

Úvod do datových vědních technik
V dnešním světě, kde jsou data novým zlatem, existují různé druhy analýz, které může podnik podniknout. Výsledek projektu datové vědy se velmi liší v závislosti na typu dostupných údajů, a proto je dopad také proměnný. Protože je k dispozici mnoho různých druhů analýz, je nezbytné pochopit, co je třeba vybrat z několika základních technik. Základním cílem technik datové vědy je nejen hledání relevantních informací, ale také odhalení slabých vazeb, které mají tendenci zhoršovat výkon modelu.
Co je to Data Science?
Datová věda je pole, které se šíří několika disciplínami. Zahrnuje vědecké metody, procesy, algoritmy a systémy pro shromažďování znalostí a práci na nich. Toto pole zahrnuje řadu žánrů a je společnou platformou pro sjednocení pojmů statistika, analýza dat a strojové učení. Teoretické znalosti statistik spolu s daty a technikami v reálném čase v strojovém učení pracují ruku v ruce s cílem dosáhnout plodných výsledků pro podnikání. Pomocí různých technik používaných ve vědě o datech můžeme v dnešním světě naznačit lepší rozhodování, které by jinak mohlo lidskému zraku a mysli uniknout. Pamatujte, že stroj nikdy nezapomíná! K maximalizaci zisku ve světě řízeném údaji je nezbytným nástrojem magie Data Science.
Různé typy datové techniky
V následujících několika odstavcích bychom se podívali na běžné techniky vědy o údajích používané v každém dalším projektu. Ačkoli někdy může být technika datových věd specifická pro obchodní problém a nemusí spadat do níže uvedených kategorií, je naprosto v pořádku je označovat jako různé typy. Na vysoké úrovni rozdělujeme techniky na supervizovaný (víme, jaký je cílový dopad) a nedohledněný (nevíme, o cílové proměnné, kterou se snažíme dosáhnout). V další úrovni lze techniky rozdělit na
- Výstup, který bychom dostali nebo jaký je záměr obchodního problému
- Druh použitých údajů.
Podívejme se nejprve na segregaci založenou na záměru.
1. Výuka bez dozoru
- Detekce anomálií
V tomto typu techniky identifikujeme jakýkoli neočekávaný výskyt v celé sadě dat. Protože se chování liší od skutečného výskytu dat, vychází se z těchto předpokladů:
- Výskyt těchto případů je velmi malý.
- Rozdíl v chování je významný.
Jsou vysvětleny algoritmy anomálií, jako je například izolační les, který poskytuje skóre pro každý záznam v datové sadě. Tento algoritmus je stromový model. Pomocí tohoto typu detekční techniky a její popularity se používají v různých obchodních případech, například v zobrazení webových stránek, sazebníku, výnosech za kliknutí atd. V níže uvedeném grafu můžeme vysvětlit, jak vypadá anomálie.
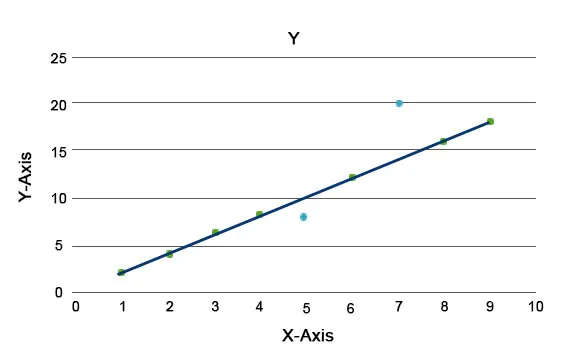
Tady modré představují anomálii v datovém souboru. Liší se od běžné trendové linie a vyskytují se méně.
- Shluková analýza
Hlavním úkolem této analýzy je rozdělit celý soubor dat do skupin tak, aby trend nebo vlastnosti v jedné skupině datových bodů byly navzájem velmi podobné. V terminologii datové vědy je nazýváme shlukem. Například v maloobchodě je plán na rozšíření rozsahu podnikání a je nezbytné vědět, jak by se noví zákazníci chovali v novém regionu na základě minulých údajů, které máme. Je nemožné vymyslet strategii pro každého jednotlivce v populaci, ale bude užitečné seskupit populaci do shluků tak, aby strategie byla efektivní ve skupině a byla škálovatelná.
