

Úvod do Apache Flume
Apache Flume je Framework pro příjem dat, který zapisuje data založená na událostech do distribuovaného systému souborů Hadoop. Je známou skutečností, že Hadoop zpracovává velká data, vzniká otázka, jak jsou data generovaná z různých webových serverů přenášena do systému souborů Hadoop? Odpověď je Apache Flume. Flume je navržen pro velkoobjemové přijímání dat Hadoopu na základě událostí.
Zvažte scénář, ve kterém počet webových serverů generuje soubory protokolu a tyto soubory protokolu je třeba vyslat do systému souborů Hadoop. Flume shromažďuje tyto soubory jako události a prosazuje je o Hadoop. Ačkoli se Flume používá k přenosu do Hadoopu, neexistuje pevné pravidlo, že cílem musí být Hadoop. Flume dokáže zapisovat do jiných frameworků, jako je Hbase nebo Solr.
Flume Architecture
Obecně se architektura Apache Flume skládá z následujících komponent:
- Flume Source
- Flume Channel
- Flume Sink
- Flume Agent
- Flume Event
Podívejme se krátce na každou složku Flume
1. Flume Source
Zdroj Flume je přítomen u generátorů dat, jako je kniha knih nebo Twitter. Zdroj shromažďuje data z generátoru a přenáší je do kanálu Flume Channel ve formě Flume Events. Flume podporuje různé typy zdrojů, například Avro Flume Source - připojuje se k portu Avro a přijímá události od externího klienta Avro, Thrift Flume Source - připojuje se k portu Thrift a přijímá události z externích toků Thrift klientů, Zdroje zařazování adresářů a Zdroje Kafka Flume.
2. Flume Channel
Intermediate Store, který ukládá do vyrovnávací paměti události odeslané zdrojem Flume, dokud nejsou spotřebovány pomocí Sink, se nazývá Flume Channel. Kanál funguje jako přechodný most mezi zdrojem a dřezem. Flume Channels jsou transakční povahy.
Služba Flume poskytuje podporu pro souborový kanál a paměťový kanál. Kanál souborů je svou povahou trvalý, to znamená, že jakmile jsou data zapsána do kanálu, nebudou ztraceny, i když se agent restartuje. V paměti jsou události kanálu ukládány do paměti, takže to není trvanlivé, ale velmi rychlé povahy.
3. Flume Sink
Flume Sink je přítomen v datových úložištích jako HDFS, HBase. Flume dřez spotřebovává události z kanálu a ukládá je do cílových obchodů, jako je HDFS. Neexistuje pravidlo, že by umyvadlo mělo doručovat události do úložiště, místo toho ho můžeme nakonfigurovat tak, aby umyvadlo mohlo doručovat události jinému agentovi. Flume podporuje různá umyvadla jako je HDFS Sink, Hive Sink, Thrift Sink, Avro Sink.
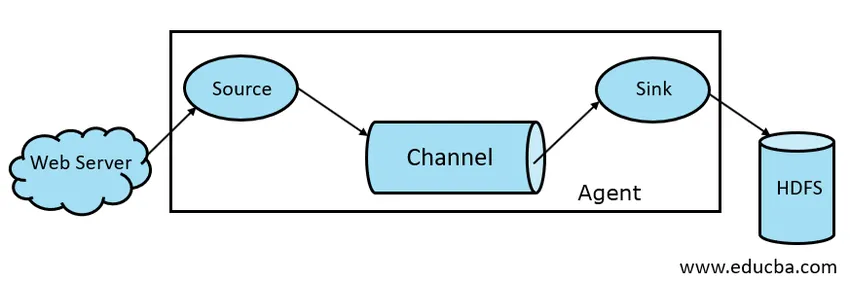
Obr. 1.1 Základní architektura žlabů
4. Flume Agent
Agent Flume je dlouhodobý proces Java, který běží na kombinaci Source - Channel - Sink. Flume může mít více než jednoho agenta. Můžeme považovat Flume za soubor připojených agentů Flume, které jsou distribuovány v přírodě.
5. Flume Event
Událost je jednotka dat přenášených v aplikaci Flume . Obecná reprezentace datového objektu v Flume se nazývá Event. Událost je tvořena užitečným zatížením bajtového pole s volitelnými záhlavími.
