

Úvod do Python Regex
Python je dnes v technickém průmyslu bzučivým slovem. Je to jazyk, který získává popularitu rychlým tempem. Je to velmi dynamický jazyk a lze jej použít k vytváření webových aplikací pro algoritmy strojového učení. V tomto článku se dozvíme, jak se Regex používá v Pythonu. Regex je krátká forma regulárního výrazu a je to v podstatě posloupnost znaků, které lze použít jako vzor. Dobrá věc je, že Python má svůj vlastní vestavěný balíček Regex známý jako re.
Syntax:
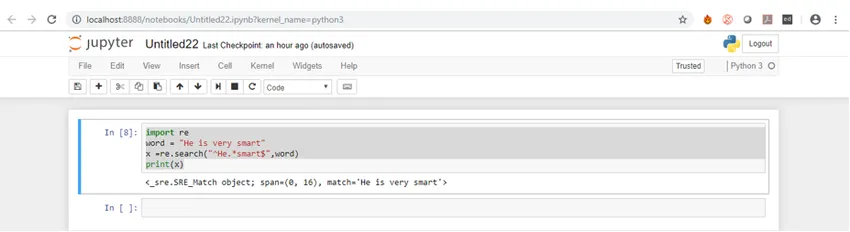
Budeme rozumět Syntaxi s příkladem. Příkladem toho můžeme hledat řetězec, abychom zjistili, zda začíná řetězcem „He“ a končí „smart“.
import reword = "He is very smart"
x =re.search("^He.*smart$", word)
print(x)
Pokud se podíváte na syntaxi, je to velmi jednoduché, musíte nejprve importovat balíček regex, který je re a pak použít libovolnou z funkcí importovaného balíčku podle vašeho požadavku. Pokud spustíme výše uvedený ukázkový kód v Jupyteru, dostaneme níže uvedený výsledek.
Regexové funkce v Pythonu
Existuje mnoho funkcí regexu, které nám pomáhají hledat řetězec pro shodu. Předtím se nejprve seznámíme s postavami, které obvykle vidíme ve funkci regex.
|
() | Představuje sadu znaků. |
|
. | Představuje libovolný znak kromě nového řádku. |
|
* | Představuje nulové nebo více výskytů. |
|
+ | Představuje jeden nebo více výskytů. |
|
^ | Představuje počáteční znak |
|
$ | Představuje koncový znak. |
|
| |
Představuje buď - nebo. |
|
() |
Představuje zachycení a skupinu. |
| \ |
Obvykle se používá k úniku ze speciálních znaků |
Regex má také několik speciálních sekvencí, které bude užitečné znát například:
|
\ w | Zobrazuje shodu, pokud řetězec obsahuje libovolnou sadu slovních znaků od (0-9), AZ nebo az a podtržítko. |
|
\ W | Vrací shodu, pokud řetězec neobsahuje žádné znaky slova. |
|
\ d | Tyto výnosy se shodují, pokud jsou v řetězci číslice. |
|
\ D | Je opakem předchozího, protože vrací shodu, pokud v řetězci nejsou žádné číslice. |
|
\ s | Používá se ke kontrole znaků mezery v řetězci. Vrací shodu, pokud jsou k dispozici znaky mezery. |
|
\ S | Vrací shodu, pokud v řetězci nejsou žádné mezery. |
Funkce používané pro operace Regex
Podívejme se na různé funkce re modulu, které lze použít pro regexové operace v pythonu.
1. findall () funkce: Tato funkce je přítomna v modulu re. Vrací seznam všech shod přítomných v řetězci. Iteruje zleva doprava přes řetězec. Zápasy jsou také vráceny ve stejném pořadí vyhledávání. Projdeme příkladem. Předpokládejme, že chceme najít všechny číslice přítomné v řetězci. K tomu použijeme funkci findall (), ve které najdeme všechny číslice přítomné v řetězci. Podívejme se na to kód nyní:
Kód:
import re
word = "Raju is 22 years old and his mobile number last three-digit is 789"
rgex ='\d+'
x =re.findall(rgex, word)
print(x)
Pokud projdeme kód, máme v zásadě přiřazeno proměnné slovo řetězcem obsahujícím číslice a poté předáme příslušný regexový symbol pro číslice spolu s proměnným slovem jako argumenty ve funkci findall ().
Nyní se podívejme na výstup.
Jak vidíte, výsledkem je seznam čísel.
2. funkce search (): Funkce search se používá k prohledávání vzorců v řetězci a pokud je nalezena shoda, vrací objekt. Zde si musíme pamatovat, že pokud existuje více než jedna shoda, vrací pouze první výskyt. Pokud není nalezena žádná shoda, nevrací žádnou. Uvidíme příklad tohoto předpokladu, pokud chceme najít řetězec, který začíná určitým slovem. Budeme testovat pozitivní i negativní případy shody. Podívejme se na stejný kód.
