

Rozdíl mezi Apache Hive a Apache HBase -
Příběh Apache Hive začíná v roce 2007, kdy jiný než Java Programátor musí bojovat při používání Hadoop MapReduce. Vědci a vývojáři předpovídali, že zítra je éra Big Data. Shromažďovaly se již různé formáty dat, jako strukturovaná, polostrukturovaná a nestrukturovaná. I Facebook zápasil s větším objemem zpracování dat. Vědci na Facebooku představili Apache Hive pro zpracování dat v Hadoop Cluster. Facebook byl první společností, která přišla s Apache Hive.
Příběh Apache HBase začíná v roce 2006, kdy se Powerset se spuštěním v San Franciscu snažil vytvořit webový vyhledávací stroj v přirozeném jazyce. HBase je implementace Bigtable společnosti Google. Uvědomili jsme si někdy, proč je třeba přijít s další architekturou úložiště? Systém správy relačních databází existuje již od počátku sedmdesátých let. Existuje mnoho případů použití, pro které relační databáze dokonale dávají smysl, ale u některých specifických problémů se relační model nehodí velmi dobře.
Dovolte mi podrobněji vysvětlit Apache Hive a Apache HBase.
Rozdíly mezi Apache Hive a Apache HBase
Apache Hive je open-source projekt Apache postavený na Hadoopu pro dotazování, sumarizaci a analýzu velkých datových sad pomocí rozhraní typu SQL. Apache Hive poskytuje jazyk podobný SQL s názvem HiveQL, který transparentně převádí dotazy na MapReduce pro provádění na velkých souborech dat uložených v distribuovaném systému souborů Hadoop (HDFS). Apache Hive je komponenta klastru Hadoop, kterou běžně používají analytici dat. Úl Apache se používá pro dávkové zpracování velkých úloh ETL. Apache Hive také podporuje dávkové dotazy SQL na velmi rozsáhlých datových sadách. Apache Hive zvyšuje flexibilitu návrhu schématu a také serializaci a deserializaci dat. Apache Hive nepodporuje online zpracování transakcí (OLTP), protože podregistr nepodporuje dotazy v reálném čase a na úrovni řádků.
Apache HBase je otevřená databáze NoSQL, která poskytuje přístup k velkým datovým souborům v reálném čase, ke čtení a zápisu. NoSQL je nerelační databáze. Apache HBase je distribuovaná databáze orientovaná na sloupce, která běží na Hadoop Distributed File System (HDFS). HBase přináší společnosti Hadoop výhody NoSQL. Apache HBase poskytuje možnosti náhodného přístupu k datům přítomným v HDFS. Využívá toleranci chyb poskytované HDFS. Uživatel může ukládat data v HDFS buď přímo, nebo prostřednictvím HBase.
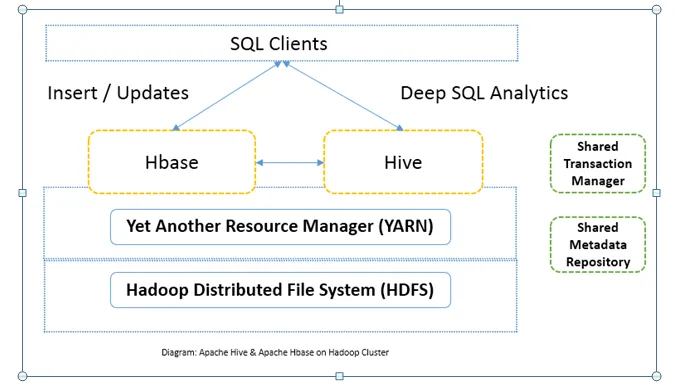
Srovnání hlava-hlava mezi Apache Hive vs Apache HBase (Infographics)
Níže je 12 nejlepších rozdílů mezi Apache Hive a Apache HBase

Klíčové rozdíly - Apache Hive vs. Apache HBase
Níže jsou uvedeny seznamy bodů, popište klíčové rozdíly mezi Apache Hive a Apache HBase:
- Apache HBase je databáze, zatímco Apache Hive je databázový stroj.
- Apache Hive se používá hlavně pro dávkové zpracování (OLAP), zatímco Apache HBase se používá hlavně pro transakční zpracování (OLTP).
- Apache Hive provádí většinu dotazů SQL, zatímco Apache HBase neumožňuje dotazy SQL přímo.
- Apache Hive nepodporuje operace na úrovni záznamu, jako je aktualizace, vkládání a mazání, zatímco Apache HBase podporuje operace na úrovni záznamu, jako je aktualizace, vkládání a mazání.
- Apache Hive běží na MapReduce, zatímco Apache HBase běží na Hadoop Distributed File System (HDFS).