Práce s Flume
Agent Flume je java proces, který se skládá z Source - Channel - Sink ve své nejjednodušší formě. Zdroj shromažďuje data od generátoru dat ve formě Událostí a doručuje je na Kanál. Zdroj může dodávat na více kanálů podle požadavku. Fan out je proces, kdy jeden zdroj zapisuje na více kanálů, aby mohly dodávat na více dřezů.
Událost je základní jednotka dat přenášených v aplikaci Flume. Kanál vyrovnává data, dokud je nepřijme Sink. Sink shromažďuje data z kanálu a dodává je do centralizovaného úložiště dat, jako je HDFS nebo Sink, může tyto události podle potřeby předat jinému agentovi Flume.
Flume podporuje transakce. Za účelem dosažení spolehlivosti používá Flume oddělené transakce od zdroje k kanálu a od kanálu k jímce. Pokud události nejsou doručeny, je transakce vrácena zpět a později znovu doručena.
Abychom pochopili fungování Flume, vezměme si příklad konfigurace Flume, kde zdrojem je spooling adresář a dřezem jsou Hdfs. V tomto příkladu je agent Flume v nejjednodušší formě, tj. Topologie jednoho zdroje - kanálu - dřezu, která je konfigurována pomocí souboru vlastností java.
agent1.sources = source1
agent1.sinks = sink1
agent1.channels = channel1
agent1.sources.source1.channels = channel1
agent1.sinks.sink1.channel = channel1
agent1.sources.source1.type = spooldir
agent1.sources.source1.spoolDir = /tmp/spooldir
agent1.sinks.sink1.type = hdfs
agent1.sinks.sink1.hdfs.path = /tmp/flume
agent1.channels.channel1.type = file
Ve výše uvedeném příkladu konfigurace je agent základem, s nímž definujeme další vlastnosti. source1 a sink1 a channel1 jsou názvy zdroje, dřezu a kanálu a jejich typy a umístění jsou také odpovídajícím způsobem uvedeny.
Výhody Apache Flume
- Flume je v podstatě škálovatelný, spolehlivý a odolný vůči chybám. Tyto vlastnosti jsou podrobně popsány níže
- Škálovatelný - Flume je škálovatelný horizontálně, tj. Můžeme přidat nové uzly podle našeho požadavku
- Spolehlivý - Apache Flume má podporu pro transakce a zajišťuje, že během procesu přenosu dat nebudou ztracena žádná data. Má různé transakce od zdroje ke kanálu a od kanálu ke zdroji.
- Flume je přizpůsobitelný a poskytuje podporu pro různé zdroje a dřezy, jako je Kafka, Avro, zařazovací adresář, Thrift atd.
- V Flume může jediný zdroj přenášet data na více kanálů a tyto kanály zase přenášejí data na více dřezů, takže jediný zdroj může přenášet data na více dřezů. Tento mechanismus se nazývá Fan out. Flume také podporuje funkci Fan out.
- Flume poskytuje stálý tok přenosu dat, tj. Zvyšuje-li se rychlost čtení dat a zvyšuje se také rychlost zápisu dat.
- Přestože Flume obecně zapisuje data do centralizovaného úložiště, jako je HDFS nebo Hbase, můžeme nakonfigurovat Flume podle našich požadavků tak, aby Sink mohl zapisovat data jinému agentovi. To ukazuje flexibilitu Flume
- Apache Flume je v přírodě open source.
Závěr
V tomto článku Flume jsou podrobně diskutovány komponenty Flume a práce Flume. Flume je flexibilní, spolehlivá a škálovatelná platforma pro přenos dat do centralizovaného obchodu, jako je HDFS. Díky své schopnosti integrace s různými aplikacemi, jako jsou Kafka, Hdfs, Thrift, se stává životaschopnou možností pro příjem dat.
Doporučené články
Toto byl průvodce Apache Flume. Zde diskutujeme o architektuře, práci a výhodách Apache Flume. Další informace naleznete také v následujících článcích -
- Co je to Apache Flink?
- Rozdíl mezi Apache Kafka vs Flume
- Architektura velkých dat
- Hadoop Tools
- Naučte se různé události JavaScriptu