

Hluboké učení Interview Otázky a odpovědi
Dnes je Deep Learning považována za jednu z nejrychleji rostoucích technologií s obrovskou schopností vyvinout aplikaci, která byla někdy považována za těžkou. Rozpoznávání řeči, rozpoznávání obrazu, hledání vzorců v datovém souboru, klasifikace objektů ve fotografiích, generování textů postav, autosedačky a mnoho dalších je jen pár příkladů, kde Deep Learning ukázala svůj význam.
Takže jste konečně našli svou vysněnou práci v programu Deep Learning, ale přemýšlíte, jak rozbít rozhovor s Deep Learning Interview a jaké by mohly být pravděpodobné otázky Deep Learning Interview. Každý rozhovor je jiný a rozsah práce je také jiný. S ohledem na tuto skutečnost jsme navrhli nejčastější otázky a odpovědi týkající se rozhovoru Deep Learning Interview, které vám pomohou dosáhnout úspěchu v rozhovoru.
Níže je několik otázek z rozhovoru s Deep Learning Interview, které jsou v Interview často kladeny a které by také pomohly vyzkoušet vaše úrovně:
Část 1 - Otázky týkající se podrobného učení (základní)
Tato první část se zabývá základními otázkami a odpověďmi týkajícími se hlubokého učení
1. Co je hluboké učení?
Odpovědět:
Oblast strojového učení, která se zaměřuje na hluboké umělé neuronové sítě, které jsou volně inspirovány mozky. Alexey Grigorevich Ivakhnenko zveřejnil prvního generála o fungující síti hlubokého učení. Dnes má své uplatnění v různých oblastech, jako je počítačové vidění, rozpoznávání řeči, zpracování přirozeného jazyka.
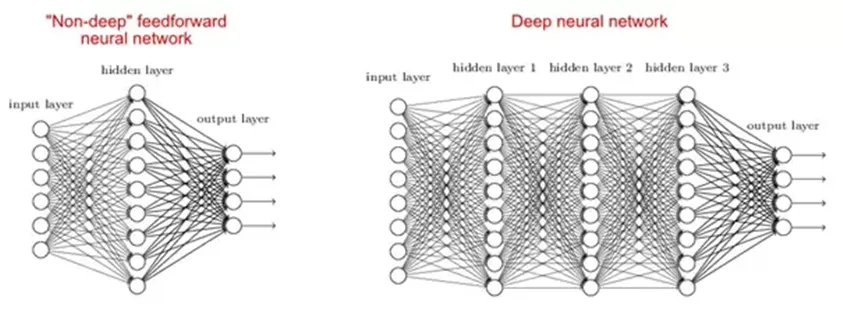
2. Proč jsou hluboké sítě lepší než mělké?
Odpovědět:
Existují studie, které říkají, že jak mělké, tak hluboké sítě se vejdou do jakékoli funkce, ale jelikož hluboké sítě mají několik skrytých vrstev, často různých typů, jsou schopny vytvářet nebo extrahovat lepší vlastnosti než mělké modely s menším počtem parametrů.
3. Jaká je nákladová funkce?
Odpovědět:
Nákladová funkce je míra přesnosti neuronové sítě s ohledem na daný tréninkový vzorek a očekávaný výstup. Je to jediná hodnota, nonvector, protože poskytuje výkon neuronové sítě jako celku. Lze jej vypočítat podle níže uvedené funkce Střední střední chyba chyby: -
MSE = 1n∑i = 0n (Y i – Yi) 2
Kde Y a požadovaná hodnota Y je to, co chceme minimalizovat.
Vraťme se k dalším otázkám hlubokého učení.
4. Co je gradient klesání?
Odpovědět:
Sestup z přechodu je v zásadě optimalizační algoritmus, který se používá ke zjištění hodnoty parametrů, které minimalizují nákladovou funkci. Je to iterační algoritmus, který se pohybuje ve směru nejstrmějšího sestupu, jak je definováno záporem gradientu. Vypočítáme gradient klesání nákladové funkce pro daný parametr a aktualizujeme jej pomocí následujícího vzorce: -
Θ: = Θ – αd∂ΘJ (Θ)
Kde Θ - je vektor parametrů, α - rychlost učení, J (Θ) - je nákladová funkce.
5. Co je to backpropagation?
Odpovědět:
Backpropagation je výcvikový algoritmus používaný pro vícevrstvou neuronovou síť. V této metodě přesuneme chybu z konce sítě do všech hmotností uvnitř sítě, což umožňuje efektivní výpočet gradientu. Lze ji rozdělit do několika kroků takto: -
OrPřed šíření tréninkových dat za účelem generování výstupu.
HenPři použití cílové hodnoty a derivace chyby výstupní hodnoty lze vypočítat s ohledem na aktivaci výstupu.