Apache Hive zadává dotazy na soubory definováním virtuální tabulky a spuštěním dotazů HQL. Je to proces, ve kterém jsou soubory virtuálně připojeny k tabulce jako struktura a uživatel může provádět jazyk Hive Query Language (HQL) a tyto dotazy jsou převedeny na MapReduce Job by Hive. Uživatel nemusí psát úlohu MapReduce, dotazy HQL jsou interně převedeny na soubory jar a tyto soubory jar budou implementovány do datových sad.
V Apache HBase jsou tabulky rozděleny do regionů a jsou obsluhovány servery regionů. Další oblasti jsou vertikálně rozděleny podle sloupců do obchodů a obchody jsou ukládány jako soubory v HDFS.
Kdy použít Apache Hive:
- Požadavky na skladování dat
- Analytické dotazy
- Analýza dat, kteří jsou obeznámeni s SQL
Kdy použít Apache HBase:
- Rychlé a interaktivní zpracování dat
- Dotazy v reálném čase
- Rychlé vyhledávání
- Zpracování na straně serveru
- Náhodný přístup ke čtení a zápisu k velkým datům
- Škálovatelnost aplikace
Apache Hive lze použít k výpočtu trendů a protokolů webových stránek elektronického obchodu pro konkrétní dobu trvání, region nebo časové pásmo. Může být použit pro zpracování dávkového dotazu na historická data, zatímco Apache HBase může být používán Facebookem nebo LinkedIn pro zasílání zpráv a analýzu v reálném čase. Může být také použit pro počítání lajků.
Srovnávací tabulka Apache Hive vs. Apache HBase
Diskutuji o hlavních artefaktech a rozlišuji mezi Apache Hive a Apache HBase.
| Úl Apache | Apache HBase | |
| Zpracování dat | Apache Hive se používá
dávkové zpracování, tj. online analytické zpracování (OLAP) | Apache HBase se používá pro transakční zpracování, tj. Online transakční zpracování (OLTP) |
| Rychlost zpracování | Apache Hive má vyšší latenci kvůli provádění úlohy MapReduce na pozadí | Apache HBase pracuje na dotazování v reálném čase a je mnohem rychlejší než Apache Hive |
| Kompatibilita s Hadoop | Apache Hive běží na MapReduce | Apache HBase běží na vrcholu HDFS |
| Definice | Apache Hive je open source a podobný SQL používanému pro analytické dotazy | Apache HBase je open source databáze NoSQL používaná pro dotazování v reálném čase |
| Sdílená metadata | Data vytvořená v Apache Hive jsou pro Apache HBase automaticky viditelná | Data vytvořená v Apache HBase jsou automaticky viditelná pro Apache Hive |
| Schéma | Úl Apache podporuje schéma pro vkládání dat do tabulek | Apache HBase je databáze bez schématu. |
| Aktualizujte funkci | Funkce aktualizace je v Apache Hive komplikovaná | Uživatel může velmi snadno aktualizovat data v Apache HBase |
| Operace | Operace v Apache Hive neběží v reálném čase | Operace v Apache HBase probíhají v reálném čase |
| Typy dat | Apache Hive je určen pro strukturovaná a polostrukturovaná data | Apache HBase je pro nestrukturovaná data. |
| Úroveň konzistence | Úl Apache podporuje eventuální konzistenci | Apache HBase podporuje okamžitou konzistenci |
| Metody rozdělení | Apache Hive podporuje funkce Sharding | Apache HBase také podporuje funkce Sharding |
| Datové úložiště | Datum je uloženo v Hive Metastore, Partitions and Buckets v Apache Hive | Data jsou uložena ve sloupcích a řádcích tabulek v Apache HBase |
Závěr - Apache Hive vs. Apache HBase
Běžně se Apache Hive vs. Apache HBase používají společně ve stejném klastru. Oba mohou být použity společně pro zvýšení výkonu zpracování. Protože úl zlepšuje analytické stránky HDFS, zatímco HBase zlepšuje transakce v reálném čase. Uživatel může použít Hive jako nástroj ETL pro dávkové vkládání s daty do HBase a pak k provádění dotazů, které mohou dále spojovat data přítomná v tabulkách HBase s daty, která již jsou na HDFS. Data lze číst a zapisovat z Apache Hive do HBase a zpět. Rozhraní mezi Apache Hive a Apache HBase je stále zrání. Je toho ještě mnohem víc. Přesto mohu říci, že Apache Hive vs. Apache HBase dělá cluster Hadoop robustnějším a výkonnějším.
Související články:
Toto byl průvodce Apache Hive vs. Apache HBase, jejich význam, srovnání hlava-hlava, hlavní rozdíly, srovnávací tabulka a závěr. Další informace naleznete také v následujících článcích -
- Top 5 velkých datových trendů
- 5 Výzvy analýzy velkých dat
- Jak rozbít rozhovor s vývojářem Hadoop?
- 5 Výzvy analýzy velkých dat