

Splunk Interview Otázky a odpovědi - úvod
Takže jste konečně našli svoji vysněnou práci ve Splunk, ale přemýšlíte, jak rozbít Splunk Interview a jaké by mohly být pravděpodobné Splunk Interview Otázky pro rok 2018. Každý rozhovor je jiný a také rozsah práce je jiný. S ohledem na tuto skutečnost jsme pro rok 2018 navrhli nejběžnější otázky a odpovědi ve službě Splunk Interview, které vám pomohou dosáhnout úspěchu v rozhovoru.Níže jsou uvedeny nejdůležitější nejužitečnější otázky a odpovědi ve službě Splunk Interview. Tyto hlavní otázky jsou rozděleny do dvou částí:
Část 1 - Splunk rozhovory (základní)
Tato první část se zabývá základními otázkami a odpověďmi na otázky Rozhovor.
1. Co je to Splunk? Proč se Splunk používá pro analýzu strojních dat?
Odpovědět:
Jedním z nejpoužívanějších analytických nástrojů je Microsoft Excel a jeho nevýhodou je, že Excel dokáže načíst pouze 1048576 řádků a strojová data jsou obecně obrovská. Splunk se hodí při práci se strojově generovanými daty (velkými daty), data ze serverů, zařízení nebo sítí lze snadno načíst do Splunk a lze je analyzovat, aby se zkontrolovala jakákoli viditelnost hrozeb, dodržování předpisů, zabezpečení atd. Lze ji také použít pro monitorování aplikací.
2.Vysvětlete, jak Splunk funguje
Odpovědět:
Toto jsou běžné otázky Splunk Interview položené během rozhovoru. Data jsou načtena do Splunk pomocí forwarderu, který funguje jako rozhraní mezi prostředím Splunk a okolním světem, pak jsou tato data předána do indexátoru, kde jsou data uložena buď lokálně nebo v cloudu. Indexátor indexuje data stroje a ukládá je na server. Search Head je GUI, které poskytuje Splunk pro vyhledávání a analýzu dat (prohledává, vizualizuje, analyzuje a vykonává různé další funkce) data.
Server nasazení spravuje všechny komponenty Splunk, jako je indexer, forwarder a vyhledávací hlava v prostředí Splunk. 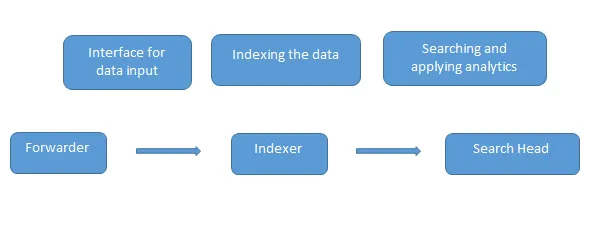
3. Jaká běžná čísla portů používá Splunk?
Odpověď :
Čísla běžných portů, na kterých jsou služby spouštěny (ve výchozím nastavení), jsou:
| Služba | Číslo portu |
| Management / REST API | 8089 |
| Hledejte hlavu / indexátor | 8000 |
| Hledejte hlavu | 8065, 8191 |
| Uzel peer uzlu klastru indexu / Vyhledat člena klastru hlavy | 9887 |
| Indexer | 9997 |
| Indexer / Forwarder | 514 |
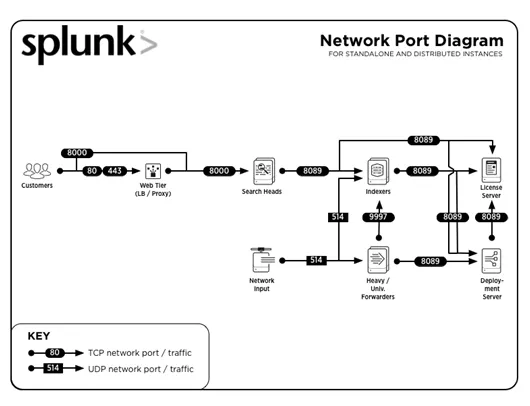
Přejdeme k dalším otázkám na pohovor ve Splunk.
4. Proč používat pouze Splunk?
Odpovědět:
Existuje mnoho alternativ pro Splunk, které dávají hodně konkurence, některé z nich jsou níže:
• ELK / Logstash (open source)
Elasticsearch se používá pro vyhledávání je to jako prohledávací hlava ve Splunk, Log Stash je pro sběr dat, který je podobný předávacímu zařízení používanému ve Splunk, a Kibana se používá pro vizualizaci dat (vyhledávací hlava dělá to samé ve Splunk)
• Graylog (open source s komerční verzí)
Graylog je další nástroj, který byl pojmenován loni s vydáním 1.0. Podobně jako ELK stack má Graylog také různé komponenty, používá Elasticsearch jako svou základní složku, ale data jsou uložena v Mongo DB a používá Apache Kafka. Má dvě verze, jednu základní verzi, která je k dispozici zdarma, a verzi pro podniky, která přichází s funkcemi, jako je archivace.
• Sumo Logic (cloudová služba)
To, co dělá ze Splunk nejlepšího ze všech, je to, že Splunk přichází jako jediný balíček sběrače dat, úložiště a vestavěného analytického nástroje. Splunk je také škálovatelný a poskytuje podporu / odbornou pomoc pro jeho podnikové vydání.
