pro efektivní řešení. Jinak řečeno, objem, rychlost nebo rozmanitost dat je příliš velká.
3 V z velkých dat
- Svazek: Svazek se týká množství / množství, ve kterém jsou data vytvářena, jako každá hodina, transakce zákazníků Wal-Mart poskytují společnosti asi 2, 5 petabajtů dat.
- Rychlost: Rychlost označuje rychlost, jakou se data pohybují, jako uživatelé Facebooku, odesílají v průměru 31, 25 milionu zpráv a sledují 2, 77 milionu videí každou minutu každý den přes internet.
- Odrůda: Odrůda se týká různých formátů dat, která jsou vytvářena jako strukturovaná, polostrukturovaná a nestrukturovaná data. Stejně jako odesílání e-mailů s přílohou v Gmailu jsou nestrukturovaná data, zatímco zveřejňování jakýchkoli komentářů pomocí některých externích odkazů se také nazývá nestrukturovaná data. Sdílení obrázků, zvukových klipů a videoklipů je nestrukturovaná forma dat.
Ukládání a zpracování tohoto obrovského objemu, rychlosti a rozmanitosti dat je velkým problémem. Musíme myslet na jinou technologii než RDBMS pro Big Data. Je to proto, že RDBMS je schopen ukládat a zpracovávat pouze strukturovaná data. Takže tady Apache Hadoop přichází jako záchrana.
Představujeme pojem Apache Hadoop
Apache Hadoop je softwarový rámec s otevřeným zdrojovým kódem pro ukládání dat a spouštění aplikací na klastrech komoditního hardwaru. Apache Hadoop je softwarový rámec, který umožňuje distribuovat zpracování velkých datových souborů napříč klastry počítačů pomocí jednoduchých programovacích modelů. Je navržen tak, aby se rozšířil od jednotlivých serverů po tisíce počítačů, z nichž každý nabízí místní výpočet a úložiště. Apache Hadoop je rámec pro ukládání a zpracování velkých dat. Apache Hadoop je schopen ukládat a zpracovávat všechny formáty dat, jako jsou strukturovaná, polostrukturovaná a nestrukturovaná data. Apache Hadoop je open source a komoditní hardware přinesl revoluci v IT průmyslu. Je snadno dostupný pro všechny úrovně společností. Nemusejí více investovat do založení klastru Hadoop a na jinou infrastrukturu. Podívejme se tedy na užitečný rozdíl mezi Big Data a Apache Hadoop podrobně v tomto příspěvku.
Rámec Apache Hadoop
Framework Apache Hadoop je rozdělen do dvou částí:
- Distribuovaný systém souborů Hadoop (HDFS): Tato vrstva je zodpovědná za ukládání dat.
- MapReduce: Tato vrstva je zodpovědná za zpracování dat v clusteru Hadoop.
Hadoop Framework je rozdělen na master a slave architecture. Vrstva Hadoop Distributed File System (HDFS) Název Uzel je hlavní komponentou, zatímco datový uzel je komponentou Slave, zatímco ve vrstvě MapReduce je Job Tracker hlavní komponentou, zatímco sledovač úloh je komponentou slave. Níže je diagram pro Apache Hadoop framework.
Proč je Apache Hadoop důležitý?
- Schopnost rychle ukládat a zpracovávat obrovské množství jakýchkoli dat
- Výpočetní výkon: Distribuovaný výpočetní model Hadoop rychle zpracovává velká data. Čím více výpočetních uzlů používáte, tím více výpočetního výkonu máte.
- Odolnost proti chybám: Zpracování dat a aplikací je chráněno proti selhání hardwaru. Pokud uzel klesne, úlohy jsou automaticky přesměrovány do jiných uzlů, aby se zajistilo, že distribuovaná výpočetní technika nezdaří. Automaticky se uloží více kopií všech dat.
- Flexibilita: Můžete uložit tolik dat, kolik chcete, a rozhodnout se, jak je později použít. To zahrnuje nestrukturovaná data, jako jsou text, obrázky a videa.
- Nízká cena: Open-source framework je zdarma a používá komoditní hardware k ukládání velkého množství dat.
