

Úvod do odlišného klíčového slova v SQL
Než začneme, pojďme se krátce seznámit. SQL je zkratka pro jazyk Structured Query. Je to velmi široce používaný jazyk dotazu databáze. Používá se při získávání, správě a úpravě dat pro relační databáze (jedná se o databáze, v nichž jsou data uložena v tabulkách). Protože jsou data ukládána ve strukturované podobě, název jazyka je SQL. Nyní pojďme k odlišnému klíčovému slovu. Když řekneme nebo uslyšíme anglické slovo zřetelně, první věc, která nám přijde na mysl, je jedinečná nebo oddělená od ostatních. Toto klíčové slovo používáme k odstranění duplicitních záznamů.
Syntaxe s vysvětlením
Podívejme se na samostatnou syntaxi klíčových slov s příkladem:
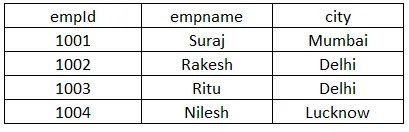
Pojďme mít tabulku zaměstnanců se třemi sloupci: empId, empname a city, jak je uvedeno níže:
Select DISTINCT(column_name) from table_name;
V našem příkladu výše vidíme, že město je sloupec, který má opakující se hodnoty, takže místo jména název_tabulky umístíme město a zaměstnance. Při spuštění vrátí jedinečné názvy měst, kterými jsou Bombaj, Dillí, Lucknow. Pokud odstraníme odlišné klíčové slovo, načte namísto tří čtyři hodnoty.
Parametry použité pro výrazné klíčové slovo v SQL
Podívejme se nyní na různé parametry přítomné v samostatném klíčovém slově. Níže je uvedena syntaxe pro odlišné klíčové slovo.
Syntax:
Select DISTINCT(expressions) from tables (where conditions);
- Výrazy: V této části uvedeme požadované sloupce nebo výpočty.
- Tabulky: Poskytujeme názvy tabulek, z nichž chceme záznamy. Jedna věc k poznámce je, že by měl existovat alespoň jeden název tabulky po klauzuli.
- Kde Podmínky: Toto je čistě volitelné, poskytujeme podmínky, kdy chceme, aby data nejprve splňovala konkrétní podmínku pro výběr záznamů.
Jak používat výrazné klíčové slovo v SQL?
Jak jsme již diskutovali o parametrech. Nyní se pomocí příkladů naučíme, kde používat odlišné klíčové slovo.
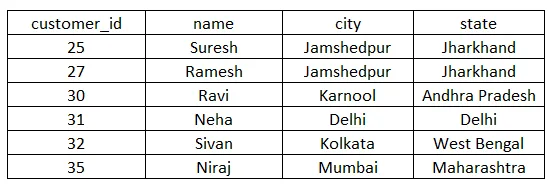
Vytvořme tabulku ZÁKAZNÍK pomocí příkazů DDL (jazyk pro definici dat) a pak je naplníme pomocí DML (jazyk pro manipulaci s daty).
DDL (vytvoření tabulky):
CREATE TABLE customer ( customer_id int NOT NULL, name char(50) NOT NULL, city varchar2, state varchar2);
Tím vytvoříte tabulku se čtyřmi sloupci customer_id, name, city a state. Nyní použijeme příkazy DML k zadávání dat do tabulky.
Vložte příkazy pro zadání dat:
INSERT INTO customer (customer_id, name, city, state) VALUES (25, 'Suresh', 'Jamshedpur', 'Jharkhand');
INSERT INTO customer (customer_id, name, city, state) VALUES (27, 'Ramesh', 'Jamshedpur', 'Jharkhand');
INSERT INTO customer (customer_id, name, city, state) VALUES (30, 'Ravi', 'Karnool', 'Andhra Pradesh');
INSERT INTO customer (customer_id, name, city, state) VALUES (31, 'Neha', 'Delhi', 'Delhi');
INSERT INTO customer (customer_id, name, city, state) VALUES (32, 'Sivan', 'Kolkata', 'West Bengal');
INSERT INTO customer (customer_id, name, city, state) VALUES (35, 'Niraj', 'Mumbai', 'Maharashtra');
Po provedení výše uvedených prohlášení získáme níže uvedenou tabulku zákazníků.