HenPokud se vrátíme zpět k výpočtu derivace chyby s ohledem na aktivaci výstupu na předchozí a pokračujeme v této činnosti u všech skrytých vrstev.
Pomocí dříve vypočítaných derivátů pro výstup a všech skrytých vrstev vypočítáme derivace chyb s ohledem na hmotnosti.
A pak aktualizujeme váhy.
6. Vysvětlete následující tři varianty gradientu sestupu: šaržové, stochastické a minidávkové?
Odpovědět:
Stochastické klesání : Zde používáme pouze jediný příklad školení pro výpočet parametrů přechodu a aktualizace.
Batch Gradient Descent : Zde vypočítáme gradient pro celý soubor dat a provádíme aktualizaci při každé iteraci.
Mini-batch Gradient Descent : Je to jeden z nejpopulárnějších optimalizačních algoritmů. Je to varianta stochastického přechodu a zde se místo jediného tréninkového příkladu používá mini-šarže vzorků.
Část 2 - Hluboké výukové rozhovory (pokročilé)
Pojďme se nyní podívat na pokročilé otázky týkající se rozhovoru Deep Learning Interview.
7. Jaké jsou výhody sestupu s malými dávkami?
Odpovědět:
Níže jsou uvedeny výhody mini-dávkového přechodu
• To je účinnější ve srovnání se stochastickým klesáním.
• Generalizace nalezením minima bytu.
• Mini-šarže umožňují pomoci přibližovat sklon celé tréninkové sady, což nám pomáhá vyhýbat se místním minimům.
8. Co je to normalizace dat a proč je potřebujeme?
Odpovědět:
Normalizace dat se používá během backpropagace. Hlavním motivem normalizace dat je snížení nebo odstranění redundance dat. Zde změníme hodnoty tak, aby se vešly do konkrétního rozmezí, abychom dosáhli lepší konvergence.
Vraťme se k dalším otázkám hlubokého učení.
9. Co je inicializace váhy v neuronových sítích?
Odpovědět:
Inicializace váhy je jedním z velmi důležitých kroků. Inicializace špatné váhy může zabránit síti v učení, ale dobrá inicializace váhy pomáhá při rychlejší konvergenci a lepší celkové chybě. Předpětí lze obecně inicializovat na nulu. Pravidlo pro nastavení hmotnosti musí být blízké nule, aniž by bylo příliš malé.
10. Co je to automatický kodér?
Odpovědět:
Autoencoder je autonomní algoritmus strojového učení, který používá princip backpropagation, kde jsou cílové hodnoty nastaveny tak, aby odpovídaly poskytnutým vstupům. Interně má skrytou vrstvu, která popisuje kód používaný k reprezentaci vstupu.
Některá klíčová fakta o autoencoderu jsou následující: -
• Jedná se o nepodřízený algoritmus ML podobný analýze hlavních komponent
• Minimalizuje stejnou objektivní funkci jako analýza hlavních komponent
• Je to neuronová síť
• Cílovým výstupem neuronové sítě je její vstup
11. Je v pořádku připojení z výstupu vrstvy 4 zpět ke vstupu vrstvy 2?
Odpovědět:
Ano, to lze provést s ohledem na to, že výstup vrstvy 4 je z předchozího časového kroku jako v RNN. Musíme také předpokládat, že předchozí vstupní dávka je někdy korelována s aktuální dávkou.
Vraťme se k dalším otázkám hlubokého učení.
12. Co je Boltzmann stroj?
Odpovědět:
Boltzmann Machine se používá k optimalizaci řešení problému. Práce stroje Boltzmann spočívá v podstatě v optimalizaci hmotností a množství pro daný problém.
Několik důležitých bodů o stroji Boltzmann -
• Používá opakující se strukturu.
• Skládá se ze stochastických neuronů, které se skládají z jednoho ze dvou možných stavů, buď 1 nebo 0.
• Neurony jsou v adaptivním stavu (volný stav) nebo upnuté (zmrazený stav).
• Pokud použijeme simulované žíhání na diskrétní síť Hopfield, stane se z něj Boltzmann Machine.
13. Jaká je role aktivační funkce?
Odpovědět:
Aktivační funkce se používá k zavedení nelinearity do neuronové sítě, která jí pomáhá naučit se složitější funkce. Bez nichž by se neuronová síť mohla naučit pouze lineární funkci, která je lineární kombinací jejích vstupních dat.
Doporučené články
Toto byl průvodce seznamem otázek a odpovědí na rozhovor v hlubokém učení, aby uchazeč mohl snadno odpovědět na tyto otázky. Další informace naleznete také v následujících článcích
- Naučte se 10 nejužitečnějších rozhovorů s HBase
- Užitečné otázky týkající se strojového učení a odpovědi
- Top 5 nejdůležitějších otázek rozhovoru s daty vědy
- Důležité otázky a odpovědi na rozhovor s Ruby Interview