
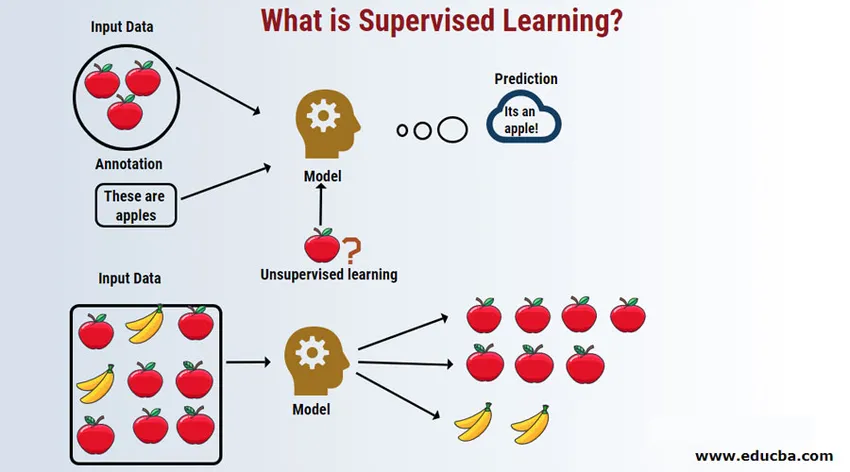
Úvod do učení pod dohledem
Supervised Learning je oblast strojového učení, kde pracujeme na předpovídání hodnot pomocí označených datových sad. Označené vstupní datové sady se nazývají nezávislá proměnná, zatímco předpokládané výsledky se nazývají závislou proměnnou, protože pro své výsledky závisí na nezávislé proměnné. Například my všichni máme v našem e-mailovém účtu (např. Gmail) složku se spamem, která automaticky detekuje většinu e-mailů se spamem / podvodem s přesností vyšší než 95%. Funguje to na základě kontrolovaného modelu učení, kde máme tréninkovou sadu označených dat, což je v tomto případě označený spamový e-mail označený uživateli. Tyto tréninkové sady se používají k učení, které se později použije pro kategorizaci nových e-mailů jako spam, pokud se hodí do dané kategorie.
Práce na strojovém učení pod dohledem
Podívejme se na pochopení strojového učení pod dohledem pomocí příkladu. Řekněme, že máme košík s ovocem, který je plný různých druhů ovoce. Naším úkolem je kategorizovat ovoce podle jejich kategorie.
V našem případě jsme uvažovali o čtyřech druzích ovoce, a to jablek, banánů, hroznů a pomerančů.
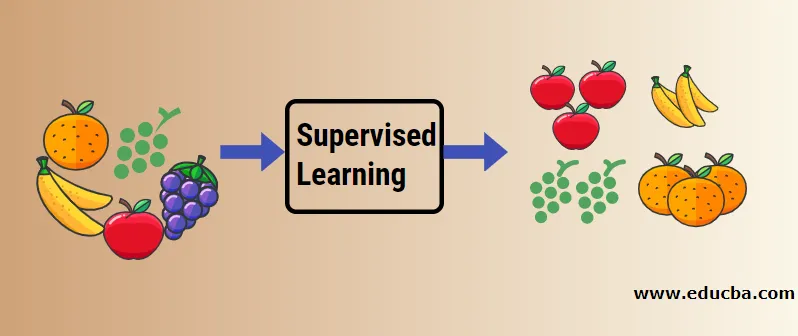
Nyní se pokusíme zmínit některé jedinečné vlastnosti těchto plodů, díky nimž jsou jedinečné.
|
S No. | Velikost | Barva | Tvar |
Jméno |
|
1 | Malý | Zelený | Kulatý až oválný tvar parta válcovitý |
Hroznový |
|
2 | Velký | Červené | Zaoblený tvar s prohlubní v horní části |
Jablko |
|
3 | Velký | Žlutá | Dlouhý zakřivený válec |
Banán |
| 4 | Velký | oranžový | Zaoblený tvar |
oranžový |
Nyní řekněme, že jste si vybrali ovoce z ovocného koše, podívali jste se na jeho vlastnosti, například na jeho tvar, velikost a barvu, a pak usuzujete, že barva tohoto ovoce je červená, velikost, pokud je velká, tvar je zaoblený tvar s prohlubní v horní části, proto je to jablko.
- Stejně tak uděláte totéž pro všechny ostatní zbývající ovoce.
- Sloupec zcela vpravo („Název ovoce“) je známý jako proměnná odezvy.
- Takto formulujeme supervizovaný model učení, nyní bude pro každého nového (řekněme robot nebo mimozemšťan) docela snadné s danými vlastnostmi snadno seskupovat stejný druh ovoce dohromady.