Nyní provedeme některé dotazy pomocí odlišných dotazů, abychom zjistili, jak používat odlišné klíčové slovo.
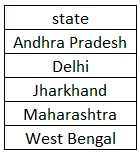
1. Nejprve najdeme ve sloupci jedinečné hodnoty.
Dotaz:
select DISTINCT state from customer order by state;
Při provádění dotazu získáme 5 hodnot, protože máme pouze pět různých stavů, protože Jharkhand se opakuje dvakrát. Protože jsme použili OBJEDNÁVKU BY, tak bude sada výsledků seřazena vzestupně. Níže je sada výsledků, které bychom měli dostat na provedení dotazu.
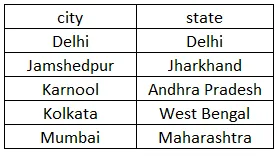
2. Za druhé, budeme jedinečné hodnoty z více sloupců.
Dotaz:
select DISTINCT city, state from customer order by city, state;
Výše uvedený dotaz vrátí jednotlivé kombinace měst a států. Ve výše uvedeném případě se rozdílné vztahuje na každé pole, které je zapsáno za odlišným klíčovým slovem. Budeme tedy mít pět párů města a státu, protože město Jamshedpur bylo dvakrát opakováno. Takže budeme mít Jamshedpur spolu s Jharkhandem jednou. Město bude seřazeno vzestupně. Výsledek nastavený na provedení dotazu je uveden níže.
3. Nyní uvidíme, jak odlišné klíčové slovo zpracovává nulové hodnoty.
Nejprve aktualizujeme pole ve sloupci stavu jako NULL a poté použijeme odlišné klíčové slovo k získání sady výsledků.
Aktualizační dotaz pro nastavení hodnoty NULL v jednom z polí tabulky zákazníků.
Dotaz:
update customer set state=”” where customer_id = 35;
Vloží hodnotu NULL do posledního pole ve sloupci stavu. Tabulka bude aktualizována níže.
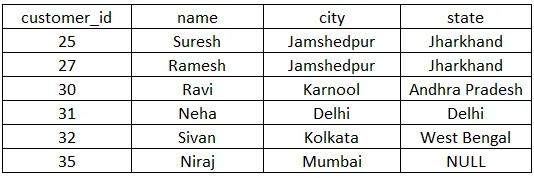
Nyní provedeme odlišné klíčové slovo pomocí výběrového dotazu.
Dotaz:
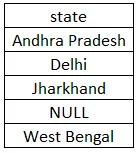
select DISTINCT state from customer order by state;
Při provádění výše uvedeného dotazu nastavíme ve výsledku pět hodnot, protože odlišné klíčové slovo považuje NULL také za jedinečnou hodnotu. Jharkhand opakující se dvakrát bude mít ve výsledkové sadě pouze jednu hodnotu. Protože jsme použili klauzuli ORDER BY, bude sada výsledků seřazena vzestupně. Níže je sada výsledků, které bychom měli vidět při provádění výše uvedeného dotazu.
Závěr
Na závěr tohoto článku můžeme říci, že odlišné klíčové slovo je velmi výkonné a užitečné klíčové slovo, které se používá v příkazech SELECT na základě různých podmínek v závislosti na obchodních požadavcích k načtení hodnot UNIQUE / DISTINCT ze sloupce nebo sloupců.
Doporučené články
Toto je průvodce rozlišujícím klíčovým slovem v SQL. Zde diskutujeme úvod, jak používat odlišné klíčové slovo v SQL? A jeho parametr spolu s některými příklady. Další informace naleznete také v následujících článcích -
- Zobrazení SQL
- Cizí klíč v SQL
- Transakce v SQL
- Zástupný znak v SQL
- toto klíčové slovo v Javě | Důležitost, příklady tohoto klíčového slova