
Rozdíl mezi BFS VS DFS
Breadth-First Search (BFS) a Depth First Search (DFS) jsou dva důležité algoritmy používané pro vyhledávání. Hledání šířky - první začíná své vyhledávání od prvního uzlu a poté se pohybuje po úrovních, které jsou blíže kořenovému uzlu, zatímco algoritmus hloubkového prvního vyhledávání začíná prvním uzlem a poté dokončuje svou cestu ke koncovému uzlu příslušné cesty. Oba algoritmy procházejí během hledání každým uzlem. Pro tyto dva algoritmy se zapisují různé kódy pro provedení procesu procházení. Oni jsou také považováni za důležité vyhledávací algoritmy v umělé inteligenci.
V tomto tématu se budeme učit o BFS VS DFS.
Jak fungují BFS a DFS?
Pracovní mechanismus obou algoritmů je vysvětlen níže s příklady. Prosím, podívejte se na ně pro lepší pochopení použitého přístupu.
Příklad vyhledávání podle šířky
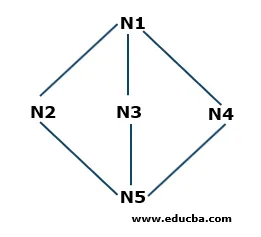
- Krok 1: N1 je kořenový uzel, takže začne odtud. N1 je spojen se třemi uzly N2, N3 a N4. Všechny tři uzly dosud nebyly navštíveny. Začneme tedy od N2 a uložíme do fronty. Fronta Q tedy obsahuje pouze N2.
Q: N2
- Krok 2: Dalším uzlem, který je připojen k N1, je N3. Protože jsme přešli nebo navštívili uzel, uložíme jej do fronty. Aktualizovaná fronta je tedy
Q: N3, N2
- Krok 3: Dalším uzlem, který je připojen k kořenovému uzlu, je N4. Uložíme ji do fronty.
Q: N4, N3, N2
- Krok 4: Všechny uzly připojené k N1 jsou uloženy ve frontě. Nyní odstraníme N2 z fronty podle principu First in First Out (FIFO) a najdeme uzly, které jsou připojeny k N2, tj. N5. N5 není jednou navštíven, takže jej uložíme do fronty.
Q: N5, N4, N3
- Krok 5: Všechny vrcholy jsou navštíveny, takže stále odstraňujeme uzly z fronty, dokud nejsou prázdné.
Příklad hloubky prvního vyhledávání
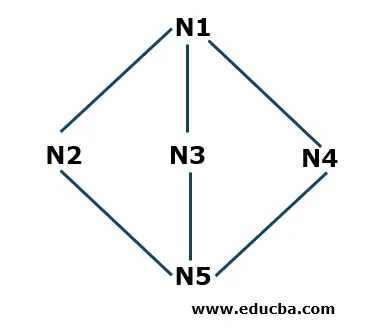
- Krok 1: Začneme N1 jako počátečním uzlem a uložíme jej do zásobníku S. N1 je spojen se třemi sousedními uzly N2, N3 a N4. Počínaje N2 (můžete začít abecedně nebo číselně), vložíme to do zásobníku.
S: N2 (nahoře), N1
- Krok 2: Nyní jsou sousedními uzly N2 N1 a N5. Protože N1 je již v zásobníku, což znamená, že je navštíven, vezmeme N5 a vložíme do zásobníku S.
S: N5 (nahoře), N2, N1
- Krok 3: Nyní jsou sousedními uzly N5 N3 a N4. Začneme N3 a vložíme do zásobníku.
S: N3 (nahoře), N5, N2, N1
Nyní je N3 připojen k N5 a N1, které jsou již v zásobníku, což znamená, že jsou navštíveny, takže odstraníme N3 ze zásobníku podle principu Last in First Out (LIFO).
S: N5 (nahoře), N2, N1
- Krok 4: Nyní vložíme poslední uzel, který jsme nenarazili na celé procházení v N4, a vložíme jej do zásobníku.
S: N4 (nahoře), N5, N2, N1
- Krok 5: Nyní nejsme vynecháni s žádnými jinými uzly, takže v zásobníku zkontrolujeme, zda jsou v uzlech připojeny nějaké uzly, které nejsou navštíveny. Pokud jsou navštíveny všechny připojené uzly, odstraníme uzly přítomné v zásobníku. Například N4 nemá žádné spojovací uzly, které jsme nekontrolovali, takže jej odstraníme ze zásobníku. Podobně můžeme zkontrolovat další uzly. Algoritmus se zastaví, jakmile je zásobník prázdný.