Kód:
import re
word = "Raju is 22 years old"
rgex ='^Raju'
x =re.search(rgex, word)
print(x)
regex1= '^Mohan'
x1 = re.search(regex1, word)
print(x1)
Zde se proměnná „regex“ používá v pozitivním scénáři a proměnná „regex1“ pro negativní scénář. Nyní se podívejte na výstup.
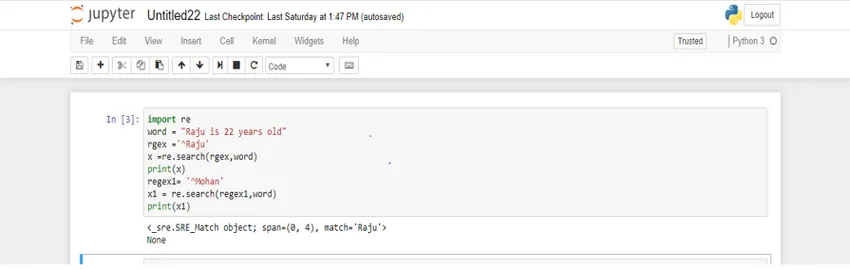
V prvním případě dostaneme vrácený objekt zápasu, zatímco v druhém případě dostaneme 'Žádný'.
3. Funkce Split (): Tato funkce rozdělí řetězec po každé shodě, což znamená, že jakmile je v řetězci shoda, tato funkce odtud rozdělí řetězec. Pokud tedy existují tři zápasy, budou tři rozkoly. Uvidíme příklad. Předpokládejme, že chceme rozdělit řetězec po každém prostoru. Můžeme tedy tuto funkci rozdělení použít v této situaci k dobrému použití.
Kód:
import re
word = "Raju is 22 years old"
rgex ='\s'
x =re.split(rgex, word)
print(x)
Zde vzory představují znak mezery. Nyní se podívejme na výstup.
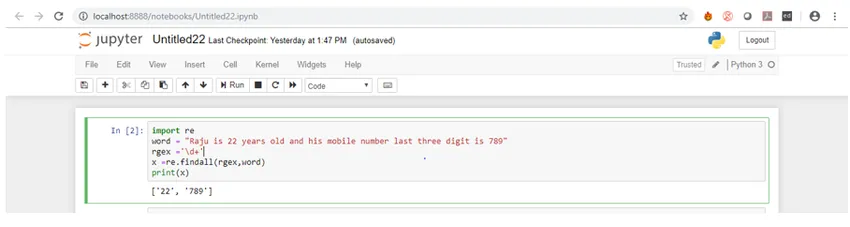
Jak můžete vidět ve výstupu, řetězec se po každém mezeru rozdělí.
4. Funkce sub (): Tato funkce nahrazuje shody řetězcem nebo znakem podle volby uživatele. V podstatě to znamená, že pokud existuje řetězec, nahradí tento odpovídající znak nebo řetězec řetězcem nebo znakem a vrátí upravený řetězec. Vyžaduje to tři argumenty. Například v našem řetězci nahradíme pouze mezeru znakem „&“.
Kód:
import re
word = "Raju is 22 years old"
rgex ='\s'
x =re.sub(rgex, '&', word)
print(x)
Nyní se podívejme na výstup výše uvedeného kódu.
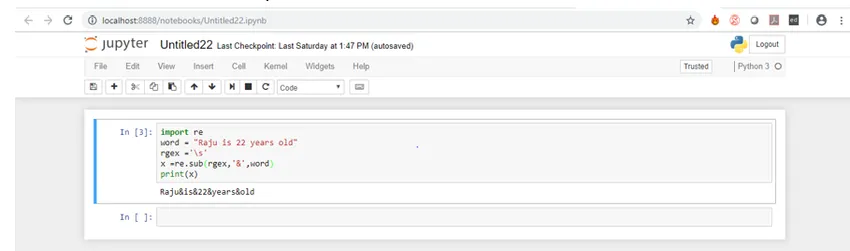
Jak vidíte, všechny prostory byly nahrazeny znakem „&“.
Závěr
V tomto článku jsme diskutovali modul regex a jeho různé vestavěné funkce Pythonu. Regex je velmi důležitý a je široce používán v různých programovacích jazycích.
Doporučené články
Toto je průvodce Python Regex. Zde diskutujeme Úvod do Python Regex a některé důležité regex funkce spolu s příkladem. Další informace naleznete také v dalších navrhovaných článcích -
- Zatímco smyčka v Pythonu
- Reverzní číslo v Pythonu
- Python Klíčová slova
- Pythonovy sady
- Klíčová slova PHP
- Klíčová slova C ++