- Škálovatelnost: Můžete snadno rozšířit svůj systém tak, aby zpracovával více dat, jednoduše přidáním uzlů. Je vyžadována malá administrace
Srovnání mezi hlavami mezi velkými daty a Apache Hadoop (infografika)
Níže je Top 4 srovnání mezi Big Data vs Apache Hadoop
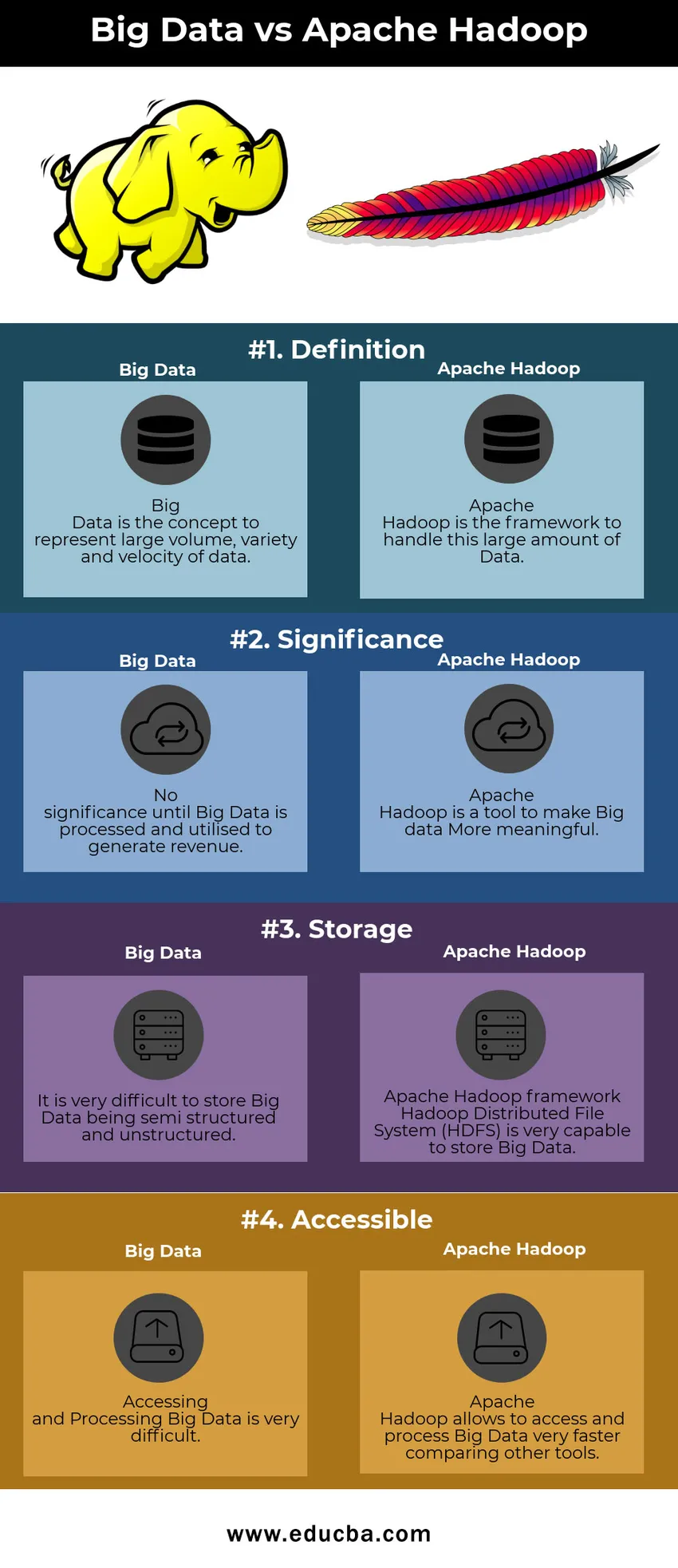
Srovnávací tabulka Big Data vs Apache Hadoop
Diskutuji o hlavních artefaktech a rozlišuji mezi Big Data vs Apache Hadoop
| Velká data | Apache Hadoop | |
| Definice | Big Data je koncept představující velký objem, rozmanitost a rychlost dat | Apache Hadoop je rámec pro zpracování tohoto velkého množství dat |
| Význam | Žádný význam, dokud nebude zpracována a použita velká data k vygenerování výnosů | Apache Hadoop je nástroj, díky kterému je Big Data smysluplnější |
| Úložný prostor | Je velmi obtížné ukládat Big Data jako polostrukturovanou a nestrukturovanou | Rámec Apache Hadoop Hadoop Distributed File System (HDFS) je velmi schopný ukládat velká data |
| Přístupné | Přístup a zpracování velkých dat je velmi obtížné | Apache Hadoop umožňuje velmi rychlý přístup a zpracování velkých dat ve srovnání s jinými nástroji |
Závěr - Big Data vs Apache Hadoop
Nelze porovnat Big Data a Apache Hadoop. Je to proto, že Big Data je problém, zatímco Apache Hadoop je Solution. Protože množství dat exponenciálně roste ve všech sektorech, je velmi obtížné ukládat a zpracovávat data z jediného systému. Abychom mohli zpracovat toto velké množství dat, potřebujeme distribuované zpracování a ukládání dat. Apache Hadoop proto přichází s řešením ukládání a zpracování velkého množství dat. Nakonec dospěju k závěru, že Big Data jsou velké množství komplexních dat, zatímco Apache Hadoop je mechanismus pro ukládání a zpracování velkých dat velmi efektivně a hladce.
Doporučený článek
Toto byl průvodce Big Data vs Apache Hadoop, jejich význam, Head to Head Srovnání, Key Differences, srovnávací tabulka a Závěr. tento článek se skládá ze všech užitečných rozdílů mezi Big Data a Apache Hadoop. Další informace naleznete také v následujících článcích -
- Big Data vs Data Science - Jak se liší?
- Top 5 velkých datových trendů, které budou společnosti muset zvládnout
- Hadoop vs Apache Spark - Zajímavé věci, které potřebujete vědět
- Apache Hadoop vs Apache Spark | Top 10 srovnání, které musíte znát!