Srovnání hlava-hlava mezi BFS VS DFS (infografika)
Níže je uvedeno prvních 6 rozdílů mezi BFS VS DFS
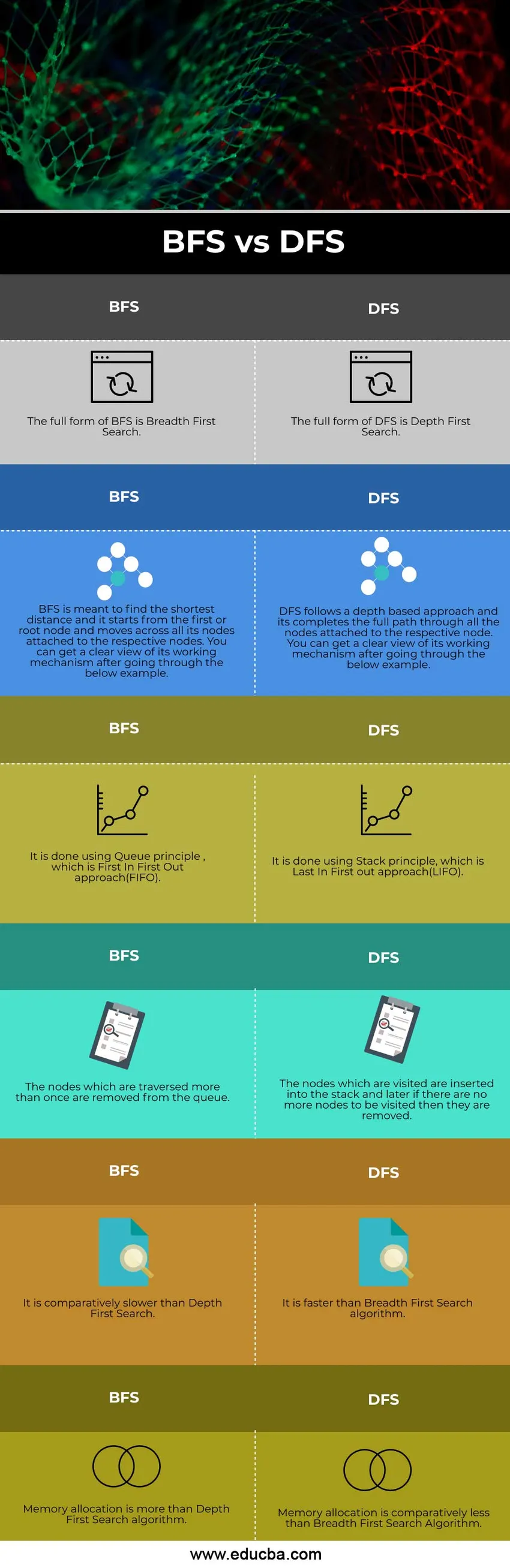
Klíčové rozdíly mezi BFS a DFS
Pojďme diskutovat o některých hlavních klíčových rozdílech mezi BFS a DFS
- Hledání podle šířky (BFS) začíná od kořenového uzlu a navštěvuje všechny příslušné uzly připojené k němu, zatímco DFS začíná od kořenového uzlu a dokončí úplnou cestu připojenou k uzlu.
- BFS postupuje podle fronty, zatímco DFS sleduje přístup k stacku.
- Přístup používaný v BFS je optimální, zatímco proces používaný v DFS není optimální.
- Pokud je naším cílem najít nejkratší cestu, než BFS je před DFS preferována.
Srovnávací tabulka BFS a DFS
Pojďme diskutovat o nejlepším srovnání mezi BFS a DFS
| BFS | DFS |
| Úplnou formou BFS je první vyhledávání podle šířky. | Úplnou formou DFS je hloubkové první vyhledávání |
| Účelem BFS je najít nejkratší vzdálenost a začíná od prvního nebo kořenového uzlu a pohybuje se všemi uzly připojenými k příslušným uzlům. Po prostudování níže uvedeného příkladu získáte jasný pohled na jeho pracovní mechanismus. | DFS postupuje na základě hloubky a dokončí úplnou cestu všemi uzly připojenými k příslušnému uzlu. Po prostudování níže uvedeného příkladu získáte jasný pohled na jeho pracovní mechanismus. |
| Provádí se to pomocí principu Queue, což je přístup FIFO (First In First Out). | To se provádí pomocí principu Stack, což je přístup Last In First out (LIFO). |
| Uzly, které procházejí vícekrát, se z fronty odstraní. | Navštívené uzly jsou vloženy do zásobníku a později, pokud již nejsou k dispozici žádné další uzly, budou odstraněny. |
| Je poměrně pomalejší než hloubkové první vyhledávání. | Je rychlejší než algoritmus Breadth-First Search. |
| Přidělení paměti je více než algoritmus hloubky prvního vyhledávání. | Přidělení paměti je poměrně menší než algoritmus vyhledávání podle šířky |
Závěr
Existuje mnoho aplikací, kde se výše uvedené algoritmy používají jako strojové učení nebo k nalezení řešení souvisejících s umělou inteligencí atd. Používají se hlavně v grafech ke zjištění, zda je to bipartit nebo ne, k detekci cyklů nebo součástí, které jsou spojeny. Jsou také považovány za důležité algoritmy při hledání cesty nebo nalezení nejkratší vzdálenosti. V závislosti na požadavcích podnikání můžeme použít dva algoritmy. Breadth-First Search je však považován spíše za optimální způsob než algoritmus hloubky prvního vyhledávání.
Doporučené články
Toto je průvodce BFS VS DFS. Zde diskutujeme hlavní rozdíly BFS VS DFS s infografikou a srovnávací tabulkou. Další informace naleznete také v následujících článcích -
- Algoritmus BFS
- TeraData vs Oracle
- Big Data vs Data Warehouse
- Big Data vs Apache Hadoop: Nejlepší 4 srovnání, které se musíte naučit