Úl je zařízení pro skladování dat poskytované společností Apache. Hive je postaven na vrcholu distribuovaného systému souborů Hadoop (HDFS) pro psaní, čtení, dotazování a správu velkých strukturovaných nebo polostrukturovaných dat v distribuovaných úložných systémech, jako je HDFS. Každá HiveQL bude převedena na úlohu MapReduce v backendu. Hive poskytuje Hive Query Language (HiveQL), který je jako normální SQL v RDBMS. Stejně jako SQL i HiveQL poskytuje klauzuli ORDER BY, kterou lze použít s klauzulí SELECT. Funkce OBJEDNÁVKA BY se používá k třídění dat ve vzestupném nebo sestupném pořadí podle sloupců určených uživatelem.
Syntaxe v pořadí podregistrů podle
Níže je uvedena syntaxe v pořadí podregistrů podle:
Základní syntaxe:
SELECT, FROM ORDER BY ;
SELECT, FROM ORDER BY ;
Klauzula OBJEDNÁVKA spolu se všemi ostatními doložkami:
SELECT DISTINCT, , FROM WHERE GROUP BY HAVING ORDER BY LIMIT ;
SELECT DISTINCT, , FROM WHERE GROUP BY HAVING ORDER BY LIMIT ;
Můžete také zadat OBJEDNÁVKU 1 nebo OBJEDNÁVKU 2, kde 1 a 2 představují číslo sloupce namísto použití OBJEDNÁVKU BY. OBJEDNÁVKU BY lze použít pouze v případě, že jsou názvy sloupců uvedeny v klauzuli SELECT a nikoli s klauzulí SELECT *.
Jak můžeme použít funkci ORDER BY v Úlu?
Níže je vysvětleno, jak můžeme použít pořadí podle funkce v úlu:
1. OBJEDNAT vzestupně a sestupně
Ve výchozím nastavení bude pořadí řazení vzestupné, což ukazuje nejmenší hodnotu na začátku a největší hodnotu na konci výsledku, i když ji nezadáte explicitně.
Můžete také zadat OBJEDNÁVKU ASC pro vzestupné pořadí a OBJEDNAT PODLE POP pro třídění výsledků v sestupném pořadí nebo v zadaném sloupci.
Syntaxe HiveQL pro vzestupné pořadí ODER BY lze zobrazit níže:
SELECT, FROM ORDER BY ASC;
SELECT, FROM ORDER BY ASC;
Syntaxe HiveQL pro sestupné pořadí ODER BY lze znázornit takto:
SELECT, FROM ORDER BY DESC;
SELECT, FROM ORDER BY DESC;
Klauzule vzestupně a sestupně lze použít současně s více sloupci v klauzuli ORDER BY, jak je ukázáno níže:
SELECT, FROM ORDER BY ASC DESC;
SELECT, FROM ORDER BY ASC DESC;
2. OBJEDNÁVKA A NULL Hodnoty
Nejnovější verze podregistru také podporují řazení podle hodnoty NULL.
Ve výchozím nastavení je pořadí řazení NULL hodnot pro OBJEDNÁVAT ASC NULLS FIRST. Seřadí všechny hodnoty NULL na začátek tříděného výsledku.
Podobně je pořadí řazení hodnot NULL pro OBJEDNAT POPIS ve výchozím nastavení NULLS LAST. Seřadí všechny hodnoty NULL na konec tříděného výsledku.
Můžete také zadat NULLS FIRST a NULLS LAST spolu s ORDER BY ASC nebo ORDER BY DESC podle vašich požadavků a pohodlí.
Syntaxe NULLS FIRST klauzule spolu s ORDER BY vzestupně:
SELECT, FROM ORDER BY ASC NULLS LAST;
SELECT, FROM ORDER BY ASC NULLS LAST;
Syntaxe klauzule NULLS LAST spolu s klesáním ORDER BY:
SELECT, FROM ORDER BY DESC NULLS FIRST;
SELECT, FROM ORDER BY DESC NULLS FIRST;
3. Doložka OBJEDNÁVKA A OMEZENÍ
Klauzula LIMIT je u klauzule ORDER BY volitelná.
Klauzuli LIMIT lze použít ke zlepšení výkonu. Klauzuli LIMIT lze použít, aby se zabránilo zbytečnému zpracování dat.