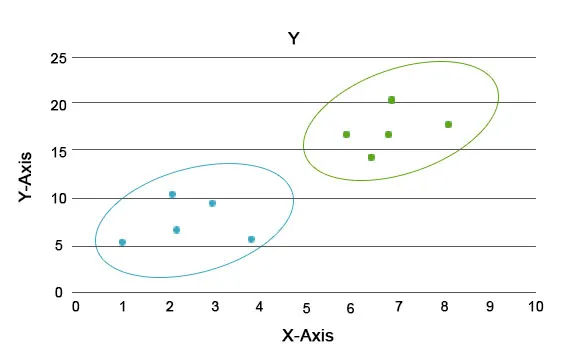
Modré a oranžové barvy jsou zde různé klastry, které mají v sobě jedinečné vlastnosti.
- Analýza asociace
Tato analýza nám pomáhá při vytváření zajímavých vztahů mezi položkami v datovém souboru. Tato analýza odhaluje skryté vztahy a pomáhá při zobrazování položek datové sady ve formě asociačních pravidel nebo sad častých položek. Pravidlo přidružení je rozděleno do dvou kroků:
- Generování častých položek : V tomto je generována sada, ve které jsou často se vyskytující položky nastaveny společně.
- Generování pravidel: Sestava vytvořená výše prochází různými vrstvami tvorby pravidel, aby se mezi nimi vytvořil skrytý vztah. Sada může například spadat do koncepčních nebo implementačních problémů nebo do aplikačních problémů. Ty jsou poté rozčleněny do příslušných stromů, aby se vytvořila pravidla přidružení.
Například APRIORI je algoritmus vytváření asociačních pravidel.
2. Dozorované učení
- Regresní analýza
V regresní analýze definujeme závislou / cílovou proměnnou a zbývající proměnné jako nezávislé proměnné a nakonec předpokládáme, jak jedna / více nezávislých proměnných ovlivňuje cílovou proměnnou. Regrese s jednou nezávislou proměnnou se nazývá univariate a s více než jednou se nazývá multivariate. Pojďme pochopit používání univariate a pak měřítko pro multivariate.
Například y je cílová proměnná a x 1 je nezávislá proměnná. Takže ze znalosti přímky můžeme rovnici napsat jako y = mx 1 + c. Zde „m“ určuje, jak silně je y ovlivněno x 1 . Pokud je „m“ velmi blízko nule, znamená to, že se změnou v x 1 není y silně ovlivněno. S číslem větším než 1 se dopad zesiluje a malá změna v x 1 vede k velké odchylce v y. Podobně jako univariate, v multivariate lze psát jako y = m 1 x 1 + m 2 x 2 + m 3 x 3 ………., Zde je dopad každé nezávislé proměnné určen jeho odpovídajícím „m“.
- Klasifikační analýza
Podobně jako shluková analýza, jsou vytvářeny klasifikační algoritmy s cílovou proměnnou ve formě tříd. Rozdíl mezi klastrováním a klasifikací spočívá v tom, že v klastrování nevíme, do které skupiny spadají datové body, zatímco v klasifikaci víme, do které skupiny patří. A liší se od regrese z pohledu, že počet skupin by měl být stálý počet na rozdíl od regrese, je spojitý. Existuje řada algoritmů v klasifikační analýze, například Support Vector Machines, Logistic Regression, Decision Trees atd.
Závěr
Na závěr si uvědomujeme, že každý typ analýzy je sám o sobě obrovský, ale zde můžeme poskytnout malou příchuť různým technikám. V následujících několika poznámkách bychom každou z nich brali zvlášť a podrobně rozebírali různé subtechniky použité v každé mateřské technice.
Doporučený článek
Toto je průvodce metodami Data Science Techniques. Zde diskutujeme úvod a různé typy technik ve vědě o datech. Další informace naleznete také v dalších navrhovaných článcích -
- Nástroje pro vědu o údajích | 12 nejlepších nástrojů
- Algoritmy vědecké práce s daty
- Úvod do datové kariéry
- Data Science vs Vizualizace dat
- Příklady multivariační regrese
- Vytvořte rozhodovací strom s výhodami
- Stručný přehled životního cyklu dat