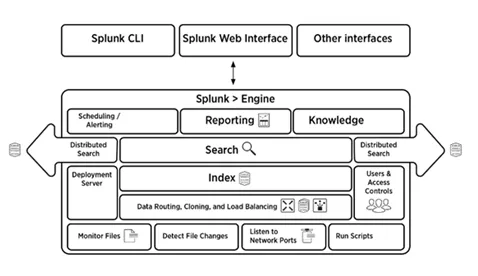
5. Stručně vysvětlete Splunk Architecture
Odpovědět:
Níže uvedený obrázek podává stručný přehled architektury Splunk a jejích komponent.
Část 2 - Splunk rozhovory (pokročilé)
Pojďme se nyní podívat na pokročilé otázky týkající se rozhovoru ve Splunk.
6. Jaké jsou součásti Splunk architektury?
Odpovědět:
V architektuře Splunk jsou čtyři komponenty. Oni jsou:
- Indexer: Indexuje strojová data
- Forwarder: Předá protokoly do indexu
- Prohledávací hlava: Poskytuje GUI pro vyhledávání
- Server rozmístění: Spravuje komponenty Splunk (indexer, forwarder a search head) v distribuovaném prostředí
7. Uveďte několik případů použití objektů znalostí.
Odpověď :
Toto jsou nejčastěji kladené dotazy na pohovor v rozhovoru. Objekty znalostí lze použít v mnoha doménách. Několik příkladů je:
Monitorování aplikací: To lze použít k monitorování aplikací v reálném čase pomocí nakonfigurovaných upozornění, která upozorní administrátory / uživatele v případě havárie aplikace.
Fyzická bezpečnost: V případě povodně / sopky atd. Lze data použít k načtení informací, pokud vaše organizace s takovými daty nakládá.
Zabezpečení sítě: Zabezpečené prostředí můžete vytvořit zatržením IP neznámých zařízení, čímž se sníží úniky dat v jakékoli organizaci.
Správa zaměstnanců: Opotřebení zaměstnanců je jednou z výzev, kterým čelí jakákoli organizace, a během výpovědní doby lze sledovat aktivitu zaměstnance, aby byla chráněna data organizace, čímž se sleduje jejich činnost a omezuje se jakýkoli jiný zaměstnanec ve výpovědní lhůtě, aby nedělal totéž .
8.Vysvětlit vyhledávací faktor (SF) a replikační faktor (RF)
Odpovědět:
Toto jsou terminologie, které se používají v technikách shlukování clusterů. Cluster indexeru je speciálně nakonfigurovaná skupina indexátorů Splunk Enterprise, která replikuje externí data a používá se pro zotavení po havárii.
Pokud jde o hledání dokumentace Splunk, lze tento faktor popsat jako „Počet prohledávatelných kopií dat, které udržuje klastr indexátoru. Výchozí hodnota vyhledávacího faktoru je 2 ”, zatímco replikační faktor je definován jako počet kopií dat, která klastr udržuje.
Klastr indexátoru má vyhledávací faktor i replikační faktor, zatímco klastr vyhledávací hlavy má pouze vyhledávací faktor
Přejdeme k dalším otázkám na pohovor ve Splunk.
9. Co jsou Splunk kbelíky? Vysvětlete životní cyklus kbelíku.
Odpovědět:
Adresáře, ve kterých jsou indexovaná data uložena, se nazývají Splunk buckets a tyto obsahují události určitého období. Životní cyklus kbelíku Splunk zahrnuje čtyři stupně horké, teplé, chladné, zmrazené a rozmrazené.
- Horké - Tento segment obsahuje nedávno indexovaná data a je otevřen pro zápis.
- Teplý - Poté, co data spadnou do horkých kbelíků, v závislosti na vašich datových zásadách se přesune do teplých kbelíků
- Studená - Další fází po zahřátí je studená fáze, ve které nelze data upravovat.
- Frozen - Ve výchozím nastavení indexer odstraní data ze zmrazených kbelíků, ale lze je také archivovat.
- Thawed - získávání informací z archivovaných souborů (zmrazené vědro) se nazývá tání.
10. Proč bychom měli používat funkci Splunk Alert? Jaké jsou různé možnosti při nastavování upozornění?
Odpovědět:
Stav pozornosti na jakoukoli možnou chybu je známý jako výstraha a ve Splunk může dojít k výstrahám prostředí v důsledku selhání připojení nebo narušení zabezpečení nebo porušení jakýchkoli uživatelem vytvořených pravidel.
Například odesílání oznámení nebo zprávy uživatelů, kteří se nepřihlásili po využití svých tří pokusů v portálu, správci aplikace.
Při nastavování upozornění jsou k dispozici různé možnosti:
- Může být vytvořen webhook pro psaní upozornění na hipchat nebo GitHub.
- Přidejte výsledky, .csv nebo pdf nebo v souladu s tělem zprávy, aby bylo možné zjistit hlavní příčinu výstrahy.
- Lze vytvářet lístky a upozornění lze škrtit ze stroje nebo IP.
Doporučený článek
Toto byl průvodce seznamem zodpovězených dotazů a odpovědí na pohovor, aby mohl kandidát tyto zázrakové dotazy a odpovědi snadno pronásledovat. Další informace naleznete také v následujících článcích -
- Otázky systému Interview systému SAS - Top 10 užitečných otázek
- 10 výborných otázek na rozhovor s Tableau, které musíte znát
- 15 nejúspěšnějších otázek a odpovědí na rozhovor Oracle
- Otázky týkající se zabezpečení sítě - nejvyšší a nejčastější dotazy
- Splunk vs Nagios