Klauzule LIMIT vybere z výsledku pro účely ověření pouze omezený počet hodnot.
Klauzuli LIMIT s klauzulí ORDER By lze zobrazit níže:
SELECT, FROM ORDER BY ASC LIMIT 10;
SELECT, FROM ORDER BY ASC LIMIT 10;
Klauzuli ORDER BY lze také kombinovat s klauzulí OFFSET a LIMIT pro snížení množství výsledku. Syntaxe téhož lze zobrazit jako:
SELECT, FROM ORDER BY ASC LIMIT 10 OFFSET 10;
SELECT, FROM ORDER BY ASC LIMIT 10 OFFSET 10;
Příklady v pořadí podregistrů podle
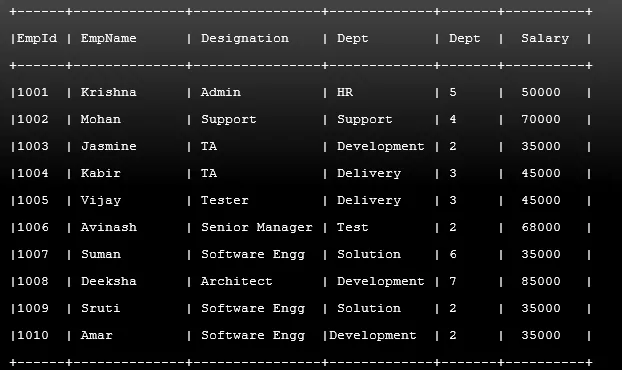
Zvažte následující ukázkovou tabulku Zaměstnanec, který obsahuje ID zaměstnance jako EmpID, jméno zaměstnance jako EmpName, označení, oddělení jako oddělení, úroveň úlohy jako JL a plat.
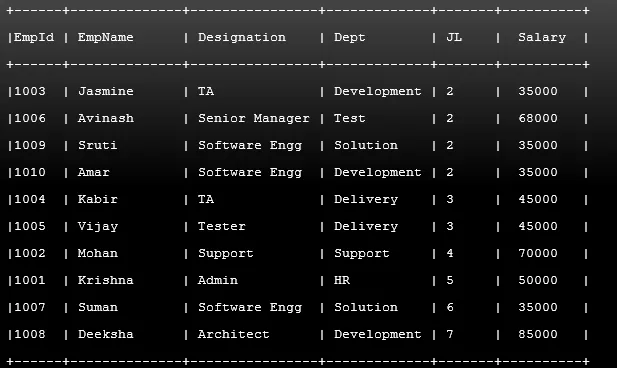
Příklad č. 1
Kód:
SELECT * FROM Employee ORDER BY JL ASC;
Výstup:
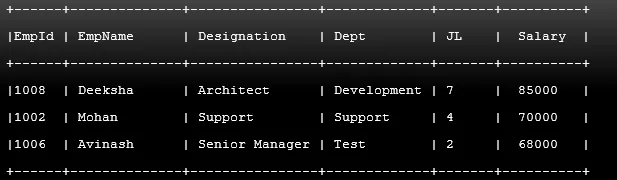
Příklad č. 2
Kód:
SELECT * FROM Employee ORDER BY Salary DESC LIMIT 3;
Výstup:
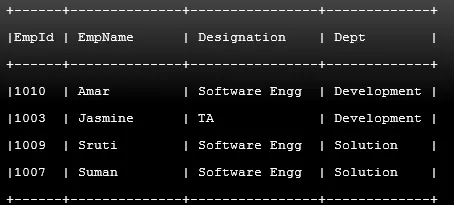
Příklad č. 3
Kód:
SELECT EmpId, EmpName, Designation, Dept FROM Employee where Salary < 50000 ORDER BY EmpName ASC JL ASC;
Výstup:
Závěr
ORDER BY in Hive vám umožní třídit data vzestupně nebo sestupně. OBJEDNÁVKU BY lze kombinovat s dalšími doložkami k získání seřazených dat. OBJEDNÁVKA BY se liší od SORT BY jako SORT BY třídí data v reduktoru, ale ORDER BY třídí všechna data.
Doporučené články
Toto je průvodce Hive Order By. Zde diskutujeme o tom, jak můžeme v pořádku použít funkci podle úlu a různé příklady s kódy a výstupy. Další informace naleznete také v dalších souvisejících článcích -