Typy kontrolovaného algoritmu strojového učení
Podívejme se na různé typy algoritmů strojového učení:
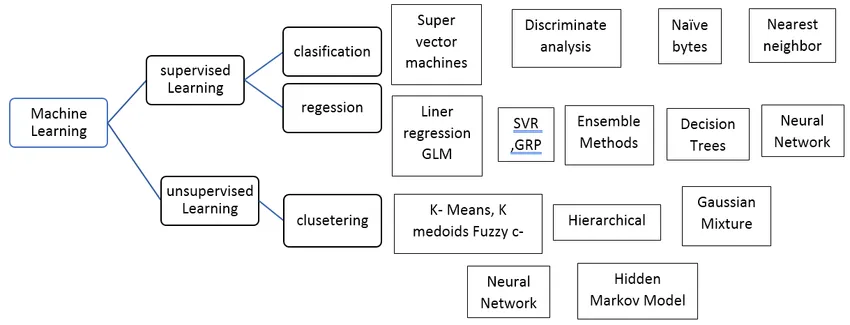
Regrese:
Regrese se používá k predikci výstupu jedné hodnoty pomocí sady tréninkových dat. Výstupní hodnota se vždy nazývá závislá proměnná, zatímco vstupy se nazývají nezávislá proměnná. Máme různé typy regrese v supervidovaném učení, například,
- Lineární regrese - Zde máme pouze jednu nezávislou proměnnou, která se používá k predikci výstupu, tj. Závislé proměnné.
- Multiple Regression - Zde máme více než jednu nezávislou proměnnou, která se používá k predikci výstupu, tj. Závislé proměnné.
- Polynomiální regrese - Graf mezi závislými a nezávislými proměnnými sleduje polynomiální funkci. Například zprvu vzrůstá paměť s věkem, pak v určitém věku dosáhne prahu a poté, jak stárneme, začne klesat.
Klasifikace:
Klasifikace dohlížených algoritmů učení se používá k seskupení podobných objektů do jedinečných tříd.
- Binární klasifikace - Pokud se algoritmus pokouší seskupit 2 odlišné skupiny tříd, nazývá se binární klasifikace.
- Klasifikace více tříd - Pokud se algoritmus snaží seskupit objekty do více než 2 skupin, nazývá se klasifikace více tříd.
- Síla - Klasifikační algoritmy obvykle fungují velmi dobře.
- Nevýhody - náchylný k nadměrnému vybavení a může být neomezený. Například - klasifikátor spamového e-mailu
- Logistická regrese / klasifikace - Pokud je proměnná Y binární kategoriální (tj. 0 nebo 1), použijeme pro predikci logickou regresi. Například - předpovídání, zda je daná transakce kreditní kartou podvodem nebo ne.
- Klasifikátory naivní Bayes - Klasifikátor Naïve Bayes je založen na bayesovské větě. Tento algoritmus se obvykle nejlépe hodí, je-li rozměrnost vstupů vysoká. Skládá se z acyklických grafů, které mají jednoho rodiče a mnoho dětských uzlů. Podřízené uzly jsou na sobě nezávislé.
- Rozhodovací stromy - Rozhodovací strom je stromová struktura podobná struktuře, která se skládá z interního uzlu (test na atributu), větve, která označuje výsledek testu, a listových uzlů, které představují distribuci tříd. Kořenový uzel je nejvyšší uzel. Je to velmi široce používaná technika, která se používá pro klasifikaci.
- Podpůrný vektorový stroj - Podpůrný vektorový stroj je nebo SVM provádí klasifikaci tím, že najde hyperplán, který by měl maximalizovat rozpětí mezi 2 třídami. Tyto stroje SVM jsou připojeny k funkcím jádra. Pole, ve kterých se široce využívají SVM, jsou biometrie, rozpoznávání vzorů atd.
Výhody
Níže jsou uvedeny některé z výhod modelů strojového učení pod dohledem:
- Výkon modelů lze optimalizovat na základě zkušeností uživatelů.
- Kontrolované učení vytváří výstupy s využitím předchozích zkušeností a také vám umožňuje shromažďovat data.
- Pro implementaci řady skutečných problémů lze použít supervidované algoritmy strojového učení.
Nevýhody
Nevýhody supervidovaného učení jsou následující:
- Úsilí trénovat modely strojového učení pod dohledem může trvat hodně času, pokud je datový soubor větší.
- Klasifikace velkých dat někdy představuje větší výzvu.
- Možná se bude muset vypořádat s problémy s přebytkem.
- Potřebujeme spoustu dobrých příkladů, pokud chceme, aby model fungoval dobře, zatímco trénujeme klasifikátor.
Osvědčené postupy při vytváření modelů učení
Je to dobrý postup při vytváření modelů pod dohledem učeného stroje: -
- Před vytvořením jakéhokoli dobrého modelu strojového učení musí být proveden proces předzpracování dat.
- Jeden musí rozhodnout o algoritmu, který by měl být pro daný problém nejvhodnější.
- Musíme se rozhodnout, jaký typ dat bude použit pro tréninkovou sadu.
- Musí se rozhodnout o struktuře algoritmu a funkce.
Závěr
V našem článku jsme se dozvěděli, co je učení pod dohledem, a viděli jsme, že zde trénujeme model pomocí označených dat. Pak jsme šli do práce modelů a jejich různých typů. Nakonec jsme viděli výhody a nevýhody těchto supervidovaných algoritmů strojového učení.
Doporučené články
Toto je průvodce, co je učení pod dohledem? Zde diskutujeme pojmy, jak to funguje, typy, výhody a nevýhody supervidovaného učení. Další informace naleznete také v dalších navrhovaných článcích -
- Co je hluboké učení
- Dozorované učení vs Hluboké učení
- Co je synchronizace v jazyce Java?
- Co je to webhosting?
- Způsoby, jak vytvořit rozhodovací strom s výhodami
- Polynomiální regrese Použití a funkce