

Úvod do těžby dat
Jedná se o metodu dolování dat používanou k umístění datových prvků do jejich podobných skupin. Cluster je procedura rozdělení datových objektů do podtříd. Kvalita shlukování závisí na použité metodě. Clustering se také nazývá segmentace dat, protože velké datové skupiny jsou rozděleny podle jejich podobnosti.
Co je shlukování v těžbě dat?
Clustering je seskupení konkrétních objektů na základě jejich charakteristik a jejich podobností. Pokud jde o dolování dat, tato metodika dělí data, která nejlépe vyhovují požadované analýze, pomocí speciálního algoritmu spojení. Tato analýza umožňuje, aby objekt nebyl součástí nebo přísně součástí klastru, který se nazývá tvrdé rozdělení tohoto typu. Hladké oddíly však naznačují, že každý objekt ve stejné míře patří do klastru. Specifičtější divize mohou být vytvořeny jako objekty více klastrů, jeden cluster může být nucen k účasti, nebo dokonce hierarchické stromy mohou být konstruovány ve skupinových vztazích. Tento souborový systém může být zaveden různými způsoby na základě různých modelů. Tyto odlišné algoritmy se vztahují na každý model, rozlišují jeho vlastnosti a výsledky. Dobrý klastrovací algoritmus je schopen identifikovat klastr nezávisle na tvaru klastru. Existují 3 základní fáze klastrovacího algoritmu, které jsou uvedeny níže
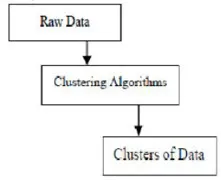
Clustering Algorithms in Mining Data
V závislosti na nedávno popsaných modelech klastrů lze mnoho klastrů použít k rozdělení informací do sady dat. Je třeba říci, že každá metoda má své výhody a nevýhody. Výběr algoritmu závisí na vlastnostech a povaze sady dat.
Metody klastru pro dolování dat lze znázornit níže
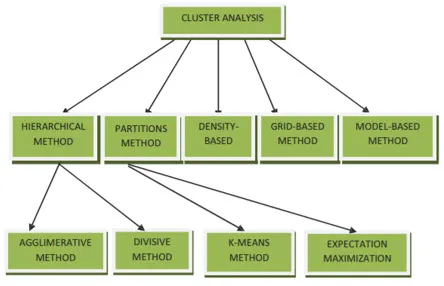
- Metoda založená na rozdělení
- Metoda založená na hustotě
- Metoda založená na Centroidu
- Hierarchická metoda
- Metoda založená na mřížce
- Metoda založená na modelu
1. Metoda založená na rozdělení
Algoritmus oddílu rozděluje data do mnoha podmnožin.
Předpokládejme, že algoritmus rozdělování vytvoří oddíl dat, protože k a n jsou objekty v databázi. Proto bude každý oddíl reprezentován jako k ≤ n.
To dává představu, že klasifikace dat je ve skupinách k, což lze vidět níže
Obrázek 1 ukazuje původní body při sdružování

Obrázek 2 ukazuje seskupení oddílů po použití algoritmu
To znamená, že každá skupina má alespoň jeden objekt, stejně jako každý objekt, musí patřit přesně do jedné skupiny.
2. Metoda založená na hustotě
Tyto algoritmy vytvářejí klastry v určeném umístění na základě vysoké hustoty účastníků datové sady. Agreguje určitou představu rozsahu pro členy skupiny v klastrech na standardní úroveň hustoty. Takové procesy mohou při detekci povrchových oblastí skupiny provádět méně.
3. Metoda založená na centroidu
Téměř na každý cluster je odkazován vektor hodnot v tomto typu techniky seskupování os. Ve srovnání s jinými klastry je každý objekt součástí klastru s minimálním rozdílem v hodnotě. Počet klastrů by měl být předdefinován, a to je největší problém s algoritmem tohoto typu. Tato metodika je nejblíže subjektu identifikace a je široce používána pro problémy optimalizace.
4. Hierarchická metoda
Metoda vytvoří hierarchický rozklad dané sady datových objektů. Na základě toho, jak se vytváří hierarchický rozklad, můžeme klasifikovat hierarchické metody. Tato metoda je uvedena následovně
- Aglomerativní přístup
- Divisivní přístup
Aglomerativní přístup je také známý jako přístup k tlačítkům. Zde začínáme u každého objektu, který tvoří samostatnou skupinu. Stále spojuje objekty nebo skupiny blízko sebe
Divisivní přístup je také známý jako přístup shora dolů. Začínáme se všemi objekty ve stejném clusteru. Tato metoda je rigidní, tj. Nemůže být nikdy vrácena po dokončení fúze nebo rozdělení
5. Metoda založená na mřížce
Metody založené na mřížce fungují v objektovém prostoru místo rozdělení dat do mřížky. Tabulka je rozdělena na základě charakteristik dat. Pomocí této metody lze snadno spravovat nečíselná data. Pořadí dat nemá vliv na rozdělení mřížky. Důležitou výhodou mřížkového modelu je vyšší rychlost provádění.
Výhody hierarchického klastru jsou následující
- Je použitelný na jakýkoli typ atributu.
- Poskytuje flexibilitu související s úrovní granularity.
6. Metoda založená na modelu
Tato metoda používá hypotetický model založený na rozdělení pravděpodobnosti. Shlukováním funkce hustoty tato metoda vyhledá klastry. Odráží prostorové rozložení datových bodů.
Aplikace shlukování v těžbě dat
Clustering může pomoci v mnoha oblastech, jako je biologie, rostliny a zvířata klasifikovaná podle jejich vlastností, stejně jako v marketingu. Clustering pomůže identifikovat zákazníky určitého zákaznického záznamu s podobným chováním. V mnoha aplikacích, jako je průzkum trhu, rozpoznávání vzorů, zpracování dat a obrázků, se shluková analýza používá ve velkém počtu. Clustering může také inzerentům v jejich zákaznické základně pomoci najít různé skupiny. A jejich skupiny zákazníků lze definovat nákupními vzory. V biologii se používá pro stanovení taxonomií rostlin a zvířat, pro kategorizaci genů s podobnou funkčností a pro nahlédnutí do struktur inherentních populaci. V databázi pozorování Země umožňuje seskupování také snazší najít oblasti podobného využití v zemi. Pomáhá identifikovat skupiny domů a bytů podle typu, hodnoty a cíle domů. Shlukování dokumentů na webu je také užitečné pro vyhledávání informací. Klastrová analýza je nástroj pro získání vhledu do distribuce dat k pozorování charakteristik každého klastru jako funkce dolování dat.
Závěr
Klastrování je důležité při těžbě dat a jejich analýze. V tomto článku jsme viděli, jak lze klastrování provést použitím různých klastrových algoritmů a jejich aplikací v reálném životě.
Doporučený článek
Toto byl průvodce „Co je klastrování v těžbě dat“. Zde jsme diskutovali o pojmech, definici, vlastnostech, použití klastru v těžbě dat. Další informace naleznete také v dalších navrhovaných článcích -
- Co je zpracování dat?
- Jak se stát analytikem dat?
- Co je SQL Injection?
- Definice toho, co je SQL Server?
- Přehled architektury dolování dat
- Shlukování ve strojovém učení
- Hierarchický klastrovací algoritmus
- Hierarchické klastry Aglomerativní a dělící se shlukování